
[Paper] Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
Abstract
지금까지 anchor-based detector가 지배적이었지만 최근 anchor-free detection 방법이 FPN과 Focal Loss 덕분에 많아지고 있다
본 논문에선 이 두 방법의 중요한 차이점을 찾아낸다 차이점: 어떻게 positive 와 negative sample을 정의하는지 +이 차이점이 얼마나 중요한지 보여준다
새로운 Adaptive Training Sample Selection 방법을 소개한다
- 통계적 특성을 통해 자동적으로 positive와 negative를 선택하는 방법
마지막으로 하나의 위치에 여러개의 anchor를 쌓는 방법의 필요성에 대해 다룬다
Introduction
object detection 모델은 크게 one-stage model, two-stage model로 나뉜다. 대부분의 two-stage 방법들이 one-stage 보다 anchor를 여러번 refine하기 때문에 좋은 성능을 보여준다
최근의 방법들은 FPN,Focal loss 덕분에 anchor-free 방법을 많이 사용한다
two-stage detector: Faster R-CNN one-stage detector: RetinaNet anchor-based detector: RetinaNet anchor-free detector: FCOS
main contribution
-
anchor-based 방법과 anchor-free 방법의 차이점 essential differences: positive, negative sample의 정의
-
Adaptive Training Sample Selection(ATSS) 객체 특성에 의해 자동적으로 positive 와 negative sample 선택
-
여러개의 anchor를 하나의 location에 쌓는게 필요 없다는것을 증명
Related work
Anchor-based detector
Two-stage method
Faster R-CNN 논문의 성능이 좋았다(RPN + R-CNN) 이후 많은 알고리즘이 성능을 높이기 위해 Faster R-CNN에 대해 많은 연구가 있었다.
- architecture redesign & reform
- context and attention mechanism
- multi-scale training and testing
SOTA는 대부분 two-stage가 가지고 있다.
One-stage method
SSD가 나오고 나서 높은 계산 효율성 때문에 주목받음 이후 SSD의 성능을 올리기 위한 많은 연구들이 나왔음
- fusing context information from different layers
- training from scratch
- new loss function
이러한 방법들로 인해 two-stage와 매우 유사한 결과 가지게 되었고, 빠른 inference 속도를 가짐
Anchor-free detector
keypoint-based method
pre-defined or self-learned keypoint를 먼저 locate하고, 이후에 bbox를 생성한다
ex) CornerNet은 object bbox를 keypoint의 쌍으로 구현
다른 방법들도 있는데 논문에서는 여기만 나오고 더 안나온다.
Center-based method
물체의 중심을 가지고 positive 와 negative를 정의한 뒤 detection을 위해 positive에서 물체 bbox의 4개의 측면까지의 거리를 예측
ex)FCOS
Difference Analysis of Anchor-based and Anchor-free Detection
RetinaNet(anchor-based) vs. FCOS(anchor-free) 방법을 비교
- positive/negative sample definition
- regression starting status
이 두가지를 중점으로 비교를 하는데, 두 방법의 마지막 남은 차이점은 location 당 쌓인 anchor 수이다. 때문에 비교를 위해 RetinaNet에서 하나의 location 당 하나의 anchor box만을 사용한다.
Experiment setting
Dataset
- MS COCO 80 class
- training: trainval135k’s 115k images
- validation for analysis: minival split’s 5k images
Training detail
- Imagenet for train Resnet-50 with 5-level feature pyramid
- RetinaNet: 5개의 FPN 레벨을 하나의 8S 스케일을 가진 image로 합친다.
- S: stride size
- 800 x 1333
- SGD algorithm for 90k iteration with 0.9 momentum, 0.0001 weight decay
- 16 batch size
learning rate
- initial 0.01, decay by 0.1 at iteration 60k and 80k
Inference detail
- resize the input image in the same way as in the training phase
- preset score 0.05, output top 1000 detections per feature pyramid
- NMS. IoU threshold 0.6, top 100 confident detections per image
Inconsistency removal

기존의 FCOS는 AP가 37.1%까지 나왔으나, 추가적인 방법들로 37.8%까지 올라갔음.
RetinaNet은 FCOS와 비교했을때는 37.1 vs 32.5로 차이가 많이 나지만, FCOS에 적용했던 방법들은 전부 RetinaNet(#A=1)에 적용 가능 때문에 전부 적용했을때는 37.0 vs 37.8로 큰 차이가 나지 않고, 이러한 실험 결과 때문에 anchor-based, anchor-free 방식의 차이점으로 보지 않는다.
이러한 불필요한 점을 제거하고 본질적인 차이점 비교
Essential Differences
남은 2가지의 차이점
- define positive and negative
- regression starting from an anchor box or an anchor point
Classification
RetinaNet은 positive와 negative 구분하기 위해 IoU 사용 일정 범위 이내의 ioU를 가져오고, 나머지는 training시 제외된다
FCOS는 spatial, scale constraints를 사용 positive sample을 각 pyramid level에서 정의된 scale range를 기반으로 정의하여 선별한다
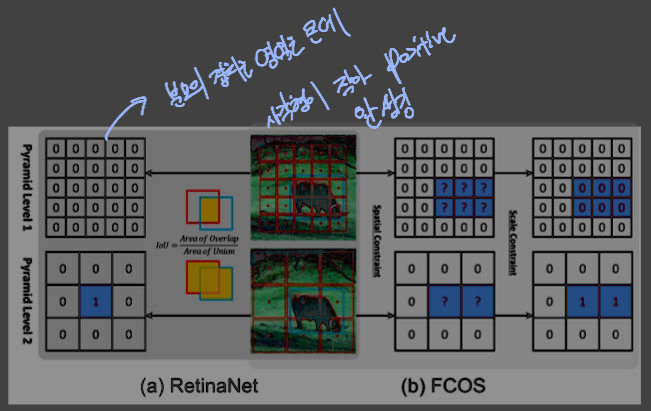
서로 다른 방법을 사용하는데, 이를 바꿔가며 실험

FCOS의 방법을 RetinaNet에 적용: 37.0% -> 37.8% 증가 RetinaNet의 방법을 FCOS에 적용: 37.8% -> 37.0% 감소
결과가 달라짐을 볼 때 positive, negative를 정의하는 것이 비교하고 있는 두 방식에서 차이가 있음을 의미한다
Regression
positive와 negative sample이 정해지고 나면, 물체의 위치가 positive sample로 부터 예측된다
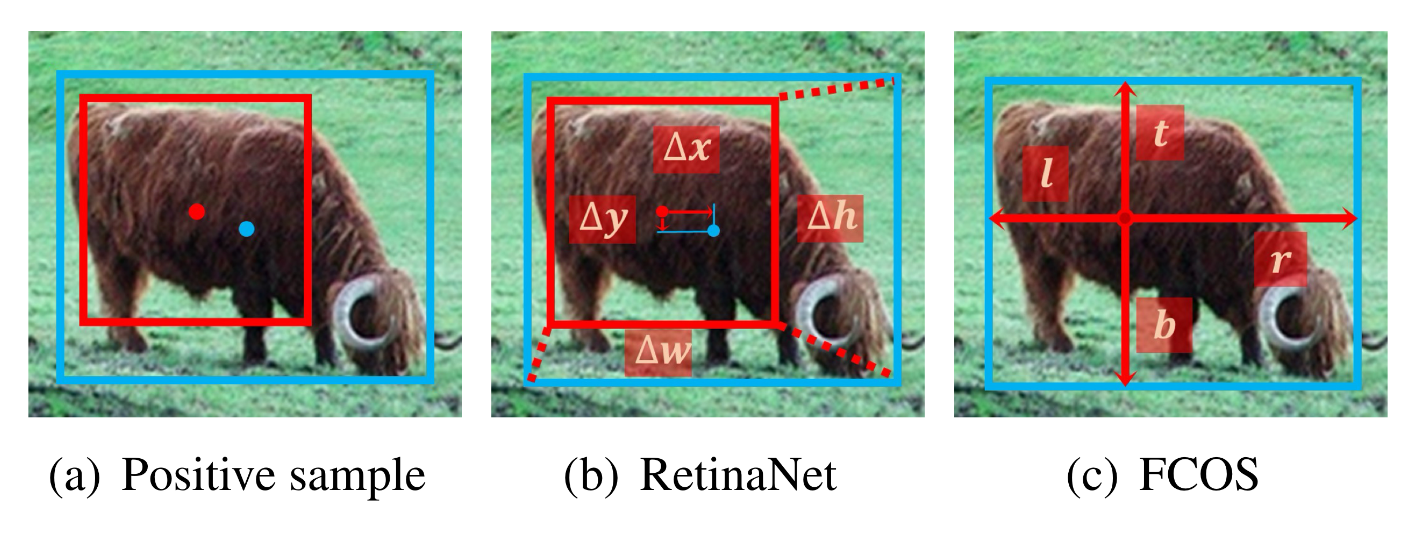
RetinaNet -> box에서 regression 시작 FCSO -> point에서 regression 시작
하지만 표에서 보듯이 regressoin 방법을 바꾸어도 큰 성능의 차이가 없음 -> 불필요한 차이
Conclusion
가장 중요한 차이점은 positive/negative sample 정의하는 방법
Adaptive Training Sample Selection(ATSS)
positive와 negative를 어떻게 정의하냐가 anchor-based 와 anchor-free 방법의 중요한 차이점이라면, 어떻게 정의해야 좋을까?
본 논문에서는 ATSS라는 새로운 방법 제시 이 방법은 다른 세팅에 대해 robust하고 hyperparameter가 없다(한개)

이전 방법들은 IoU threshold 나 scale range 같은 민감한 hyperparameter 들이 많았다 이런 hyperparameter들을 다 정하면 모든 gt box들은 positive sample을 정해진 규칙으로 선별해야 하는데, 이때 예외가 있는 물체들은 무시된다.
때문에 다른 hyperparameter에 대해 다른 결과를 가져오게 된다
Algorithm
- 모든 gt에 대해 빈 candidate set을 먼저 생성
- 모든 pyramid level에 대해서 각각의 level마다 L2 distance를 계산하여 k개의 anchor를 뽑아낸다
- 뽑아낸 candidate와 gt의 ioU를 계산하여 D에 저장
- D의 평균(m)과 표준편차(v)를 각각 계산
- IoU threshold를 평균과 표준편차를 더하여 계산
- 만약 IoU가 새로 구한 threshold보다 높고, center c가 gt 안에 있으면 positive sample로 설정
- 나머지는 negative로 설정
Reasons
- candidate를 anchor box와 object 사이의 거리를 기반으로 고르는 이유
- 두 방법 다 object의 중심이 가까울 때 좋은 결과가 나오기 때문
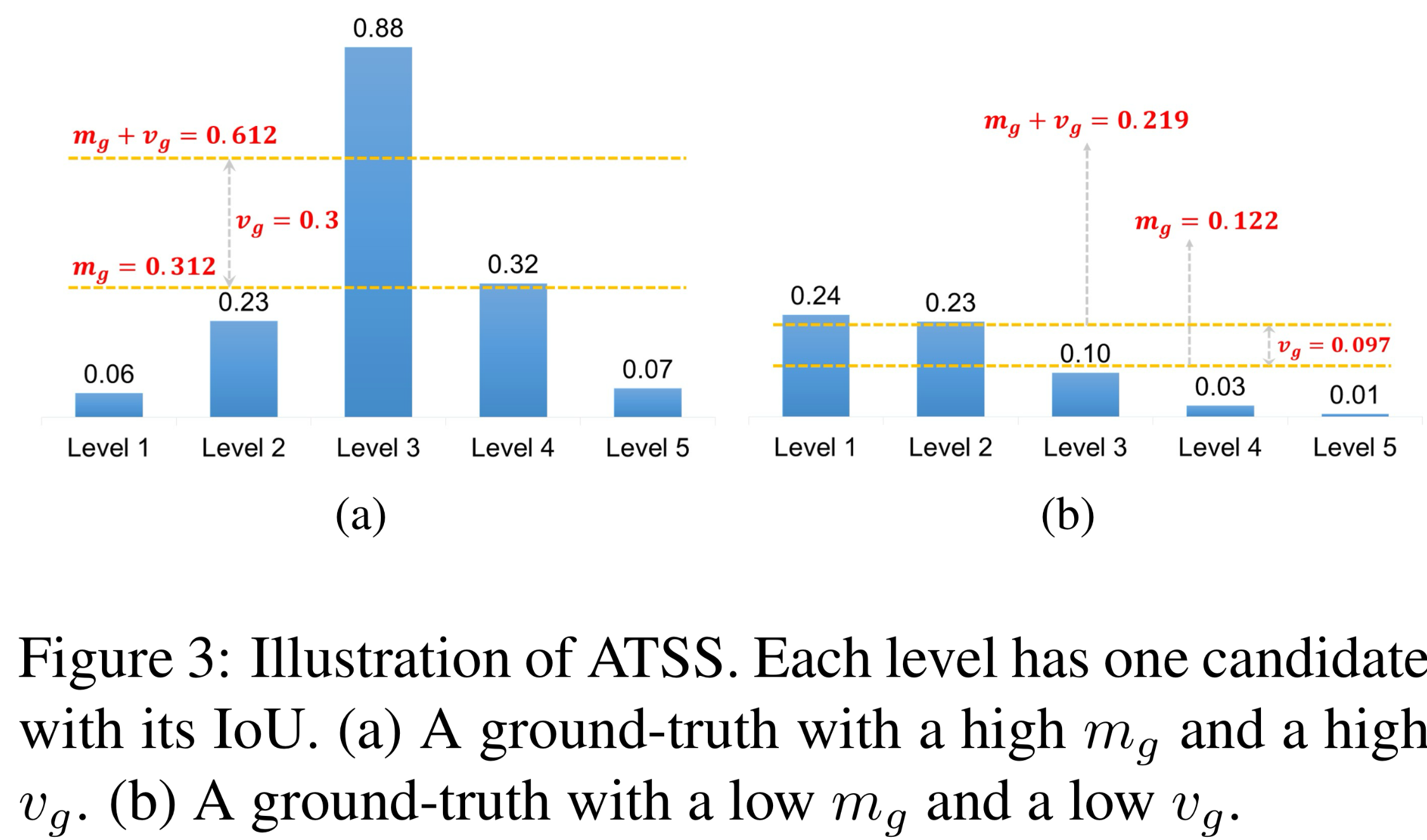
- IoU threshold 계산에 평균과 표준편차 사용하는 이유
- 평균: preset anchor가 현재 객체에 알맞은지의 척도
- 고품질 candidate -> IoU 임계값이 높아야 pos/neg 구분 가능
- 표준편차: 어떠한 layer가 object를 탐지하기에 알맞은지의 척도
- 표준편차가 높다면 어울리는 pyramid level이 특정지어짐
- 표준편차가 낮다면 객체에 적합한 피라미드 레벨이 여럿 있음을 나타냄(b를 보면 대부분이 품질이 좋지 않기 때문에 낮은 vg )
- 여기에 mg를 추가하면 적절한 positive를 선택하기 위한 낮은 임계값을 얻게 된다
- 객체에 대해 충분히 positive를 adaptive하게 선택할 수 있도록 평균 과 표준편차의 합을 threshold로 사용
- positive의 center를 gt 안에 있는거로 선택하는 이유
- center가 밖으로 나가면 좋지 않은 training이 진행되고, 결과 또한 좋지 못하다
- 학습시 positive가 아닌 feature를 사용하기 때문
- Maintaining fairness between different object
- 통계적인 결과로 20% 정도를 positive sample로 설정하게 된다.
- FCOS,RetinaNet을 이와 비교했을 떄 훨씬 많은 positive가 생겨나게 되고 이는 다른 객체에 대해 불공정함을 가져온다
- Keeping almost hyperparameter free
- k 하나의 hyperparameter를 사용하는데, 실험을 보았을 떄 j에 크게 영향을 받지 않는다.
- 그래서 ATSS는 robust한 hyperparameter 한개를 가지고 있기 때문에 거의 hyperparameter-free라고 한다
Experiment
Verification
Anchor-based RetinaNet
ATSS 를 검증하기 위해 RetinaNet에 적용
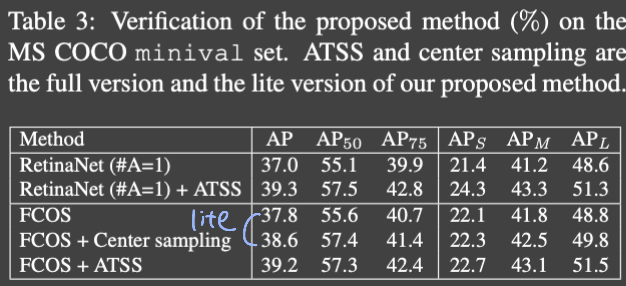
전체적으로 성능이 올라갔다 본 논문의 method는 추가적인 overhead 없이 향상된 것이기 때문에, cost-free라고 할 수 있다
Anchor-free FCOS
lite와 full version 두개로 나누어 적용
lite version
- candidate positive를 고르는 방법만 교체
- FCOS는 anchor point를 다루는데, 이는 많은 low-quality positive를 만들게 된다(anchor box보다 anchor point가 작고, 겹치는 부분이 많지 않으니까)
- 이를 FCOS에 center sampling을 적용하는 방법으로 적용
Full version
- FCOS의 anchor point를 8S의 scale로 만들어 anchor box가 되도록 하였다
코드 봐야 이해될듯
Analysis
본 논문의 방법을 사용하였을 때, anchor box 관련된 hyperparameter는 k만 사용하였다
Hyperparameter k
다른 k에 대해서 실험

너무 큰 k는 low-quality candidate를 가져오게 되어 살짝 성능이 감소하였다
너무 작은 k는 너무 적은 positive로 인해 통계적으로 불안정하게 되어 성능이 감소하였다 (ATSS의 positive 비율은 16~20%. 이게 적어졌다는 뜻)
전체적으로 k는 꽤나 robust하고 ATSS는 거의 hyperparameter-free 라고 할 수 있다
Anchor size
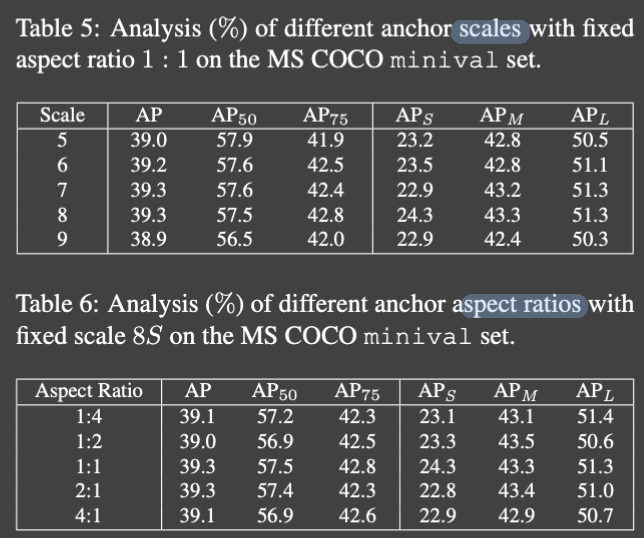
각기 다른 scale에 대해 상당히 안정적
8S anchor box의 다양한 aspect ratio로 여러 실험 수행 이에 대해서도 민감하지 않다
결과적으로 제안된 방법이 다양한 anchor setting에 robust
Comparision
FCOS에서 43.2 -> 45.6 DCN 사용했을 떄 45.6 -> 47.7 MST 사용했을 때 47.7 -> 50.7
DIscussion
RetinaNet에서 location 당 anchor box를 한개 썼었는데, 이를 9개에 대해서도 실험
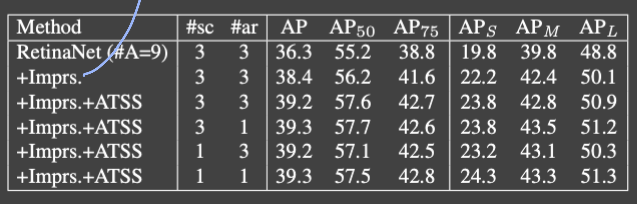
결과를 보면 improvement 적용했을때 성능 향상, ATSS 썼을 때 추가적인 성능 향상을 보여주지만 다른 anchor box 설정에 대해서는 robust함을 보여주고 있다. 때문에 굳이 연산량이 많은 여러개의 anchor box를 사용할 필요가 없다