
[Paper] Learning A Coarse-to-Fine Diffusion Transformer for Image Restoration
Abstract
이미지 복원의 경우 diffusion기반 방법은 정확하지 않은 노이즈 추정으로 인해 좋은 결과를 만들어내지 못할 수 있다.
또한 단순한 constraining(제약) 노이즈는 복잡한 열화 정보를 효과적으로 학습할 수 없어 모델 용량에 좋지 않은 영향을 끼친다.
이러한 문제를 해결하기 위해 이미지 복원을 위한 Coarse-to-fine diffusion Transformer(C2F-DFT)를 제안한다.
C2F-DFT는 새로운 coarse to fine 훈련체계 내에 diffusion self attention과 diffusion feed-forward network를 포함한다.
더 나은 복원을 위해 DFSA와 DFN은 각각 장거리 diffusion 의존성을 캡쳐하고 계층 diffusion representaiton을 학습한다.
coarse 훈련 단계에서, C2F-DFT는 노이즈를 추정한 다음 샘플링 알고리즘에 의해 꺠끗한 이미지를 생성한다.
복원 품질을 향상시키기 위해, 간단하고 효과적인 fine 훈련 체계를 제안한다. 먼저 고정된 단계로 coarse하게 훈련된 diffusion모델을 사용하여 복원 결과를 생성한 다음, 해당 ground truth결과로 제한해 모델을 최적화 하여 부정확한 노이즈 추정의 영향을 받는 불만족스러운 결과를 해결한다.
Introduction
최근 diffusion 모델은 다양한 vision task에서 강력한 생성 기능과 좋은 성능으로 주목받고 있다. CNN 및 Transformer와 같은 심층 모델의 선명한 이미지를 직접 추정하는 방식과 달리 diffusion기반 복원 모델은 forward diffusion 과정에서 생성된 노이즈 이미지에서 꺠끗한 이미지를 점진적으로 복구한다.
그러나 이러한 방법은 종종 노이즈를 제한하여 훈련된 후 샘플링 알고리즘에 의해 최종 꺠끗한 이미지를 직접 획득한다. 이러한 훈련 접근 방식은 간단한 노이즈 추정으로 인해 모델 용량을 제한하며, 이는 샘플링 복원 품질에 후속적으로 영향을 미치는 부정확성이 발생할 수 있다.
이러한 문제를 해결하기 위해 이미지 복원을 위한 새로운 C2F 훈련 체계를 갖는 Diffusion Transformer인 C2F-DFT를 제안한다. 특히 이는 DFSA와 DFN에 시간 단계가 포함된 diffusion transformer 블록과 diffusion feed-forward network가 포함된 네트워크로 구축되어 있으며, 시간 단계는 DFSA와 DFN에 포함되어 있어 장기 diffusion 의존성을 포착하고 계층적 diffusion기능을 학습하여 더 나은 복원을 용이하게 한다.
샘플링 과정에서 복원 품질에 대한 노이즈의 부정확한 추정을 해결하기 위해, 본 논문에서는 coarse to fine 훈련체계를 제안한다. 이는 coarse훈련과 fine 훈련을 포함한다.
- coarse training
- 노이즈를 제한하여 diffusion transformer를 훈련시키는 것으로, 이는 샘플링 알고리즘에 의해 최종 복원 이미지를 얻기 위해 활용된다.
- fine training
- 샘플링된 복원 이미지를 노이즈 대신 해당하는 실제 이미지로 제한하여 DFT를 더욱 최적화한다. 이를 통해 부정확한 노이즈 추정으로 인해 만족스럽지 않은 결과가 나오는 것을 방지한다.
Key ideas
- 이미지 복원을 위한 diffusion transformer제안. transformer에 diffusion을 내장하여 장거리 의존성을 모델링 할 뿐만 아니라 diffusion모델의 생성 능력을 활용하여 더 나은 이미지 복원을 용이하게 한다.
- coarse training에서 diffusion모델의 부정확한 노이즈 추정에 영향을 받는 복원 품질을 향상시키고, fine training을 통해 모델 용량을 더욱 확장할 수 있다.
Method
Diffusion Transformer Model
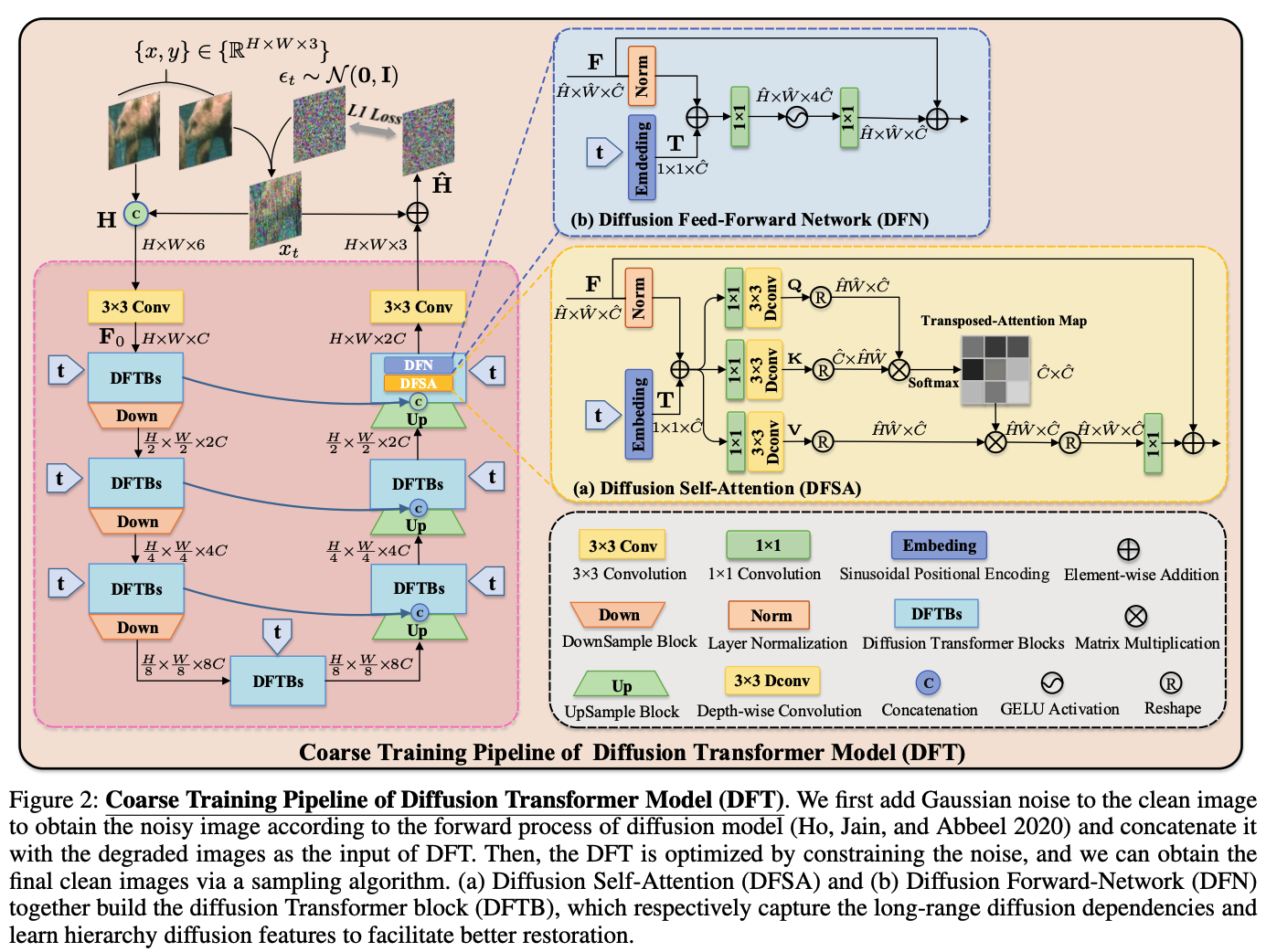
그림은 DFTB를 가진 4단계 U자형 구조인 DFT의 전체적인 모습을 보여준다. DFTB는 각각 DFSA와 DFN으로 구성된다.
Overall Pipeline

DIffusion Self-Attention
본 논문의 DFSA는 장거리 확산 의존성(long-range diffusion dependencies)을 모델링하는 것을 목표로 한다. diffusion 모델의 시간 단계 t가 주어지면, sinusoidal positional encoding(정현파 위치 인코딩)을 사용하여 t를 벡터 임베딩 T(1 x 1 x C)로 인코딩한다.
이후 입력 feature F에 T를 임베딩하여 self attention을 수행한다.

Diffusion Feed-Forward Network
본 논문의 DFN은 hierarchy diffusion representation을 학습하는 것을 목표로한다. DFSA의 출력 feature F를 처리하기 위해 2개의 1x1 point-wise conv와 시간 단계 임베딩 T를 활용한다.
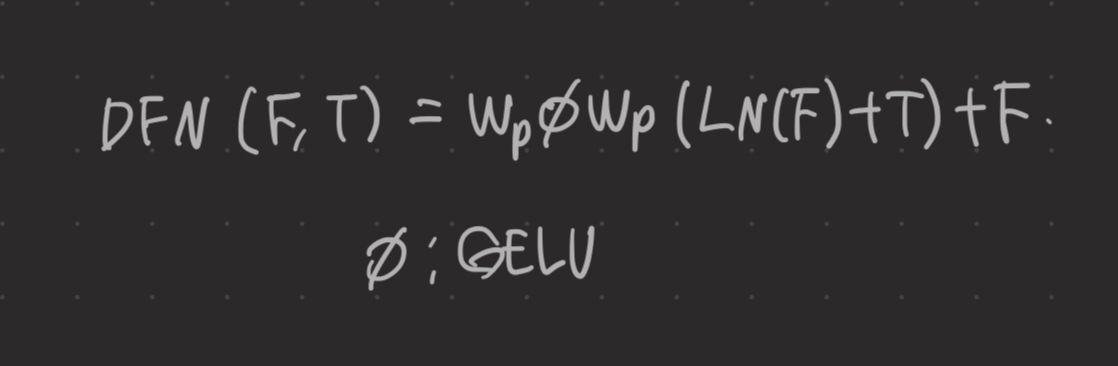
Coarse-to-Fine Training Pipeline for Restoration
coarse training과 fine training으로 나뉜다.
coarse training은 노이즈를 제한하여 diffusion transformer를 훈련하는 것을 목표로 하며, 이는 샘플링 알고리즘에 의해 최종 복원된 이미지를 얻기 위해 활용된다.
fine training은 더 나은 복원을 위해 모델 용량을 확장하기 위해 coarse training의 고정된 단계와 대응하는 ground truth 단계로 샘플링된 깨끗한 이미지를 제한함으로써 diffusion transformer를 최적화한다.
Coarse Training
노이즈 εt를 추정하는 기존의 conditional diffusion model 과 유사하다.
loss function은 다음과 같다.

추정된 노이즈를 활용하여 샘플링 알고리즘을 통해 깨끗한 이미지를 생성할 수 있다.
Fine Training
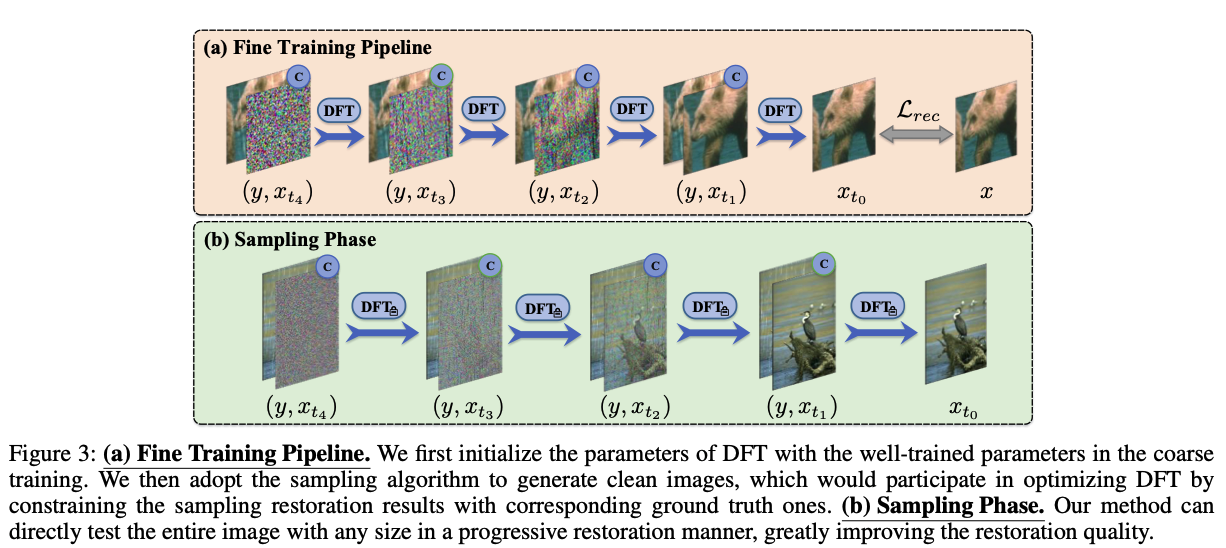
coarse training 후, 그림과 같이 4단계 샘플링이 PSNR/SSIM 측면에서 최고의 복원 품질에 도달한다는 것을 확인한다.
그러나 coarse training은 주로 노이즈를 제한하는 데에 초점을 맞추고 있기 때문에 부정확한 잡음 추정은 복원 품질에 영향을 끼칠 수 있다.
때문에, 본 논문에서는 노이즈 대신 고정된 샘플링 단계로 샘플링된 복원 결과를 제한함으로써 모델을 더욱 최적화하는 fine training을 제안한다.
fine training단계는 coarse training과 데이터 처리는 동일하지만 제한된 객체가 다르다.
먼저 coarse training의 잘 훈련된 매개변수로 DFT의 매개변수를 초기화한다. 이후 복원 결과를 생성하기 위해 4단계로 샘플링 알고리즘을 통합한다. 마지막으로, coarse training의 불만족스러운 결과를 해결하기 위해 노이즈를 제한하는 대신 L1 loss와 SSIM loss를 사용하여 생성된 샘플링 복원 영상을 해당 ground truth영상으로 제한함으로써 DFT를 최적화한다.

이러한 방법은 모델 용량을 향상시킬 수 있고 향후 Diffusion 기반 영상 복원 모델에서 복원 작업을 발전시킬 수 있는 가능성을 가지고 있다.
Sampling Algorithm

샘플링 단계에서는 implicit sampling 전략을 사용하여 샘플링 과정을 빠르게 처리한다.
C2F-DFT 내에서 샘플링 하는 절차는 위의 수식에 요약되어 있다.
fine training을 사용하여 노이즈를 제한하는 대신 해당하는 실제 복원 결과로 샘플링된 복원 결과를 제한하여 DFT를 훈련시킬 떄 이러한 발전은 샘플의 품질을 크게 향상시킨다.
Patch-Cycle Diffusion Learning Strategy
diffusion 과정을 학습하기 위해 고정 패치에 의존하는 기존 diffusion모델과는 달리, 패치 사이클 diffusion 학습 전략을 도입하여 diffusion모델이 더 나은 복원을 위해 더 많은 맥락 정보를 캡처할 수 있도록 한다.
실험에서 p = {32,64,128}중 선택된 {x_p,y_p}개의 clean-degraded 이미지 쌍에서 p x p 패치를 추출한다.
훈련단계 동안, {x_p,y_p}를 (훈련을)N번 반복할 때 마다 C2F-DFT에 주기적으로 넣어 완료될 때까지 이 방법을 계속한다.
훈련 비용을 관리하기 위해 p가 증가함에 따라 패치 크기를 줄인다.