
[Paper] Conditional Random Fields as Recurrent Neural Network
ICCV 2015
Abstract
pixel-level labelling: semantic segmentation 같은 task 하지만 시각적 객체를 구분하는데 있어 딥러닝 기술이 제한적
이를 해결하기 위해 CNN과 CRF의 장점을 합친 새로운 cnn 구조 제안
CRF의 구성요소를 CNN으로 전부 대체 -> 전체 네트워크를 end-to-end로 학습 가능 CRF의 Gaussian pairwise potential과 mean-field approximate를 RNN으로 구현
Introduction
pixel level labelling에 feature representation이 중요하기는 하지만 정확한 결과를 얻기 위해서는 공간적 일관성, 이미지의 경계, 외관의 일관성과 같은 요소를 고려하는것도 중요
CNN 사용 -> 휴리스틱 parameter tuning을 사용한 feature와 달리, pixel level labelling을 위해 강력한 feature representation을 끝까지 학습하는것 이를 통해 상당한 정확도 향상을 보여주었음
하지만 단점들도 있음
-
큰 receptive의 convolution filter를 가지고 있음 -> 픽셀 수준 labeling을 할 때 coarse한 출력을 만들어냄(receptive field가 크기 떄문에 섬세하지 않은 pixel level classification) 이러한 단점은 maxpooling에 의해 더욱 큰 오차 생성
-
유사한 픽셀 간의 label agreement를 돕는 smoothness ternm이 존재하지 않음 공간적 및 외형적 일관성 부족 이러한 smoothness constraint가 없기 때문에 좋은 결과를 내지 못함
probabilistic graphic model은 pixel level labelling의 정확도를 향상시키기 위해 효과적인 방법으로 개발되었다
예로 MRF 와 CRF가 나왔고, 좋은 성능을 보여주었다
- CRF 유사한 pixel 간의 label agreement와 같은 가정을 포함하는 probabilistic inference 문제로 라벨 할당 문제를 구성 약하고 coarse한 prediction을 정제하여 선명한 경계와 정확한 segmentation을 예측 가능
CNN에 CRF 를 사용할 수 있는 하나의 방법으로는 CNN의 train과 분리된 post processing 단계로 CRF inference를 적용하는 방법이 있다 하지만 이는 network와 완전히 통합된 방법이 아니기 때문에 CRF에 맞춰 가중치를 조정할 수 없다
Main contribution
- CNN으로 생성된 semantic segmentation 문제를 위한 end-to-end 방식 제안
- CNN과 CRF 기반 graphic model의 장점을 하나의 framework 안에서 결합
- gaussian pairwise potential 을 가진 CRF의 mean field inference를 RNN으로 구성
Related work
segmentation을 위해 딥러닝과 CNN을 사용하는 접근 방식을 검토
- feature extraction과 image의 edge를 활용한 별도의 메커니즘 사용
- 대표적으로 CNN을 사용하여 의미있는 feature를 추출하고 이미지의 pattern을 고려하기 위해 superpixel 사용하는 방법
- 이미지에서 super pixel을 먼저 얻은 다음 각각에 대해 feature extractio을 적용
단점
- 초기 제안 오류가 얼마나 좋은가에 상관 없이 나쁜 예측을 만들 가능성이 있다
- nonlinear model을 직접 학습
- 상위 계층이 객체 인식에 대한 의미있는 특성 얻음
- 하위 계층은 이미지의 구조에 대한 정보 얻음
- 대부분 CNN 훈련과 분리된 독립적인 post processing으로 사용
- deep neural network와 markov network를 결합하는 접근방법
- casting graphical model as a neural network layer
이러한 연구들과는 다르게 해당 논문에서는 dense CRF를 RNN으로 공식화하는것이 가능하다고 제안 -> end to end로 학습 가능
Conditional Random Fields
$X_i$: i번째 pixel에 할당된 random variable $L$: pre-defined set of labels $X$: vector formed by $X_i$ $N$: number of pixels in the image
$ G = (V,E) $
$V$: {$X_1,X_2,…,X_N$} I: global observation(image)
(I,X) 쌍을 모델링: $ P(X=x|I)=\frac{1}{Z(I)} \exp(-E(x|I)). $
$E(x)$: energy of the configuration $x \in \mathcal(L)^N$ $Z(I)$: partition function
Energy of a label assignment $x$ Fully connected pairwise CRF model:
$ E(\mathbf{x}) = \sum_{i} \psi_u(x_i) + \sum_{i < j} \psi_p(x_i, x_j), $
$ψ_u(x_i)$: unary energy components -> measure inverse likelihood $ψ_p(x_i,x_j)$: pairwise energy component -> measure the cost of assigning labels $x_i,x_j$
본 논문에서 unary energy는 cnn으로 부터 얻어진다 이는 label 할당의 smoothness와 일관성을 고려하지 않고 예측 pairwise energy component는 유사한 특성을 가진 pixel에 유사한 라벨을 할당하도록 장려하는 이미지 데이터에 의존하는 smoothing term 제공
$ \psi_p(x_i, x_j) = \mu(x_i, x_j) \sum_{m=1}^{M} w^{(m)} k_G^{(m)}(f_i, f_j) $
$k_G^{(m)}$: gaussian kernel applied on feature vectors $f_i$: feature vector $μ(., .)$: compatibility function -> 서로 다른 label 쌍 간의 호환성(compatibility)를 포착
$E(x)$를 최소화 하는것은 주어진 이미지에 대한 가장 가능성 높은 label assignment $x$를 도출한다 이 식에 대한 정확한 최소화는 다루기 어렵기 때문에 CRF 분포에 대한 mean-field 근사를 사용하여 대략적인 maximal posterior marginal inference를 수행(CRF 분포 $P(X)$를 독립적인 margin distribution의 곱으로 표현되는 $Q(X)$로 근사)
$ Q(X)=\Pi_iQ_i(X_i) $
# A Mean-field Iteration as a Stack of CNN Layers

이미지의 원래 공간 및 외형 정보에 따라 계수가 결정되는 edge 보존 gaussian filter를 사용 filter 크기를 이미지만큼 키워도 적은 parameter수 사용
알고리즘의 전체를 CNN layer로 분해한 뒤 RNN 구조로 재구성
negative of unary energy: $ U_i(l)=−ψ_u(X_i=l) $
원래의 CRF 방법에서 이 $U_i(l)$은 독립적인 classifier에서 얻어진다
Initialization
모든 pixel의 unary potential에 softmax function 적용한 것과 같음 어떠한 parameter도 필요하지 않음
Message Passing
각 pixel이 이미지의 다른 pixel로부터 정보를 받음
Q에 M개의 gaussian filter 적용함으로써 구현
한 pixel이 다른 pixel과 얼마나 연관되어 있는지 표현
고차원 가우시안 필터링 계산을 빠르게 만드는 근사 기법인 permutohedral lattice implementation을 사용한다
backpropagation동안 filter 입력에 대한 error 도함수는 M개의 gaussian filter를 거꾸로 적용하여 filter 출력에 대한 오류 도함수로 계산
Weighting Filter Outputs
M개의 filter output을 받아 각각의 class label l에서 weighted sum을 취한다 이는 1x1 conv로 구현 가능 M: input channel 1: output channel
Compatibility Transform
이전단계의 출력이 label간에 공유된다 두 라벨 간의 호환성은 이전에는 potts model을 사용했었는데, 이는 유사한 속성을 가진 pixel에 서로 다른 label이 할당될 경우 고정된 penalty를 부여한다. 하지만 이는 모든 라벨 쌍에 대해 동일한 페널티를 부과한다. 연결된 label 쌍마다 받는 penalty가 달라야 한다
때문에 이 함수를 학습하는것이 potts model로 사전에 고정하는 것보다 좋다
Adding unary potentials
unary input을 element-wise하게 빼준다 오류 차이를 전달
Normalization
softmax를 통해 normalization
The end-to-end trainable network
방금 cnn으로 변경한 component들을 사용하여 RNN 네트워크 구성 이를 통해 end-to-end 방식의 learning system 구현
mean-field iteration을 RNN을 통해 반복
CRF as RNN
$f_θ$: transformation done by one mean-field iteration
이미지 I가 주어졌을 때, pixel-wise unary potential value U와 marginal probabilities $Q_{in}$이 이전 iteration에서 주어진다
multiple mean-field iteration이 위의 쌓인 layer를 반복함으로써 구현될 수 있다
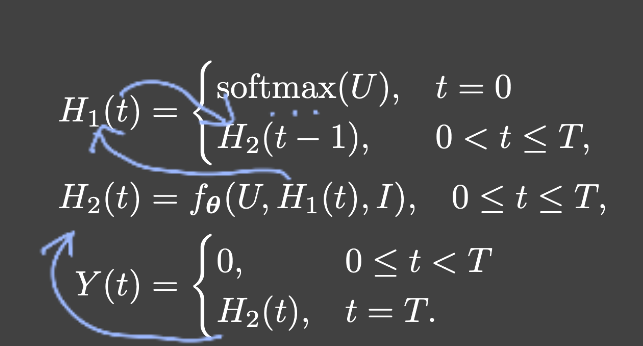
이전의 CRF를 위한 mean-field iterative algorithm들이 10번 안으로 수렴하는걸 확인 추가로 5번 반복 이후로는 성능이 더 좋아지지 않았다 그러므로 이는 gradient vanishing이나 exploding 문제를 겪지 않았다는 뜻이고 LSTM과 같은 복잡한 모델 대신 RNN을 사용할수 있었다
하지만 필요 이상의 iteration은 vanishing 혹은 exploding이 발생할 수 있다고 한다