
[Paper] DEVA: Anything with Decoupled Video Segmentation
ICCV 2023 Ho Kei Cheng, Seoung Wug Oh, Brian Price, Alexander Schwig, Joon-Young Lee University of Illinois Urbana-Champaign, Adobe Research
Abstract
video segmentation의 training data는 annotate하는데에 많은 비용이 든다. 이는 새로운 video segmentation에서 end-to-end algorithm으로의 확장을 방해하는 요소다.(annotation이 적다면, 다른 sub-network들을 사용하여 이를 보충해주는 것 같다.)
각각의 task에 대해 training을 진행하지 않고 image 안의 모든것을 tracking 하기 위해(track anything), decoupled video segmentation approach(DEVA) 을 제안한다.
DEVA
- task-specific image-level segmentation
- class/task-agnostic bidirectional temporal propagation 이 두개로 이루어져 있다. 이 두 모듈을 합치기 위해 bidirectional propagation for online fusion of segmentation을 사용한다.(segmentation과 consensus를 합쳐 하나의 segmentation mask로 생성)
Benefits
- task를 포착하기 위해 image-level의 model만 있으면 된다(video-level 필요 없음)
- 기존의 temporal propagation model도 가져와서 사용할 수 있
Introduction
기존의 video segmentation에서의 dataset은 적은 class 갯수를 가지고 있다. dataset의 class가 다양하더라고, large-vocabulary, open-world에 적용되기에는 어려움이 있다.
이에 대해 최근의 video segmentation 방법들은 open-world를 위해 만들어지긴 했으나 end-to-end 방식이 아니고, frame마다 segmentation하는 방식을 사용하기 때문에 large vocabulary set에서 end-to-end training이 더 어렵다.
이에 본 논문에서는 도메인 외부의 데이터를 활용하여 대상 훈련 데이터의 의존도를 줄이는 것을 목표로 하고, 이를 위한 decoupled video segmentation을 제안한다.
decoupled video segmentation
- test-specific image level segmentation
- task-agnostic temporal propagation
online bidirectional propagation algorithm
- in-clip consensus를 사용해 image-level의 segmentation을 denoising
- in-clip consensus와 temporal propagation의 결과를 합친다
Related work
decoupled video segmentation
Segmenting / Tracking anything
Method
Decoupled Video Segmentation
논문의 decoupled video segmentation 방법은 image segmentation module과 universal temporal propagation model에 의해 구현된다.
- image model: task-specific iamge-level segmentation hypothesis를 제공
- temporal propagation model: task specific segmentation과 general video object segmentation을 학습하는 방법을 배운다
Notation
- $t$: time index
- $I_t$: corresponding frame
- $M_t$: corresponding final segmentation
-
$ M_t={m_i,0<i<= M_t } $: set of non-overlapping per-object binary segments - $m_i \cap m_j=\emptyset, i \neq j$
- $Seg(I)$: image segmentation model
-
$ Seg(I_t)=Seg_t={s_i,0 < i <= seg_t } $: non-overlapping binary segments - $H$: collection of segmented frames
- $Prop(H,I)$: segments the query frame with the objects in the memory
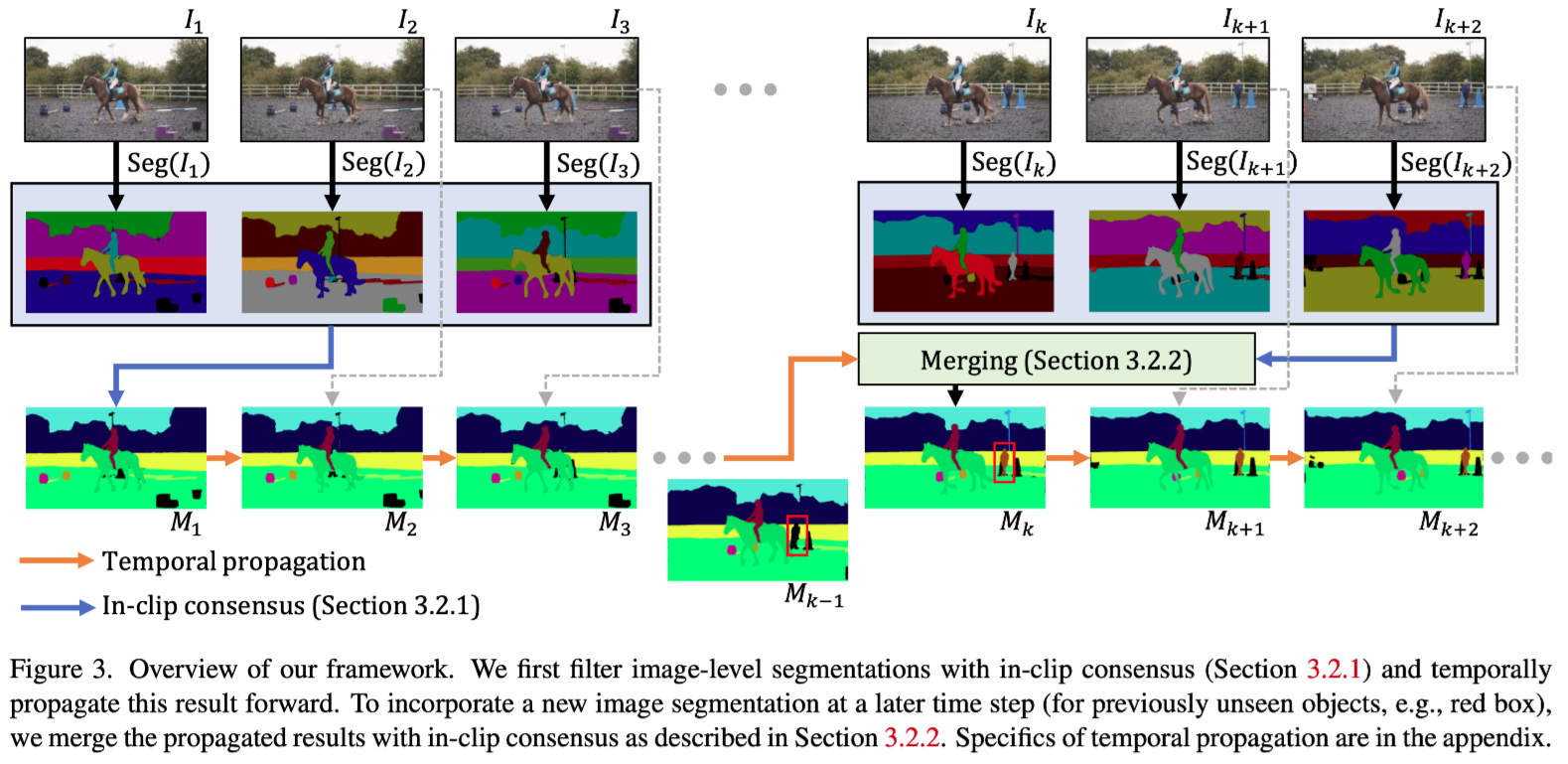
Overview
temporal propagation을 통해 image segmentation model에서 찾은 segmentation들을 전파하는게 목표이다.
첫번째 frame부터 시작하여, initialization을 위해 image segmentation model을 사용한다. 이때 논문에서는 segmentation model은 아무거나 상관없다고 한다. single-frame의 error들을 줄이기 위해 가까운 future의 몇개의 frame을 본다.(online setting시에는 current frame만을 본다.) 이후 이 frame에 대해 in-clip consensus를 통해 output을 생성한다. 생성한 output은 temporal propagation model을 사용하여 subsequent frame에 segmentation을 전파한다.(temporal propagation model은 XMem을 조금 수정하여 사용)
propagation model 자체는 새로운 객체를 segment 할 수 없기 때문에, 이전과 같은 in-clip consensus를 활용하여 주기적으로 새로운 이미지 segment 결과를 통합하고 consensus를 전파된 결과와 합쳐준다.
이 논문의 pipeline은 propagation model로부터 온 temporal consistency(past)와, segmentation model로부터 온 새로운 semantic(future)를 합쳐주기 때문에 논문에서는 bidirectional propagation이라고 한다.
Bidirectional Propagation
In-clip consensus
: 특정 비디오 clip 내에서 여러 frame 또는 data point들 간의 일관된 정보를 얻기 위한 consensus(합의) mechanism. clip 내 각 frame에서 관찰되는 객체의 행동이나 상태가 일관되게 처리되게 함으로써 전체 비디오에서 객체의 정확한 동작이나 위치를 더 정확히 segment 할 수 있다.
In-clip consensus 연산은 n개의 작은 future clip의 image segmentation에 대해 수행되고 현재 frame의 denoised consensus $C_t$를 만들어낸다.(online setting에서는 n=1, $C_t=Seg_t$ 이다)
Process spatial alignment
- target frame t로 spatial alignment를 통해 object proposal을 가져온다. segmentations: (Segt, Segt+1, …, Segt+n−1) 이렇게 가져온 segmentation들은 timestep이 다르기 때문에 misaligned 될 확률이 높다. segmentation $Seg_{t+i}$를 t와 align시켜주기 위해 논문에서는 temporal propagation을 사용한다.
$ \hat{Seg_{t+i}}=Prop({I_{t+i},Seg_{t+i},I_t}),0<i<n $
이때 global memory H와는 상호작용하지 않는다.
representation
- object proposal을 combined representation으로 병합한다. 이전에 segmentation을 non-overlapping per-object binary segments로 정의했었다. spatial alignment를 통해 segmentation을 전부 align하면, 각각의 segment들은 frame $I_t$의 object proposal이 된다. 이런 proposal을 합쳐 P라고 정의한다.
$ P = \bigcup_{i=0}^{n-1} \hat{Seg_{t+i}} = {p_i, 0 < i \leq |P|}. $
consensus 결과는 P에 속하는 indicator variable $v^*$를 사용하여 segment들을 $C_t$에 결합시키는 것으로 나타낼 수 있다.
$ C_t = {p_i | v_i^* = 1} = {c_i, 0 < i \leq |C_t|}. $
중복되는 segment들을 크기별로 내림차순으로 정렬한다. 아래의 2가지 기준으로 v를 최적화한다.
- 혼자 있는 proposal들은 아마도 noise일 가능성이 높고, 이들은 버리도록 한다. 선택된 proposal들은 다른 선택되지 않은 proposal들에 의해 support(겹쳐야 한다는걸 의미)되어야 한다.
- 선택된 proposal들은 많이 겹쳐서는 안된다.
integer programming
- indicator variable이 proposal의 subset을 선택할 수 있도록 최적화한다.
$ v^* = \underset{v}{\mathrm{argmax}} \sum_i (\text{Supp}i + \text{Penal}_i) \quad \text{s.t.} \quad \sum{i,j} \text{Overlap}_{ij} = 0 $
s.t.는 proposal이 겹치지 않는다는 조건을 의미한다.
i번째 proposal은 IOU가 0.5보다 클 때 j번째 proposal을 support한다. IOU가 높을수록 support 가 강하고, segment가 많은 support를 받을수록 선택될 가능성이 높아진다. 선택된 segment의 support를 최대화 하기 위해 다음의 objective를 모든 i에 대해 최대화한다.
$
\text{Supp}i = v_i \sum_j \begin{cases}
\text{IoU}{ij}, & \text{if } \text{IoU}_{ij} > 0.5 \text{ and } i \neq j
0, & \text{otherwise}
\end{cases}
$
또한 서로를 support 하는 proposal들은 overlap되므로 같이 선택되면 안된다. 이는 다음을 항상 0으로 제한함으로써 구현할 수 있다.
$
\text{Overlap}{ij} = \begin{cases}
v_i \cdot v_j, & \text{if } \text{IoU}{ij} > 0.5 \text{ and } i \neq j
0, & \text{otherwise}
\end{cases}
$
마지막으로 segment가 support가 하나도 없거나, noise가 있는 segment를 없애기 위해 penalty를 준다.
$ Penal_i=-\alpha v_i $
$\alpha = 0.5$ 로 설정한다. 첫 번째 frame에 대해, $C_t$를 propagated segmentat ion Prop(H,$I_t$)과 병합하여 final output $M_t$를 생성한다.
Merging Propagation and Consensus
$C_t$와 Prop(H,$I_t$)를 병합한다. 이때 두 segmentation에서 segment들을 연결하고, 만약 $r_i$와 $c_j$가 연관성이 있다면 indicator $a_{ij}$를 1로, 그렇지 않다면 0으로 표시한다. 여기서는 In-clip consensus와는 다르게, 두개의 segment가 각각 다른 정보를 담고 있기 때문에 segment를 제거하지 않고 연관된 segment 쌍을 모두 융합하며 연관되지 않은 segment들은 출력으로 그대로 통과시킨다.
$ M_t = { r_i \cup c_j | a_{ij} = 1 } \cup { r_i | \bigvee_j a_{ij} = 0 } \cup { c_j | \bigvee_i a_{ij} = 0 } $
Maximizing Association IoU
$
e_{ij} = \begin{cases}
\text{IoU}(r_i, c_j), & \text{if } \text{IoU}(r_i, c_j) \geq 0.5
-1, & \text{otherwise}
\end{cases}
$
연관된 쌍의 IoU를 최대화함으로써 $a_{ij}$를 찾는다. e가 0보다 클 경우 $a_{ij}$를 1로 설정.
Experiment
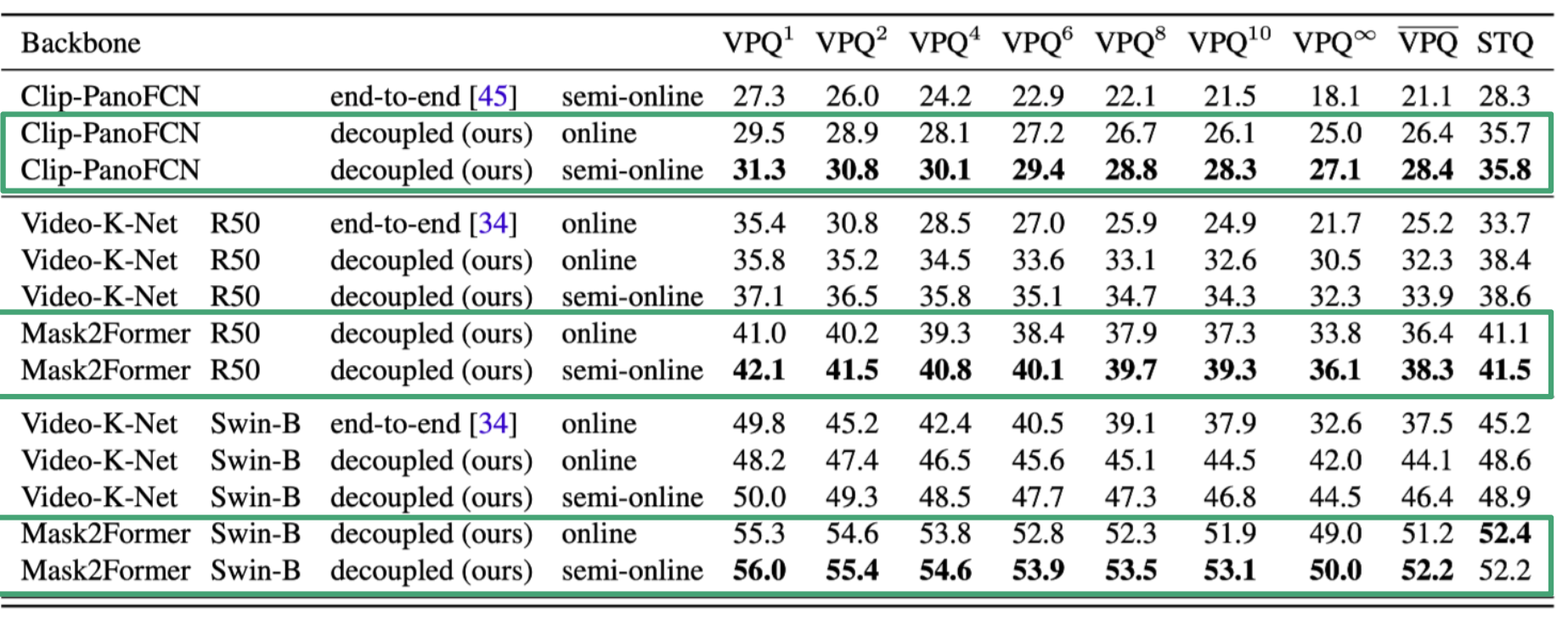
논문에서 제안한 method를 사용했을때, 기존 model에 비해 성능 향상이 있었다.

정성적 평가를 봤을 때 좋은 성능을 보여주고 있다.
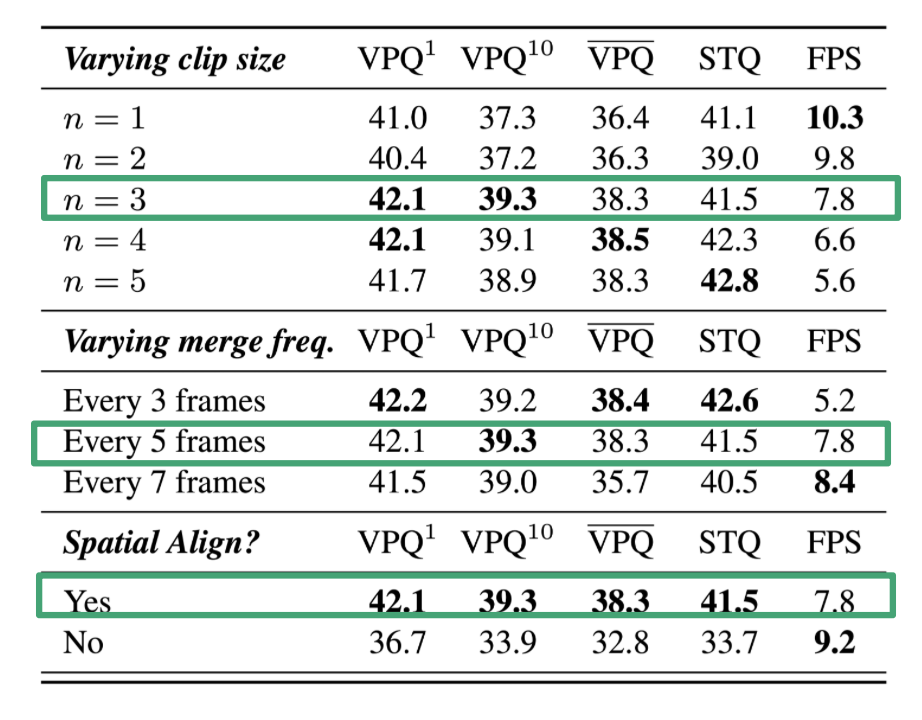
여러 hyper parameter에 대해 ablation study를 진행하였다. clip size는 in-clip consensus 내에서 얼만큼 frame의 정보를 가져올지의 정보이다.
Conclusion
+
- image-level model만을 사용하여 video를 segment 할 수 있다.
- task에 대해 general하다.
-
- model의 성능이 image-level segmentation model에 의해 바뀌는 경향이 있다.