
[Paper] DiffIR: Efficient Diffusion Model for Image Restoration
Abstract
Diffusion 모델은 이미지 합성 프로세스를 노이즈 제거 네트워크의 sequential application 으로 모델링하여 SOTA 성능을 달성했지만, 이미지 복원은 ground truth에 따라 결과를 생성하는 강한 제약이 있었다.
때문에 이미지 복원 task에서는 전체 이미지 또는 feature map을 추정하기 위해 대규모 모델에서 대규모 반복을 하는 전통적인 Diffusion model은 비효율적이다.
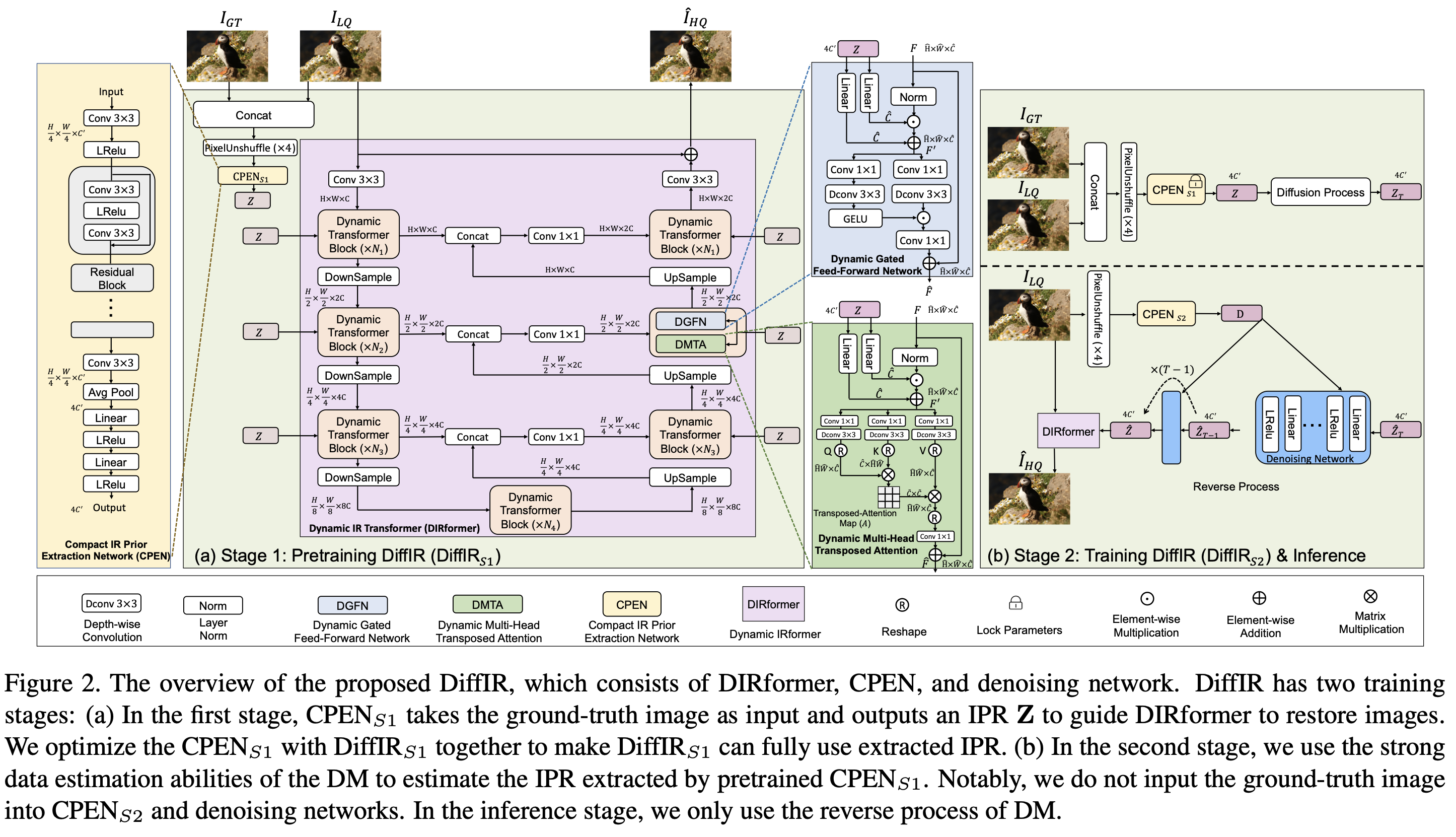
본 논문에서는 이를 해결하기 위해 compact IR prior extraction network(CPEN), dynamic IR Transformer(DIRformer), denoising network로 구성된 DiffIR을 제안한다.
이 DiFFIR에는 pre training, training DM의 2가지 training 단계가 있다.
- pre training
- ground truth 이미지를 CPEN_S1에 입력하여 compact IR prior representation을 캡처하여 DIRformer를 안내한다.
- DM training
- DM이 LQ 이미지만 사용하여 pretrained 된 CPEN_S1과 동일한 IRP를 직접 추정하도록 훈련한다.
- IPR은 compact vector기 때문에 DiffIR은 정확한 예측을 얻고 더 안정적이고 좋은 결과를 얻기 위해 전통적인 DM보다 적은 iteration을 사용할 수 있다.
- iteration이 적기 때문에 DiffIR은 CPEN_S2,DIRformer및 노이즈 제거 네트워크 등 joint optimization을 채택하여 estimation 오류 영향을 더 줄일 수 있다.
Introduction
최근 노이즈 제거 auto encoder의 계층 구조로 구축된 diffusion model은 이미지 합성 및 IR작업에서 좋은 결과를 보여주었다. 특히 DM은 diffusion 프로세스를 반대로 하여 이미지를 반복적으로 노이즈화 하도록 훈련된다. DM은 pribablistic diffusion 모델링이 GAN과 같은 mode collapse및 훈련 불안전성을 겪지 않고 무작위로 샘플링된 가우스 노이즈에서 실제 이미지 또는 latent 분포와 같은 복잡한 목표 분포로의 고품질 mapping을 실현할 수 있음을 보여주었다.
DM은 데이터의 정확한 세부 정보를 모델링 하기 위해 대규모 노이즈 모델에 대한 많은 반복 단계(50~1000)가 필요하며, 이는 막대한 계산자원을 소비한다.
IR작업은 주어진 LQ이미지에 정확한 세부 정보를 추가하기만 하면 된다. 따라서 DM이 IR에 이미지 합성 패러다임을 채택하면 많은 계싼 자원을 낭비할 뿐만 아니라 주어진 LQ 이미지와 일치하지 않는 일부 세부 정보를 생성하기가 쉽다.
본 논문에서는 DM의 강력한 분포 매핑 기능을 완벽하고 효율적으로 사용하여 이미지를 복원할 수 있는 DM 기반 IR 네트워크를 설계하는 것을 목표로 한다.이를 위해 DiffIR을 제안한다.
transformer가 장거리 픽셀 종속성을 모델링 할 수 있기 때문에, 우리는 DiffIR의 기본 단위로 transformer block을 채택한다.
UNet형태로 tranasformer block을 쌓아 DIRformer를 형성하여 다단계 feature를 추출 및 집계한다.
본 논문에서는 DiffIR을 2단계로 훈련한다.
- ground truth image에서 compact IR prior extraction network(CPEN)을 개발하여 DIRformer를 가이드 한다. 또한 DIRformer가 IPR을 완전히 사용할 수 있도록 Dy-namic Gated Feed-Forward Network(DGFN)와 Dynamic Nulti-Head Transposed Attention(DMTA)를 개발한다.
- LQ이미지로부터 정확한 IPR을 직접 추정하도록 DM을 훈련한다.복원을 위한 세부 정보만 추가하기 때문에, 논문의 DM은 꽤 정확한 IPR을 추정하고 여러번 반복한 후 안정적인 시각적 결과를 얻을 수 있다.
위의 체계 및 신규 구조 외에도, joint optimization의 효과를 보여준다.
key ideas
- IR을 위한 간단하고 효율적인 DM 기반 DiffIR을 제안한다. 영상 합성과는 달리 IR에서 입력 영상의 대부분의 픽셀이 주어지기 때문에 DM의 강력한 매핑 능력을 이용하여 IR을 guide하는 compact IPR을 추정하여 IR에서 DM의 복원 효율과 안정성을 향상시킬 수 있다.
- IPR을 완전히 활용하기 위해 DGTA 및 DGFN을 Dynamic IRformer에 제안한다. 노이즈 제거 네트워크를 개별적으로 최적화하는 이전의 latent DM과 달리 추정 오류의 견고성을 더욱 향상시키기 위해 노이즈 제거 네트워크 및 디코더(DIRformer)의 joint optimization을 제안한다.
Preliminaries: Diffusion Models
본 논문에서는 정확한 IPR을 생성하기 위해 diffusion model을 채택한다.
확산 과정의 각 iteration은 다음과 같이 설명할 수 있다.
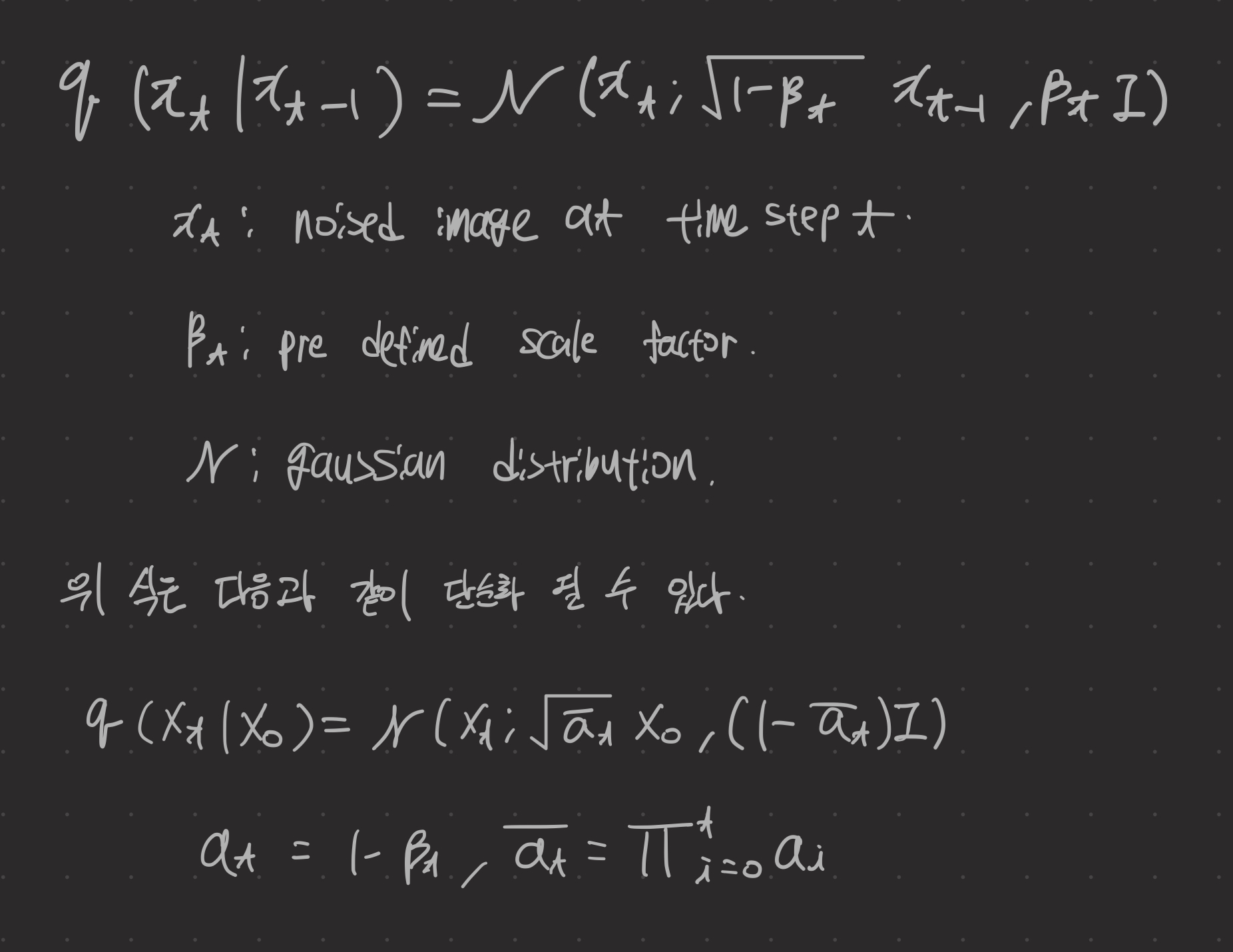
추론 단계에서 DM method는 가우시안 랜덤 노이즈 맵 x_T를 샘플링한 다음 고품질 출력 x_0에 도달할 때까지 점진적으로 x_T의 노이즈를 제거한다.
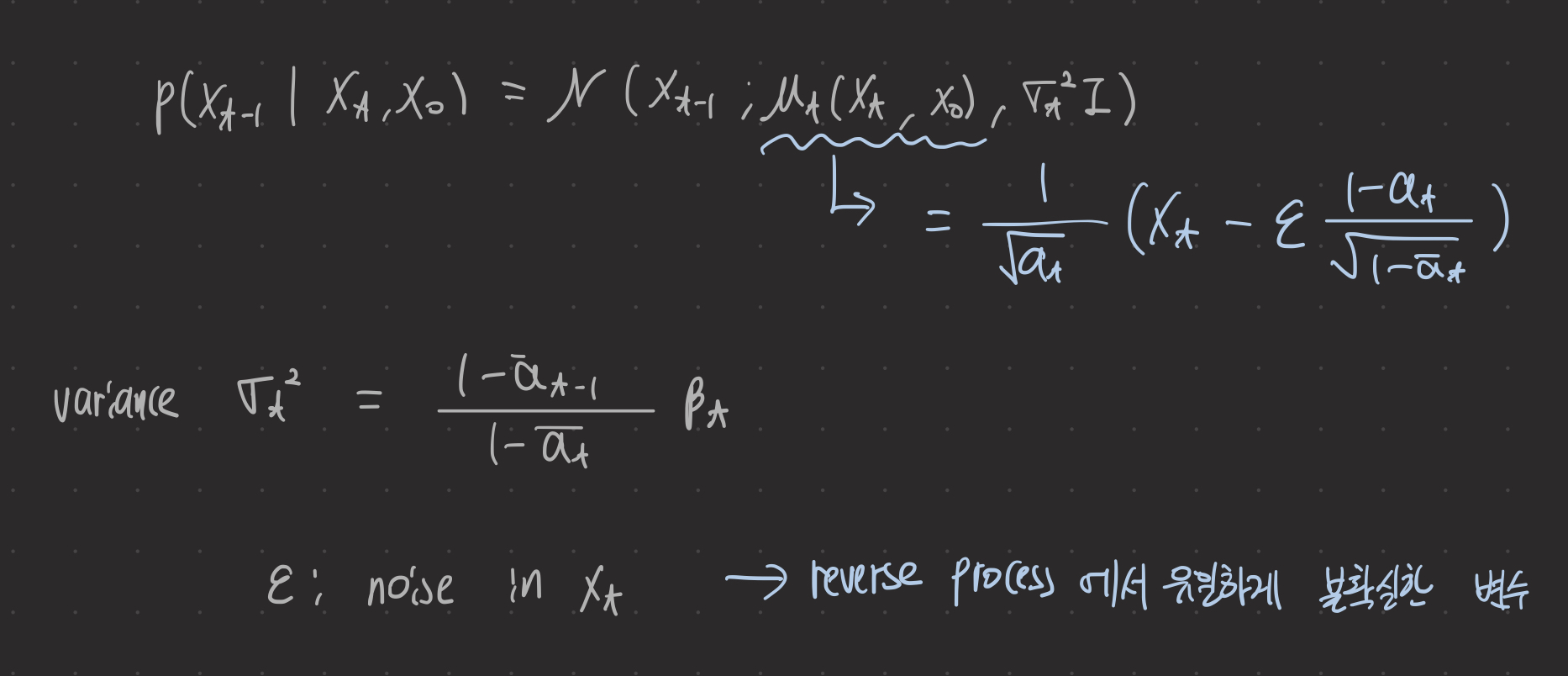
DM은 ε를 추정하기 위해 denoising network ε_θ(xt,t) 를 채택한다.
또한 DM은 timestep t와 노이즈 ε ~N (0, I) 를 랜덤으로 샘플링하여 식(첫번쨰 사진의 식을 단순화한 식)에 따라 노이즈 이미지 x_t를 생성한다. 그런 다음, DM은 ε_θ들의 parameter θ를 최적화한다.
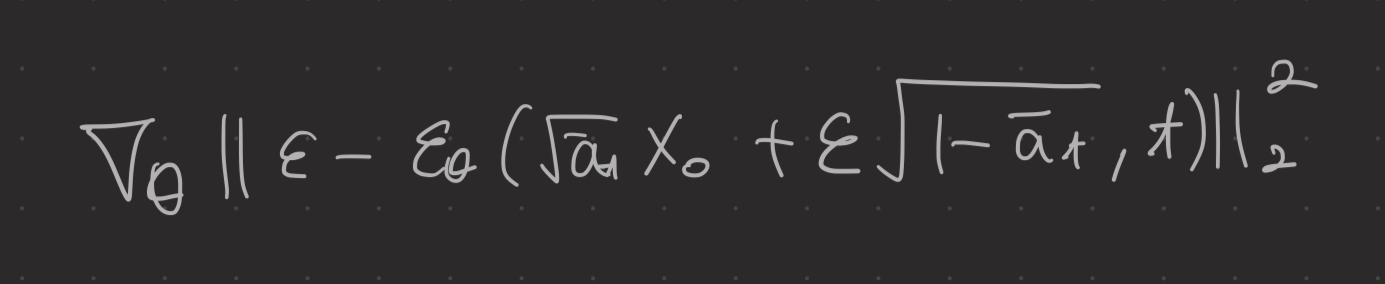
Methodology
전통적인 DM은 정확하고 사실적인 이미지 또는 latent feature map을 생성하기 위해 많은 iteration, 계산 자원 및 모델 매개 변수가 필요하다.
DM은 처음부터 이미지를 생성하는데 좋은 성능을 달성하지만, 이미지 합성의 DM 패러다임을 IR에 적용하는 것은 비효율적이다. IR의 대부분의 픽셀과 정보가 주어지기 때문에 전체 이미지 또는 feature map에 DM을 수행하면 많은 반복과 계산을 수행할 뿐만 아니라 더 많은 아티팩트를 생성하기 쉽다.
이 문제를 해결하기 위해, 네트워크가 이미지를 복원하도록 guide하기 위해 DM을 사용하여 소형 IPR을 추정하는 IR의 효율적인 DM을 제안한다.
그림에서 보는바와 같이 DiffIR은 주로 compact IR prior extraction network, DIRformer, 및 노이즈 제거 네트워크로 구성된다.
DiffIR을 pre-training하고 diffusion모델은 훈련하는 것을 포함하여 2단계로 나누어 훈련한다.
Pretrain DiffIR
- CPEN
- residual block과 선형 layer로 쌓여 compact IPR을 추출하는 구조(그림의 노란 박스)
- DIRformer
- UNet 형태의 동적 변환 블록으로 쌓여있다. 동적 변환 블록은 DMTA와 DGFN으로 구성되어 IPR을 동적 변조 매개변수로 사용하여 복원 세부 정보를 feature map에 추가한다.(그림의 분홍 박스)
pretrain 단계에서는 CPEN_S1과 DIRformer를 함께 훈련한다. ground truth및 LQ 이미지를 연결하고 Pixel Unshuffle연산을 사용하여 downsampling하여 CPEN_S1에 대한 입력을 얻는다. 이후 CPEN_S1은 IPR Z를 다음과 같이 추출한다.

이후 DMTA 내의 global spatial information을 통합한다.

기존의 multi-head attention이 그랬던 것처럼, 본 논문에서는 multi-head로 채널을 분리하고 attention map을 계산한다.
다음으로, DGFN에서 local feature를 집계한다. 1x1 conv를 사용하여 다른 채널의 정보를 집계하고, 인접한 픽셀의 정보를 집계하기 위해 3x3 깊이별 conv를 사용한다.
또한 정보 인코딩을 향상시키기 위해 gaiting 매커니즘을 채택한다.
DGFN의 전체적인 과정은 다음과 같이 정의된다.

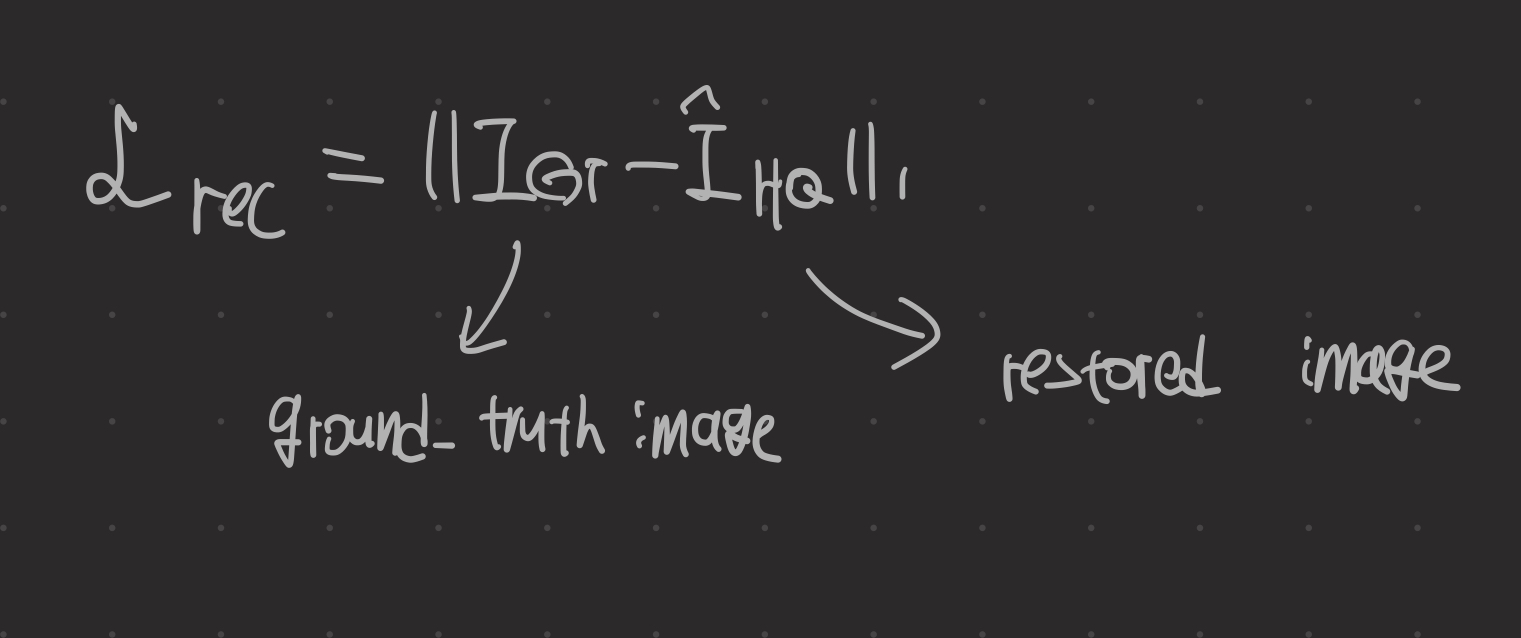
CPEN_S1 DIRformer를 함께 훈련하는데, 이는 DIRformer가 CPEN_S1에 의해 추출된 IPR을 복원에 완전히 사용하도록 만들 수 있다. training loss는 다음과 같이 정의된다.
Diffusion Models for Image Restoration
두번쨰 단계에서는 DM의 강력한 데이터 추정 능력을 활용하여 IPR을 추정한다. IPR을 캡처하기 위해 pretrain된 CPEN_S1을 사용한다. 이후 z에 대한 확산 과정을 Z_T샘플에 적용한다.
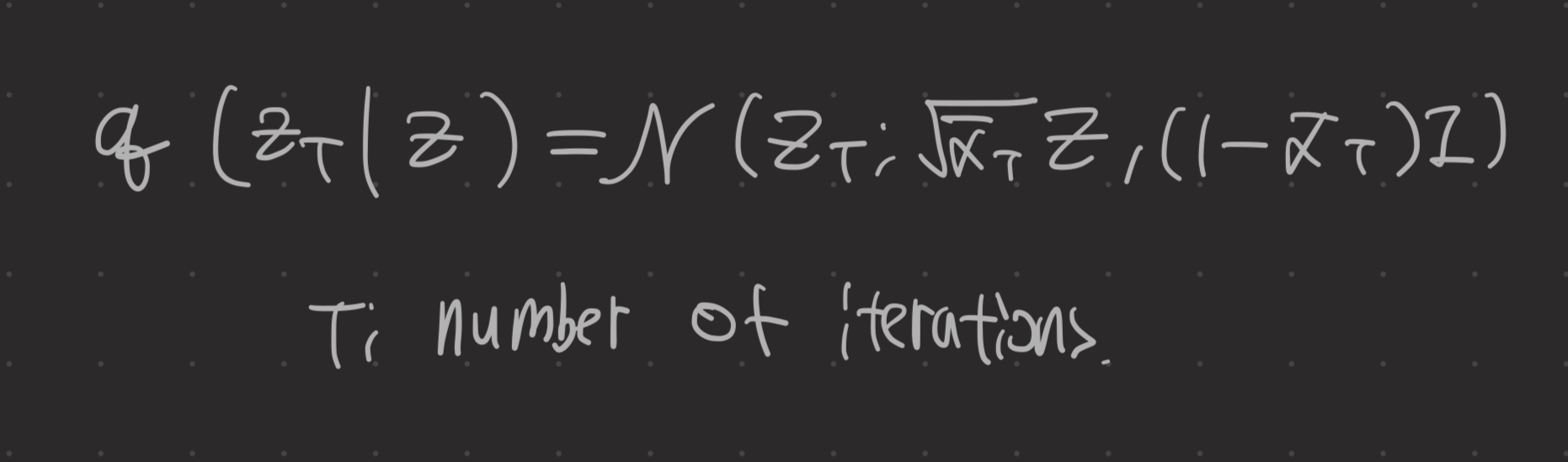
reverse 과정에서, IPR이 작기 때문에 DiffIRS2는 전통적인 DM보다 훨씬 적은 반복과 작은 모델크기를 사용하여 꽤 좋은 추정치를 얻을 수 있다. DiffIR은 T번쨰 timestep에서 시작하여 모든 노이즈 제거 반복을 수행하여 Z^를 얻고 joint optimization을 위해 DIRformer로 전달한다.
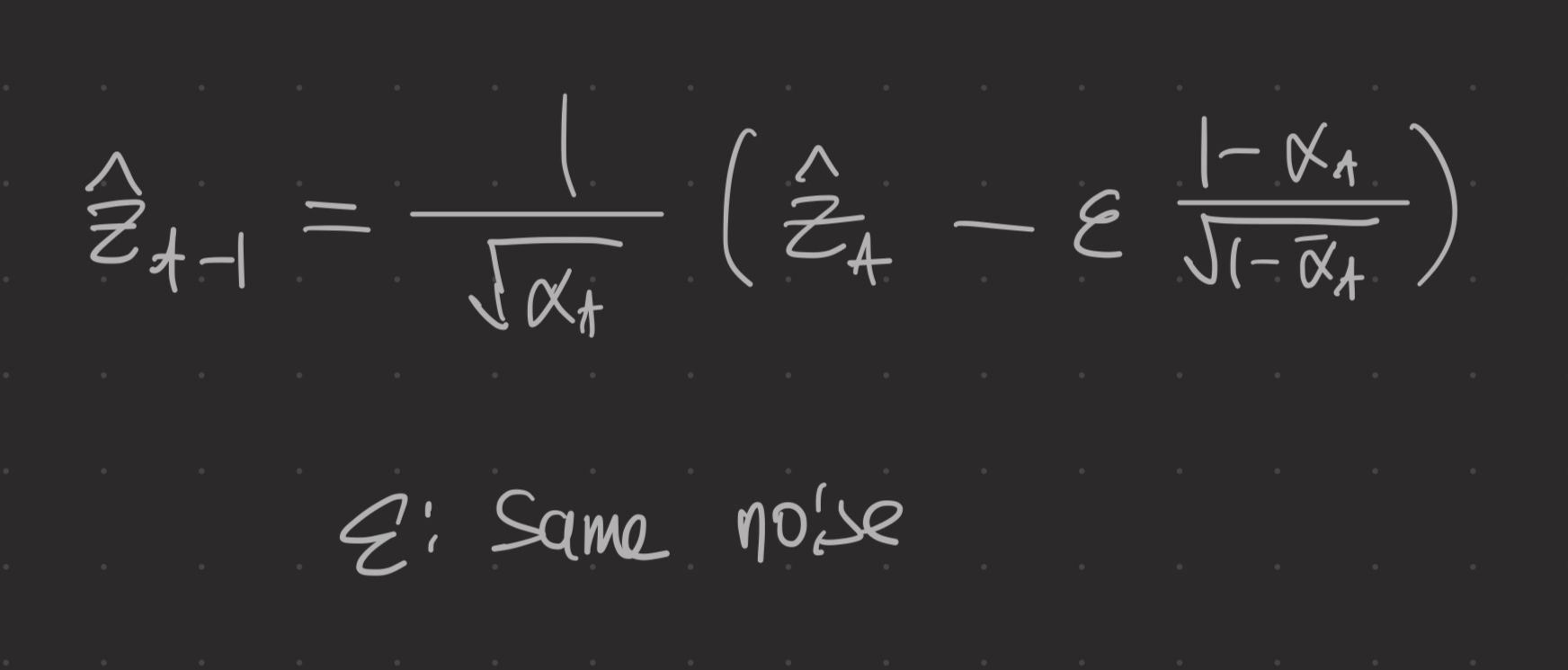
이후 CPEN_S2및 잡음 제거 네트워크를 사용하여 노이즈를 예측한다.
DM의 reverse 과정에서, 먼저 CPEN_S2를 사용하여 LQ 이미지로부터 조건벡터 D를 얻는다.
D = CPEN_S2(PixelUnshuffle(I_LQ))
여기서 CPEN_S2는 첫 번쨰 conv의 입력 차원을 제외하고 CPEN_S1과 동일한 구조를 갖는다.
이후 잡음 제거 네트워크 ε_θ를 사용하여 각 timestep t에서 잡음을 추정한다. 추정된 잡음은 다음 iteration을 위해 z_t-1을 얻기 위해 위의 식으로 대체된다.
이후 T회 반복 후 최종 추정 IPR Z를 얻는다.
아래의 loss function을 사용하여 CPEN_S2, 노이즈 제거 네트워크, DIRformer를 같이 훈련한다.
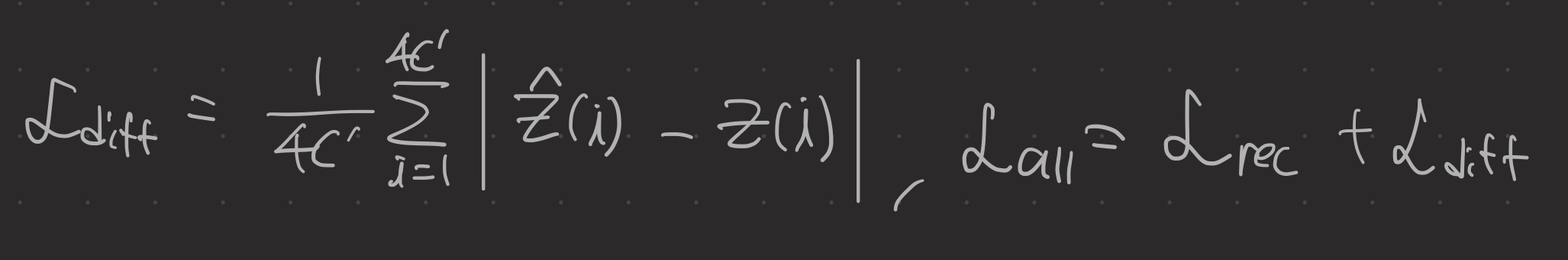
추론 단계는 reverse diffusion 과정만을 사용한다.(구조 그림의 아래 부분)
CPEN_S2는 LQ영상에서 조거넥터 D를 추출하고 가우시안 노이즈 Z_T를 무작위로 샘플링한다. 노이즈 제거 네트워크는 Z_T와 D를 활용하여 반복 후 IPR_Z를 추정한다. 이후 DIRformer는 IPR을 활용하여 LQ영상을 복원한다.