
[Paper] FFNeRV: Flow-Guided Frame-Wise Neural Representations for videos
Abstract
좌표 기반 또는 암시적 신경 표현으로 알려진 neural field는 다양한 형태의 신호를 표현, 생성 및 조작하는 능력을 보여주었지만 비디오 표현의 경우 픽셀별 좌표를 RGB색상에 매핑하는 것은 상대적으로 낮은 압축 성능과 느린 수렴 및 추론 속도를 보여주었다.
시간 좌표를 전체 프레임에 매핑하는 프레임 별 비디오 재생은 최근 비디오를 표현할 수 있는 대안적인 방법으로 부상하여 압축률과 인코딩 속도를 향상시키고 있지만 최첨단 비디오 압축 알고리즘의 성능에 도달하는데에 실패했다.
본 논문에서는 표준 비디오 코덱에서 영감을 받은 비디오의 프레임에 걸친 시간적 중복성을 활용하기 위해 흐름 정보를 프레임별 재전송에 통합하는 새로운 방법인 FFneRV를 제안한다
또한 1차원 시간 그리드에 의해 가능한 fc 구조를 도입하여 공간 기능의 연속성을 향상시킨다
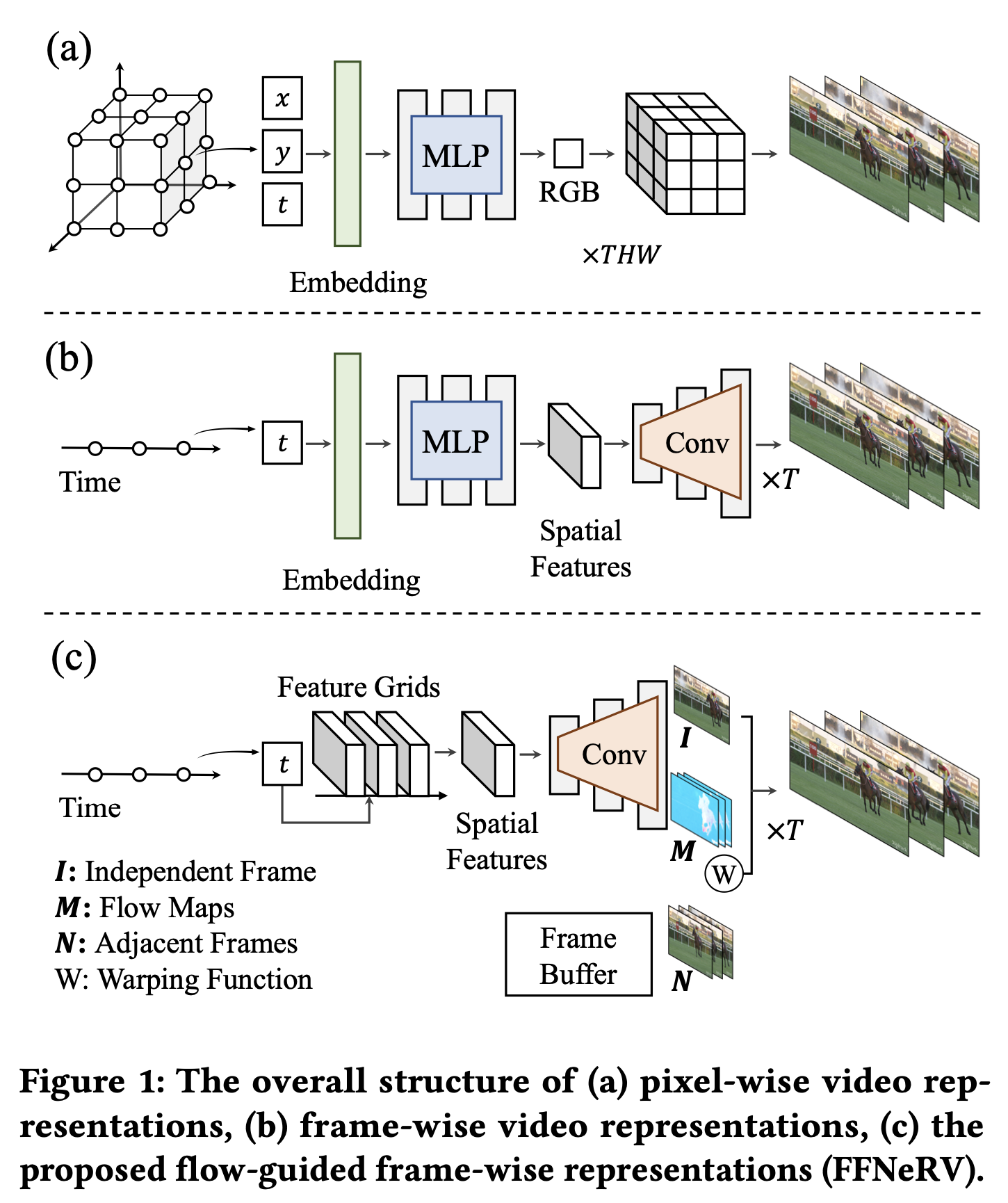
Introduction
여러 연구에서 이미지 및 비디오 압축을 포함하여 데이터 압축에 좌표 기반 신경 표현을 사용할 것을 제안하였다.
구현, 업데이트 및 유지보수가 훨씬 쉽지만 압축 성능에는 미치지 못하고 많은 양의 계산이 필요했다.
따라서 논문에서는 비디오에 대한 흐름 유도 프레임별 신경 표현을 제안
optical flow를 프레임별 표현에 통합하여 시간적 중복성을 활용
FFNeRV는 flow에 의해 유도된 인접 프레임을 통합하여 비디오 프레임을 생성하여 다른 프레임의 픽셀 재사용을 강제한다
이는 네트워크가 프레임에 걸쳐 동일한 픽셀 값을 기억하여 매개 변수 효율성을 향상시킨다
그리드 기반 신경 표현에 영감을 받아 고정된 공간 해상도를 가진 다중 해상도 시간 그리드를 사용하여 연속 시간 좌표를 대응하는 latent feature에 매핑할 것을 제안
Key ideas
- 시간적 중복성을 이용하기 위해 optical flow를 프레임 단위 표현에 통합하여 흐름 유도 프레임 단위 비디오 표현을 제안
- 그리드 기반 신경 표현에 영감을 바당 연속시간 좌표를 해당 latent feature에 매핑하기 위해 고정된 공간 해상도를 가진 다중 해상도 시간 그리드를 사용할 것을 제안
- 추가적인 효율성을 위해 소형 컨볼루션 구조와 purnishing-robust quantization=aware training을 제안
FFNeRV
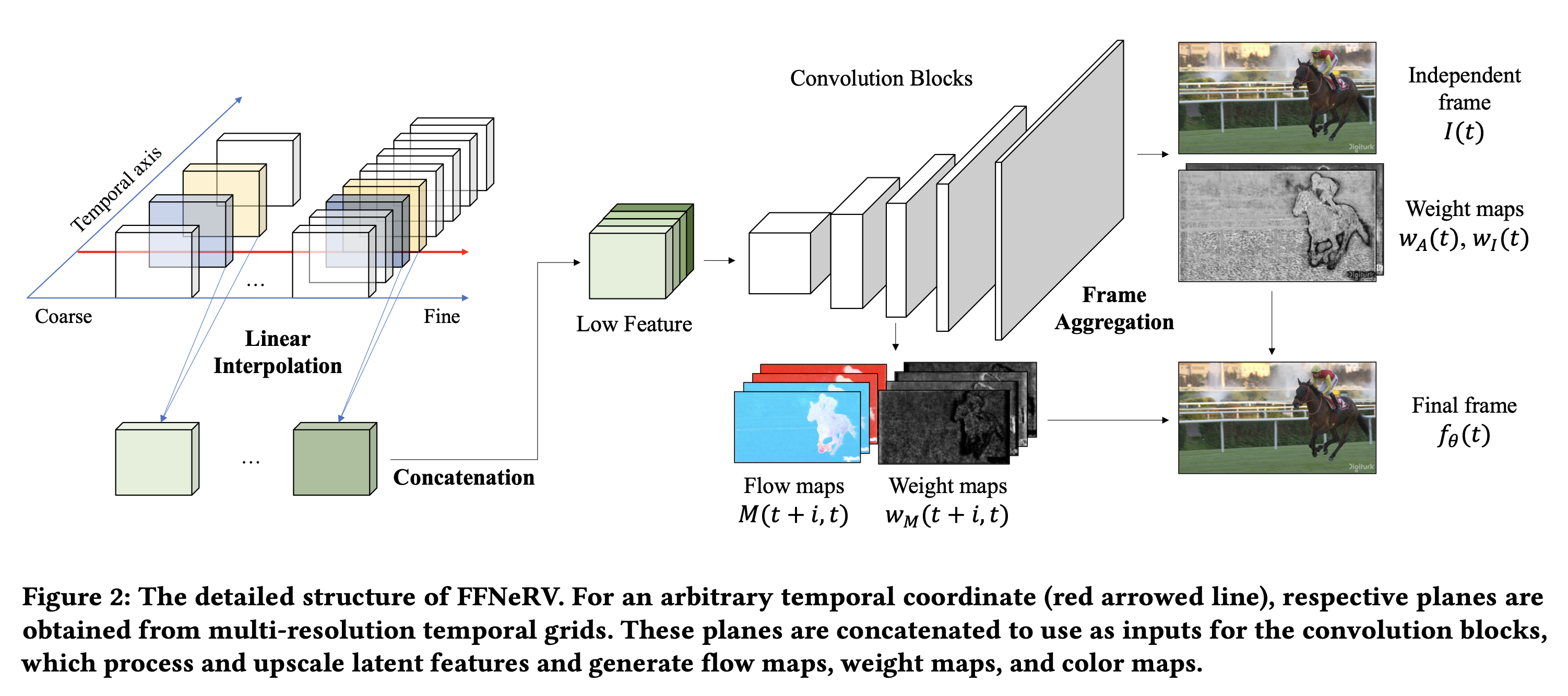
Multi-Resolution Temporal Grid
- 위치 인코딩 및 MLP 대신 그리드를 사용
- 시간 차원에 대한 선형 보간을 사용하여 그리드에서 공간 특징을 추출
- 시간 해상도는 다르지만 공간 해상도가 동일한 다중 해상도 그리드를 사용하여 각 그리드가 고유한 시간 주파수를 커버하도록 한다
- 각 그리드에서 보간된 출력은 연결되어 주어진 시간 좌표에 대한 잡재적 2차원 특징 생성
FLow-Guided Frame Aggregation
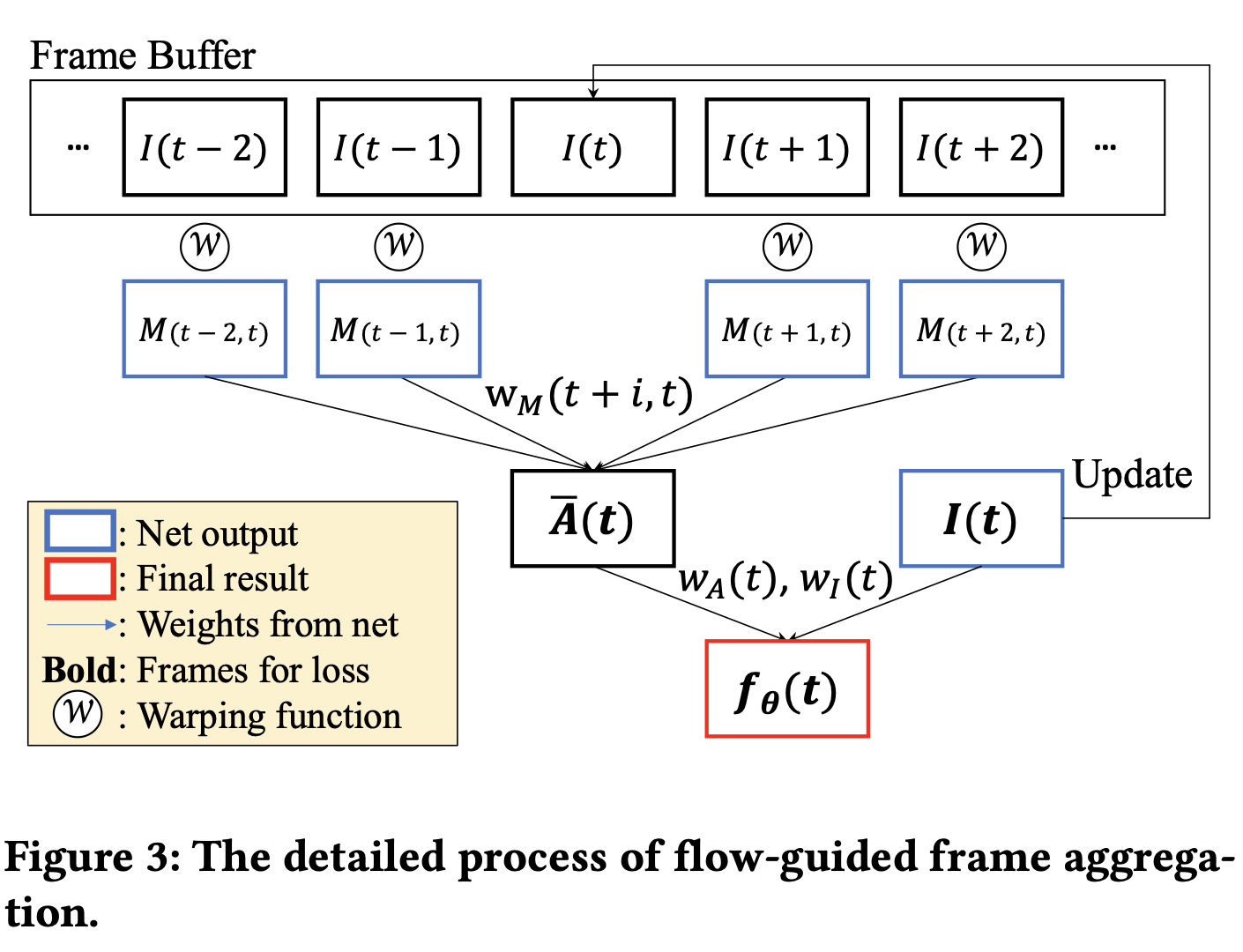
- flow guided frame aggregation을 제안하여 프레임별 비디오 표현에 이 접근방식을 도입
- 다중 해상도 그리드에서 흐름맵 및 집계 가중치를 생성하는 latent feature를 사용
- 최종 프레임을 얻기 위해 flow map과 종속적인 프레임 근처를 워프하고 집계 가중치를 사용하여 시간에서 독립적인 프레임과 결합
- 프레임별 비디오 표현 프로세스가 넓은 관접에서 NeRV 및 E-NeRV와 유사하지만 시간적 중복성을 명시적으로 활용하여 표현 성능을 크게 향상시킬 수 있다
Frame aggregation
- 그림은 최종 프레임 구축을 위한 집성 과정
- 이중 선형 warping을 사용하여 flow map으로 근처의 독립 프레임을 변환
- 그 다음 가중치에 소프트맥스 함수ㅡㄹ 적용하여 각 픽셀당 1개까지 추가하고 이러한 정규화된 가중치를 warping frame에 곱한다
spatial resolution of outputs
- 표현 용량을 5개의 서로 다른 출력으로 할당
- flow map은 일반적으로 컬러 맵보다 부드럽고 난이도가 낮으므로 낮은 해상도로 효율적으로 표현 가능
Model Compression
- 제안된 compact model 구조와 양자화 인식 훈련 방법
Compact convolutional architecture
- 모델 자체의 크기를 줄이기 위해 효율적인 컨볼루션 구조를 채택
Quantization-Aware Training
- 모델 훈련, 모델 가지치기, 가중치 양자화, 가중치 인코딩의 4가지 단계로 표현 모델을 압축
- 양자화 인식 훈련을 도입하면 압축 성능을 향상시키면서 전체 절차를 두 단계 또는 세 단계로 단순화 할 수 있다