
[Paper] FPN: Feature Pyramid Network
Abstract
Feature pyramid -> basic component in recognition system for detecting different scales
Recent paper didn’t use because of compute and memory intensive
Paper’s propose : inherent multi-scale, pyramid hierarchy of deep conv nets to construct feature pyramid with marginal extra costs
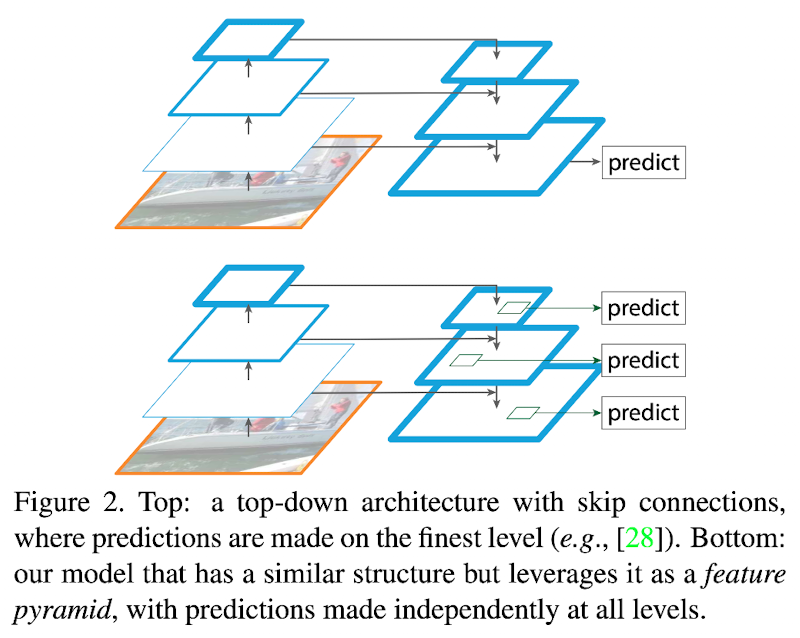
Top-down architecture with lateral connections -> for high-level semantic feature maps at all scales
FPN show significant improvements as a generic feature extractor
FPN + Faster R-CNN -> SOTA on COCO
Introduction
Recognizing different scales -> CV task’s challenge
Object’s scale change is offset by shifting level in the pyramid -> scale invariant Scale invariant enables model to detect objects across large range of scales by scanning position and pyramids
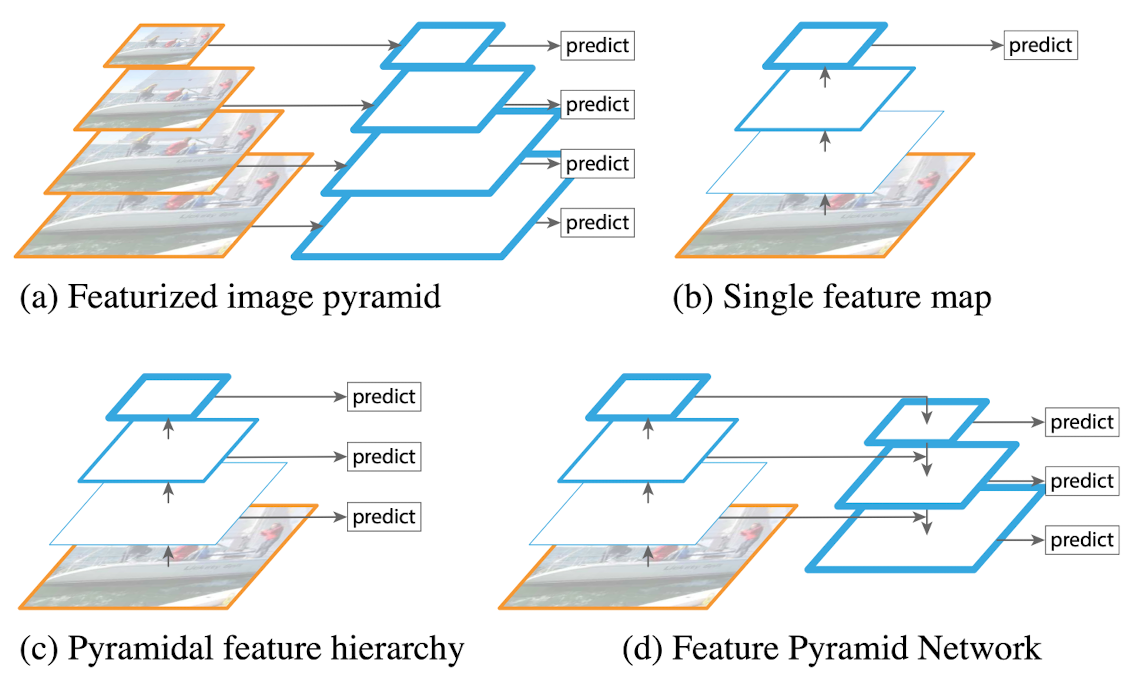
Previous Featurized pyramids -> need dense scale sampling ex)[[DPN]]
Recognition task -> engineered feature replaced by features computed by deep conv nets Conv nets : robust to variance in scale, represent higher-level semantics recognition from feature computed on a single input scale
But conv nets still need pyramids.
Recent results at ImageNet and COCO detection : Use multi-scale testing on featurized image pyramids
Advantage of featurizing each level -> Produce multi-scale feature representation (all levels semantically strong)
Limitation of featurizing each level : - Inference time - Train deep net end-to-end -> infeasible in terms of memory -> Fast, Faster R-CNN do not use featurized image pyramids
Deep conv net computes feature hierarchy layer by layer, inherent multi-scale with subsampling layers
Limitation of Pyramidal feature hierarchy : - large semantic gaps caused by different depth - high resolution maps have bad low-level features -> harm representational capacity
SSD : First attempts to use ConvNet’s pyramidal feature hierarchy - Build the pyramid starting from high up in the network
1
2
- Then add several new layers
- <mark style="background: #FF5582A6;">Miss opportunity to reuse higher-resolution maps of the feature hierarchy</mark>
FPN : naturally leverage pyramidal shape of a ConvNet’s feature hierarchy while creating a feature pyramid that has strong semantics at all scales
-
Use architecture that combines low-resolution(semantically strong) and high-resolution(semantically weak features) through top-down pathway and lateral connection
-
Leverages architecture as a feature pyramid where predictions are independently made on each level
-
Echoes featurized image pyramid (not been explored before)
-
Result :
- Rich semantics at all levels
- Built quickly from a single input image scale
Evaluate FPN in detection and segmentation
Can be trained end-to-end with all scales.
Related work
Hand-engineered features and neural networks
[[SIFT]] feature -> Extracted at scale-space extrema and used for feature point matching
[[HOG]] feature -> computed densely over entire image pyramids.
2 methods -> Interest in computing featurized image pyramids quickly
ConvNets -> computed shallow networks over image pyramids to detect faces across scales
ConvNets을 사용한 이전의 방법들은 image pyramid에서 shallow network를 계산하였지만, 위의 방법과 Dollar 의 방법은 계산 효율성을 높이는 등의 CV 기술의 발전을 보임
Deep ConvNet object detectors
OverFeat, R-CNN showed improvements in accuracy.
[[OverFeat]] -> apply ConvNet as a sliding wondow detector on an image pyramid
R-CNN -> apply region proposal-based strategy (scale-normalized before classifying with a ConvNet)
[[SPPnet]] -> showed region-based detectors can be applied efficiently on feature maps extracted on a single image scale
최근에는 Fast R-CNN, Faster R-CNN이 accuracy와 speed의 좋은 trade-off 를 제공하며 단일 scale에서 계산된 feature 사용을 권장. But multi-scale -> still performs better especially for small objects
Methods using multiple layers
FCN -> sums partial scores for each category over multiple-scales to compute semantic segmentations
Hypercolumns -> use similar method to object instance segmentaiton
HyperNet, ParseNet, ION -> concat faetures of multiple layers before compute predictions. (same as summing transformed features)
[[SSD]], MS-CNN -> 특성이나 점수를 결합하지 않고 특성 계층의 여러 layer에서 객체를 예측
최근 방법 -> use lateral/skip connections to associate low-level feature maps across resolutions and semantic levels.
These methods -> It's pyramid shape, but different from faeturized image pyramids(predictions are not made independently at all levels)
Feature Pyramid Networks
FPN’s object : Leverage ConvNet's pyramidal feature hierarchy which has semantics from low to high level and build feature pyramid with high-level semantics throughout.
Input : single-scale image of an arbitrary size
Output : proportionally sized feature maps at multiple levels(in a fully convolutional fasion)
Use top-down pathway, bottom-up pathway and lateral connections to construct pyramid
Bottom-up pathway
Feed-forward computation of the backbone ConvNet (computes feature hierarchy with x2 scaling steps)
Same network stage : Layers which produce output maps of the same size each stage has one pyramid level
Output of the last layer of each stage : reference set of feature maps -> enrich to create pyramid (because deepest layer of each stage have strong feature)
Use feature activations output by each stage’s last residual block for ResNet
Output of last resudual block : {C2,C3,C4,C5} (for conv2, conv3,..) Do not include conv1 into the pyramid due to its large menory
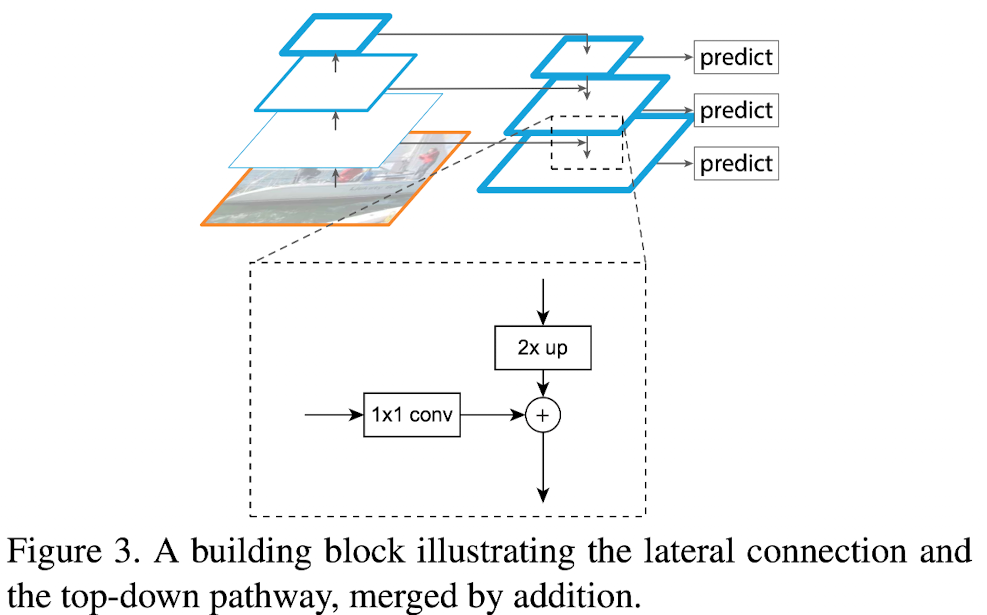
Top-down pathway and lateral connections
상위 피라미드 레벨에서 공간적으로는 더 거칠지만(coarser) 의미론적으로는 더 강한 feature map을 upsampling하여 더 높은 해상도의 feature 생성
lateral connection을 통해 bottom-up pathway의 feature들과 병합
bottom-up feature map : lower level semantics, but activations are more accurately localized
fig shows top-down feature map.
Upsample the spatial resolution by a factor of 2(with coarser feature map) + 1x1 conv to reduce channel dim
upsampled map merged with the corresponding bottom-up feature map by element-wise
iterate this step till feature map become finest resolution map
Apply 1x1 conv to C5 to produce coarsest resolution map
Append 3x3 conv on each merged map to generate the final feature map -> reduce [[aliasing effect]] of upsampling
Final set of feature maps : {P2,P3,P4,P5} , (correspond to C2,C3,C4,C5)
All levels of pyramid use shared clsasifiers / regressors -> fix feature dimension to 256 (every extra conv output channel dim : 256) No non-linearities in extra layers(have minor impacts)
Applications
Feature pyramid Networks for RPN
RPN : sliding window class agnostic object detector on single scale conv feature map, usd 3x3 dense sliding window to evaluate a samll sybnetwork and perform binary classification(object/non object) and bbox regression
network head : 3x3 conv followed by two sibling 1x1 conv for classification and regression
Anchor : object / non object + bbox regression use multiple pre-defined scales and aspect ratios to cover different shape
single scale feature map을 FPN으로 대체 feature pyramid의 각 level에 동일한 디자인의 헤드를 연결
head가 모든 피라미드 레벨의 위치에서 슬라이딩 하기 때문에, 특정 레벨에 multi-scale anchor를 가질 필요 없다. 대신 각 레벨에 단일 스케일의 앵커 할당
define the anchors to have areas of { 32 2 , 64 2 , 128 2 , 256 2 , 512 2 } pixels on { P 2, P 3, P 4, P 5, P 6} respectively.
use anchors of multiple aspect ratios { 1:2, 1:1, 2:1 } at each level.
앵커에 대한 훈련 라벨을 IoU 비율을 기반으로 할당.(0.7 이상일 경우 positive, 전체에 대해 0.3보다 낮으면 negative)
피라미드가 아닌 피라미드의 앵커에 연관성을 가진다.
헤드의 매개변수는 모든 feature pyramid level에서 공유 -> 피라미드의 모든 레벨이 비슷한 semantic level을 공유
common head classifier -> 어떤 image scale에서도 적용될 수 있음.
Feature pyramid Networks for Fast R-CNN
FPN을 Fast R-CNN과 사용하기 위해 각 피라미드 레벨에서 추출된 feature에 대해 RoI pooling 실행 각 RoI에 대해 해당하는 피라미드 레벨에서 feature를 추출하고 이를 Fast R-CNN Classifier에 입력으로 전달 -> 다중 스케일 피처 덕분에 더 나은 성능
Image pyramid 대신 feature pyramid를 유사하게 사용, 단일 scale feature map에서 발생할 수 있는 스케일 민감성 문제를 해결
RoI of width w and height h (on the input image to the network) to the level P k :
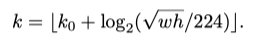
w : width h : height p_k : level 224 : ImageNet pre-training size k_0 : target level(4)
ResNet 기반 Faster R-CNN이 단일 스케일 feature map으로 C4를 사용하는 것과 유사
RoI 의 스케일이 줄어듦 -> 피처 피라미드의 높은 해상도 레벨에 mapping RoI 의 스케일이 커짐 -> 거친 해상도의 피라미드 레벨로 매핑
이를 통해 피처 피라미드를 사용하여 다양한 스케일의 객체에 대해 적절한 해상도의 피처 맵 선택함으로써 정확도와 효율성 향상
모든 레벨의 RoI에 predictor head 부착(class specific)
RoI 풀링을 사용하여 7x7 feature를 추출하고 최종 classifier / bbox regresiosn 전에 ReLU를 적용한 fclayer 적용