
[Paper] MAXIM: Multi-Axis MLP for Image Processing
Abstract
트랜스포머와 MLP모델에 대한 최근의 진전은 CV 작업을 위한 새로운 네트워크 아키텍쳐 설계를 제공하지만, Low-level에서 적용하기에는 여전히 문제가 있다. 이때 주요 문제점은 고해상도 이미지를 지원하기 위한 유연성이 없는점과 local attention의 한계점이다.
본 논문에서는 이미지 프로세싱 task를 위해 효율적이고 유연한 범용 vision backbone 역할을 할 수 있는 MAXIM이라는 multi-axis based 구조를 제안한다.
- UNet모양의 계층 구조를 사용하여 공간 게이트형 MLP에 의해 enable되는 장거리 interaction을 지원한다.
- local 및 global 시각 신호의 효율적이고 확장 가능한 spatial mixing을 허용하는 multi-axis gated MLP와 cross-feature conditioning을 해주는 cross-attention의 대안인 교차 게이트형 블록의 2가지 MLP 기반 블록을 포함한다.
2가지 모듈은 모두 MLP만을 독점적으로 기반으로 하지만 이미지 처리에 좋은 2가지 속성인 global과 fully convolution 모두에서 이점을 얻을 수 있다.
Introduction
기존 모델의 구조 설계 개선 및 ViT 등 최근 연구는 고급 작업에 성공적으로 적용되었지만, 낮은 레벨의 향상 및 복원 문제에 대한 global 모델의 효과는 광범위하게 연구되지 않았다.
낮은 레벨의 vision에 대한 Transformer의 선구적인 연구는 고정된 크기의 비교적 작은 패치에만 수용하는 full self-attention를 직접 적용했다. 이러한 방법은 크롭을 사용하여 더 큰 이미지에 적용될 때 필연적으로 patch 경계 아티팩트를 유발한다.
local attention 기반 transformer가 이 문제를 개선하지만, receptive field의 사이즈가 제한되거나 계층적 CNN에 비해 transformer 및 MLP 모델의 non-locality를 잃게 된다.
이러한 문제를 극복하기 위해 low-level의 vision task를 위한 MAXIM이라는 일반적인 이미지 처리 네트워크를 제안한다.
MAXIM의 key idea는 local 및 global 상호작용을 모두 병렬로 캡쳐하는 multi axis 접근법을 사용하는 것이다.
각 branch에 대해 단일 axis에 대한 정보를 혼합함으로써 이 MLP 기반 operator는 fully convolution이 되고 이미지 크기에 대해 선형으로 확장되므로 고밀도 이미지 처리 작업에 대한 유연성이 크게 향상된다.</span>
또한 동일한 multi axis 방법을 사용하여 MAXIM의 neck에서 skip connection을 적응적으로 연결하여 성능을 더욱 향상시키는 순수 MLP 기반 cross gating 모듈을 정의하고 구축한다.
최근 복원 모델에서 영감을 받아 MAXIM backbone 스택으로 구성된 간단하지만 효과적인 multi-stage,multi-scale 구조를 개발한다.
Key ideas
- multi-scale, multi-stage loss에 의해 감독되는 encoder-decoder backbone 스택을 사용하는 이미지 처리를 위한 새로운 구조 MAXIM
- 이미지 크기에 대해 선형적인 복잡도를 가지고 global receptive field를 사용하는 low-level vision task를 위해 맞춤화된 multi-axis MLP 모듈
- 두개의 개별 기능을 cross conditioning하는 cross gate block이며, 이는 전역적이고 fully convolution이기도 하다.
Method
- 임의의 큰 이미지에서 선형 복잡도를 갖는 글로벌 receptive field를 갖는다.
- 임의의 입력 해상도에 대해 fully convolution을 직접 지원한다.
- 로컬(conv)블록과 글로벌(MLP) 블록의 균형잡힌 설계를 제공하여 대규모 pretraining없이 SOTA 방법 능가.
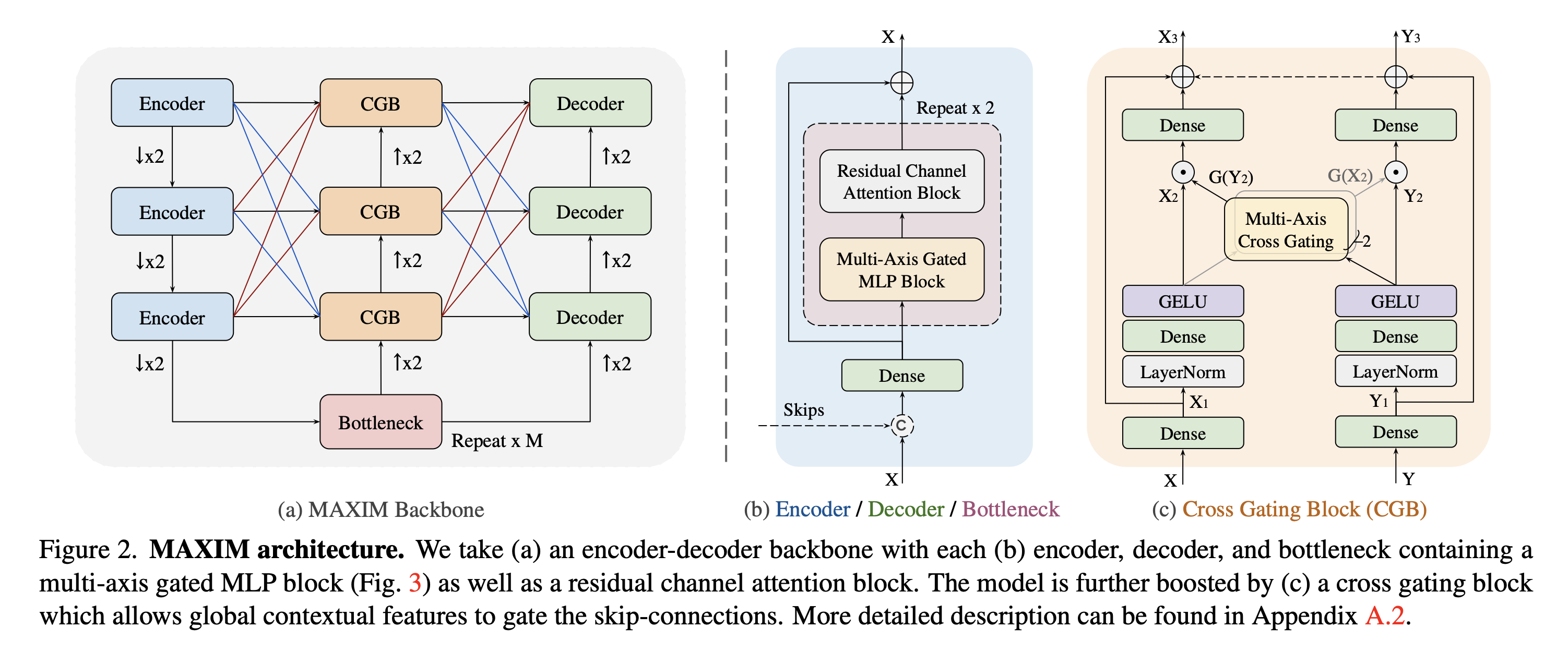
Main Backbone
backbone은 UNet의 encoder-decoder 설계를 따른다.
conv3 * 3 과 같은 작은 footprint의 operator가 UNet과 같은 네트워크의 성능에 필수적이라는것을 관찰했기 때문에, 각 블록에 대한 하이브리드 모델 설계(local - conv, long range interactions - MLP)를 최대한 활용한다.
다른 scale에서 long range spatial mixing을 허용하기 위해, multi-axis MLP블록을 각 인코더 디코더 및 bottleneck에 삽입하고, residual channel attention block(LayerNorm - Conv - LeakyReLU - Conv - SE)가 쌓여있다.
cross attention에 대한 효율적인 2차 대안인 Cross gating block을 구축하기 위해 gate MLP를 확장한다.
bottleneck의 global feature를 활용하여 skip connectoin을 gate하고, 정제된 global feature를 다음 CGB로 전파한다.
Multi-scale feature fusion은 encoder - CGB or CGB - decoder에서 multi-level 정보를 집계하는데 사용된다.
Multi-axis Gated MLP
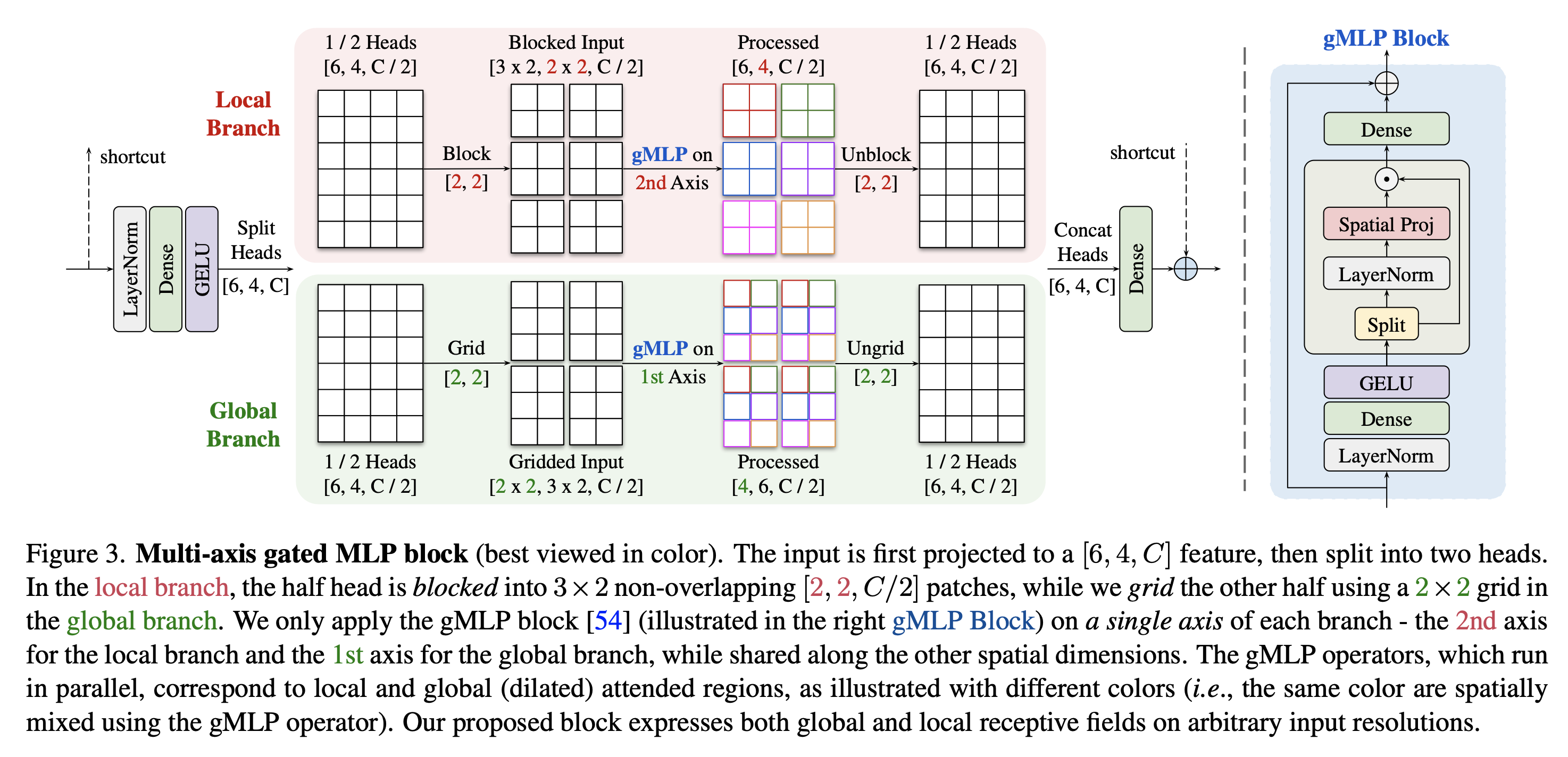
single axis 이상에서 attention을 수행한다.blocked image에 대해 두 축에서 수행되는 attention은 두가지 형태의 sparse self attention, namely regional and dilated attention에 해당한다.
그림과 같이 mulit axis gated MLP block을 구축하여 이미지 처리 작업을 위한 multi axis 개념을 개선.
단일 레이어에 multi axis attention을 적용하는 대신,먼저 head를 반으로 나누고, 각각을 독립되게 분할한다.
local branch:
half of head :
H,W,C/2blocked :
H/b * W/b,b * b,C/2
이는 각각 (b * b)의 크기를 가진 겹치지 않는 window로의 분할을 나타낸다.
global branch:
half of head :
H,W,C/2gridded :
d * d,H/d * W/d,C/2
(d * d)의 grid를 사용하여 격자화되며, 각 창은 (H/d * W/d)의 크기를 가진다.
시각화를 하기 위해, b = 2,d = 2로 설정한다.
fully convolutional하게 만들기 위해, 다른 공간 축에서 매개 변수를 공유하는 동안 각 브랜치의 단일 축에 gated MLP만을 적용한다.(local branch의 2번째 axis, global branch의 1번째 axis).
마지막으로 처리된 헤드는 채널 수를 줄이기 위해 concat되고 project되며 이는 입력에서 long range skip connection을 사용하여 결합된다.
이러한 접근 방식은 패치 경계 아티팩트를 피함으로써 고정 크기 이미지 패치를 처리하는 방법에 비해 모델에 이점을 제공한다.
Cross Gating MLP Block
UNet에 비해 문맥적 feature를 활용하여 skip connection에서 feature propagation을 선택적으로 gate 할 수 있는 장점이 있다.
CGB는 여러 feature와 상호작용하는 보다 일반적인 condigioning layer로 생각할 수 있다.
X,Y를 2개의 입력 feature이라 생각하고, X1,Y1(H,W,C)를 첫번째 dense layer 뒤에 투영된 feature이라 하자.이후 input projection이 적용된다.
multi-axis blocked gating weights는 X2,Y2로부터 계산되지만, 상호적으로 적용된다.(Xhat과 Yhat의 식에 둘다 포함)
마지막으로 우리는 투영행렬 W7,W8을 사용하여 입력과 동일한 채널 size를 유지하는 출력 채널 projection 후 입력에서 redisual connection을 채택한다.
Multi-stage Multi-scale Framework
multi stage framework를 채택했다.
더 강력한 supervision을 부과하기 위해, 네트워크가 학습하는것을 돕기 위해 각 단계에 multi scale 접근 방식을 적용한다. 단계를 따라 점진적으로 attentive feature를 전파하기 위해 감독된 attention 모듈을 활용한다.cross stage feature fusion을 위해 cross gaiting block을 활용한다.
input (H * W * 3)이 주어지면 downscaling을 통해 multi scale variants를 추출한다.
MAXIM은 총 S 단계의 s stage에서 multi scale restored output을 예측하여 총 S * N 출력을 산출한다.