
[Paper] SwinIR : Image Restoration Using Swin Transformer
Abstract
이미지 복원은 오랫동안 낮은 품질의 이미지에서 고품질 이미지를 복원하는 곳을 목표로 헀던 LLCV problem 이다.
본 논문에서는 Swin Transformer 를 기반으로 이미지 복원을 위한 강력한 기본 모델 SwinIR을 제안한다.
SwinIR은 3가지 부분으로 이루어져 있다.
- shallow feature extraction
- deep feature extraction
- high-quality image reconstruction
특히 deep feature extraction 모듈은 여러 개의 residual swin transformer block들로 구성되어 있으며 각 블록에는 residual connection과 함께 여러 swin transformer layer가 포함되어있다.
Introduction
대부분의 CNN기반 학습은 정교한 구조 설계에 중점을 두어 성능이 향상되었지만, 일반적으로 두가지의 문제점을 가진다.
- 이미지와 convolution kernel간의 상호작용은 독립적이다.
동일한 컨볼루션 커널을 사용하여 다른 이미지 영역을 복원하는 것은 최선의 선택이 아닐 수 있다. - local processing의 원칙을 따르므로, 장거리 종속성 모델링에 효과적이지 않다. (kernel의 inductive bias)
CNN의 대안으로 Transformer는 좋은 성능을 보여주었지만, 이미지 복원을 위한 vision transformer는 일반적으로 입력 이미지를 고정된 크기의 패치로 분할하고, 각 패치를 독립적으로 처리한다. 이러한 전략은 2가지의 문제점이 생긴다.
- 경계 픽셀은 이미지 복원을 위해 패치에서 멋어난 이웃 픽셀을 활용할 수 없다.
- 복원된 이미지는 각 패치 주변에 경계 아티팩트를 도입할 수 있다.
Swin Transformer는 CNN과 transformer의 장점을 통합하여, local attention 메커니즘으로 인해 이미지를 큰 크기로 처리할 수 있는 CNN의 장점과, 윈도우 방식으로 장거리 의존성을 모델링 할 수 있는 장점을 ㅏㄱ지고 있다.
본 논문에서는 Swin Transformer를 기반으로 한 영상 복원 모델 SwinIR을 제안한다.
SwinIR은 위에 설명한 3가지 모듈로 구성된다.
- shallow feature extraction
- 컨볼루션 레이어를 사용하여 shallow feature를 추출하고, 이는 저주파 정보를 보존하기 위해 reconstruction 모듈로 직접 전송된다.
- deep feature extraction
- 주로 residual Swin Transformer BLock으로 구성되며, 각 블록은 local attention 및 cross window interaction을 위해 여러 Swin Transformer layer를 사용한다.
- feature enhancement를 위해 블록 끝에 컨볼루션 레이어를 추가하고, feature aggregation을 위한 shortcut을 제공하기 위해 residual connection을 사용한다.
- high-quality reconstruction
- shallow feature, deep feature모두 고품질 영상 재구성을 위해 재구성 모듈에 전달된다.
장점
- 이미지 컨탠츠와 attention weight사이의 콘텐츠 기반 상호작용으로 공간적으로 변하는 컨볼루션으로 해석될 수 있다.
- shifted window 메커니즘에 의해 장거리 의존성 모델링 가능
- 더 적은 매개변수로 더 나은 성능
Method
Network Architecture
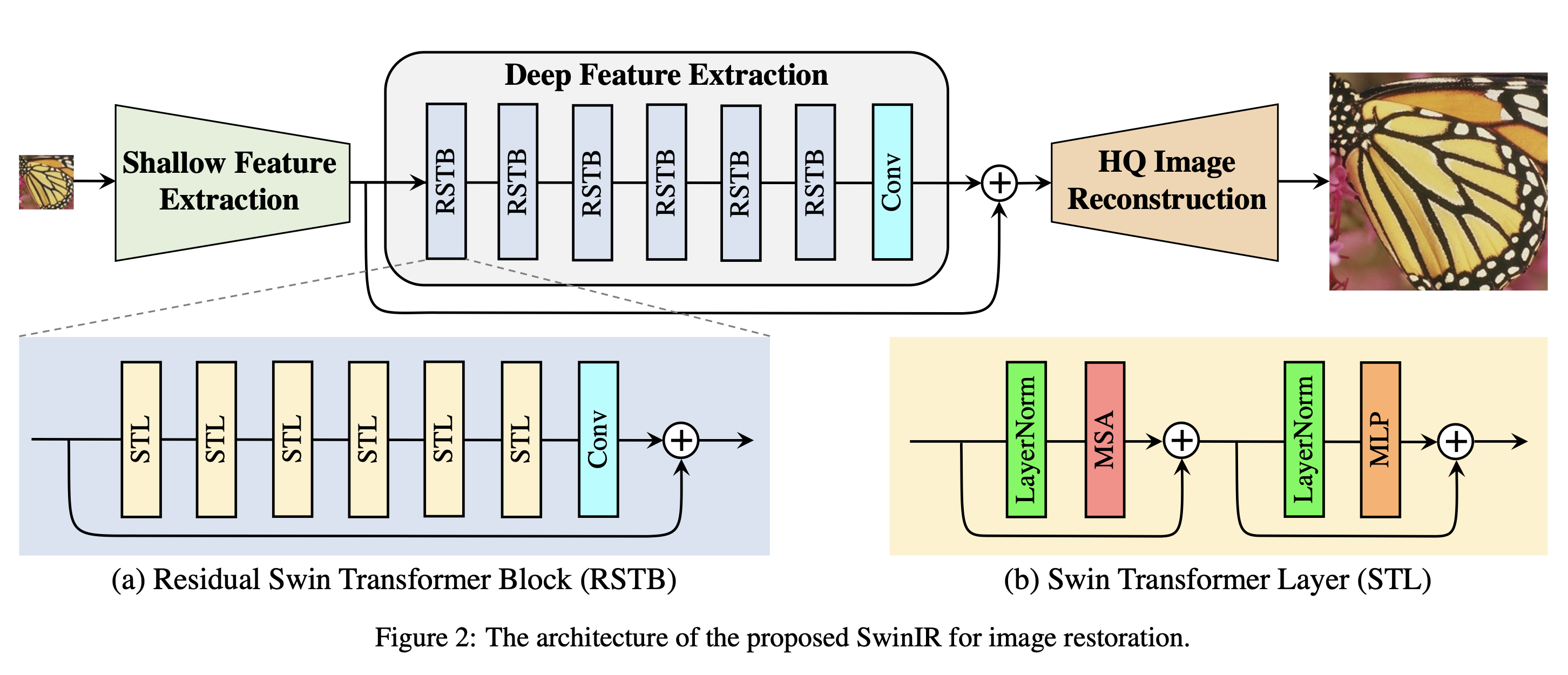
Shallow and deep feature extraction
ILQ : H * W * C
Hsf : 3 * 3 kernel
extracted shallow feature F0 : H * W * C
컨볼루션 레이어는 초기 시각적 처리에 능하여 보다 안정적인 최적화와 더 나은 결과를 제공한다. 또한 입력 영상 공간을 고차원 특징 공간에 매핑하는 간단한 방법을 제공한다. 그런 다음 F0에서 deep feature Fdf를 추출한다.
Hdf : 3 * 3 kernel
extracted deep feature Fdf : H * W * C
여기서 Hdf는 deep feature 추출 모듈이며, k개의 residual swin transformer block 및 3 * 3 컨볼루션 레이어를 포함한다.
중간 feature 및 출력 deep feature는 블록 단위로 다음과 같이 추출된다.
Fi = H_RSTBi(Fi-1) i = 1,2,,,,,K
Fdf = HCONV(Fk)
H_RSTBi : i번쨰 RSTB
Hconv : 마지막 레이어
feature extraction의 끝에 컨볼루션 레이어를 사용하면 컨볼루션 연산의 inductive bias를 트랜스포머 기반 네트워크로 가져올 수 있으며, 나중에 shallow feature와 deep feature의 집합을 위한 더 나은 기반을 마련할 수 있다.
Image reconstruction
I_RHQ = H_REC(F_0 + F_DF)
H_REC : 재구성 모듈의 함수
이미지 SR을 예로 들어, 다음과 같이 두 feature를 종합하여 고품질 이미지 IRHQ를 재구성한다.
- shallow feature : 주로 저주파 포함
- deep feature : 손실된 고주파를 복구하는데 중점을 둔다.
long skip connection을 통해 SwinIR은 저주파 정보를 reconstructoin모듈로 직접 전송할 수 있으므로 deep feature extraction 모듈이 고주파 정보에 집중하고 훈련을 안정화하는데 도움이 될 수 있다.
재구성 모듈의 구현에 있어, 논문에서는 feature를 upsampling하기 위해 sub pixel convolution layer를 사용한다. 만일 이미지 노이즈 제거 및 JPEG압축 아티팩트 감소와 같이 upsampling이 필요 없는 작업의 경우 단일 컨볼루션 레이어를 사용하여 재구성한다.
또한 residual learning을 사용하여 HQ이미지 대신 LQ와 HQ이미지 사이의 residual을 재구성한다.
I_RHQ = H_SwinIR(I_LQ) + I_LQ
loss function
이미지 SR의 경우 L1 pixel loss를 최소화하여 SwinIR파라미터를 최적화한다.
L = | I_RHQ - I_HQ | 1
여기서 I_RHQ는 ILQ를 SwinIR의 입력으로 함으로써 얻어지며, IHQ는 해당 ground-truth 이미지이다.
SR의 경우 제안된 네트워크의 효과를 보여주기 위해 이전 작업과 동일한 L1 pixel loss만 사용한다.
실제 이미지의 경우 pixel loss, GAN loss 및 perceptual loss의 조합을 사용하여 시각적 품질을 개선한다.
이미지 노이즈 제거 및 jpeg 압축 아티팩트 감소를 위해 샤르보니에 손실을 사용한다.
Residual Swin Transformer Block
Swin transformer layer + convolution layer를 갖는 residual block이다.
이러한 설계에는 2가지 이점이 있다.
- Transformer는 공간적으로 변화하는 컨볼루션의 특정 인스턴스로 볼 수 있지만, 공간 불변 필터를 가진 컨볼루션 계층은 SwinIR의 translational equivariance를 강화할 수 있다.
- residual connection은 다른 블록에서 reconstructoin 모듈로의 동일성 기반 연결을 제공하여 다른 level의 피쳐를 집계할 수 있다.
Swin Transformer layer
원래의 transformer layer의 표준 multi-head self attention을 기반으로 한다.
차이점은 local attention과 shifted window 메커니즘이다.
input : H * W * C
partition : HW / M^2 * M^2 * C
각 창에 대해 개별적으로 standard self-attention을 계산.(local attention)
local window feature : M^2 * C
이때 q,k,v는 다음과 같이 계산된다.
Q = XP_Q
K = XP_K
V = XP_V
Q,K,V : M^2 * d
여기서 P_Q,P_K,P_V는 서로 다른 window를 통해 공유되는 투영 행렬이다.
h회 동안 attention feature를 병렬적으로 수행하고 msa를 위해 output을 연결한다.
X = MSA(LN(X)) + X
X = MLP(LN(X)) + X.
그러나 파티션이 다른 계층에 대해 고정된 경우 로컬 윈도우 간의 연결이 없다. 따라서 일반 윈도우 파티션과 shift window 파티션을 교대로 사용하여 교차 윈도우 연결을 활성화한다.