
[Paper] Video Panoptic Segmentation
Method
video는 image와는 다르게 motion context와 temporal한 정보를 같이 가지고 있고, video panoptic segmentation을 위해서는 이를 활용해야 한다.
이 VPS 모델은 다양한 downstream task에 적용할 수 있다.
Overview
모든 class나 instance id에 대한 temporal inconsistency가 panoptic segmentation accuracy를 떨어트린다. 때문에 좀 더 엄격한 requirements 가 필요하다.
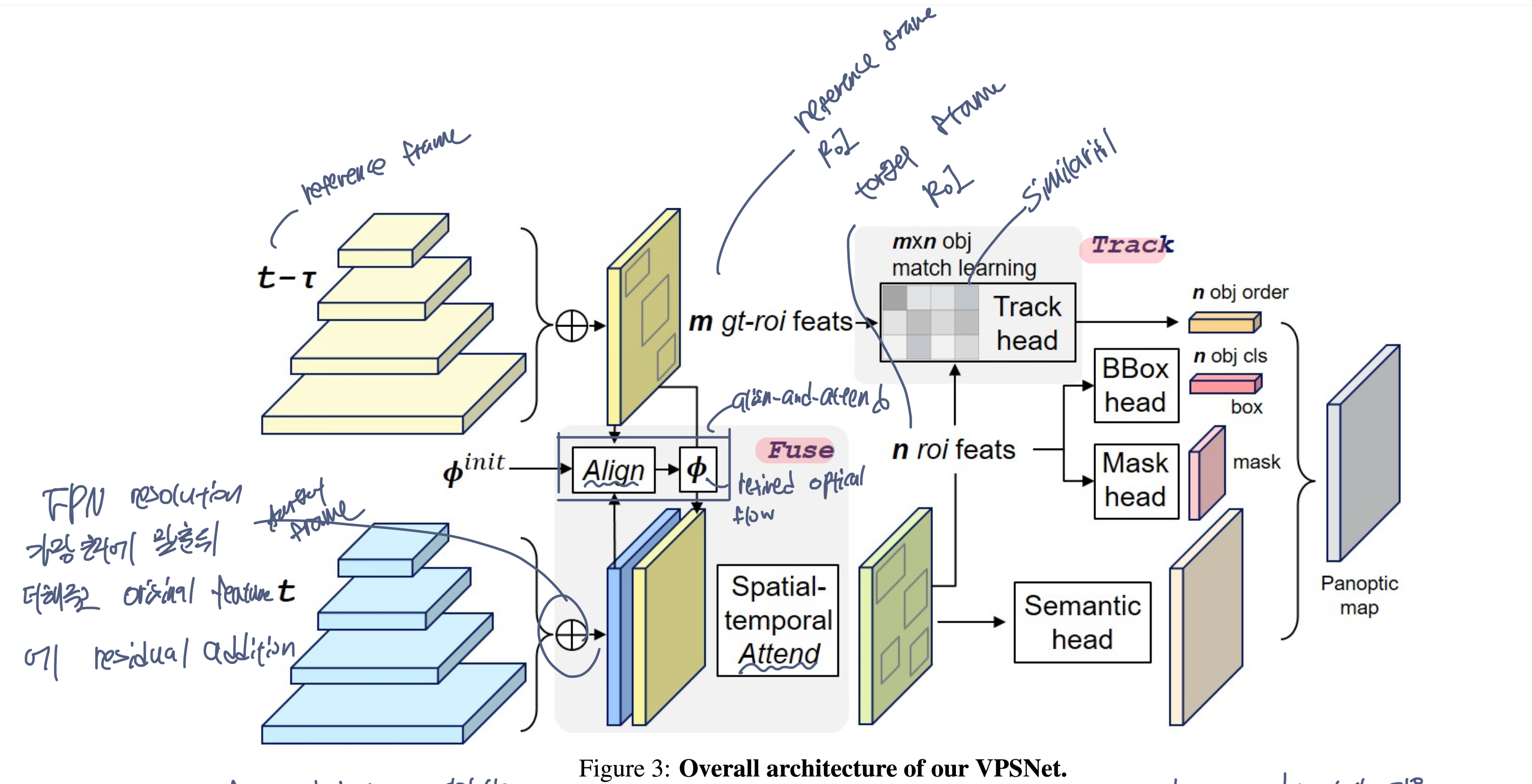
이를 위해 2가지의 중요한 module을 가진 architecture를 구성.
Fuse module
- 이웃한 frame feature들을 합쳐 downstream branch에 적용한다.
Track module
- frame 간 instance들의 연관성을 명시적으로 모델링
여기 사용된 각 모듈은 새로 제안한 것은 아니지만 video panoptic segmentation에 처음으로 적용하였다.
Baseline
전체 baseline network로 UPSNet을 가져와 사용하였다. instance segmentation을 위해 Mask R-CNN을, semantic segmentation을 위해 deformable convolution을 적용한 모델로, panoptic head를 통해 이를 합쳤다.
구체적인 implementation detail
- algorithm을 간단하게 만들기 위해 unknown class prediction을 사용하지 않았다.
-
UPSNet에서는 non-parametric neck layer을 사용하였지만, 논문에서는 gather step과 redistribute step을 사용하는 extra neck을 구성하였다.(논문의 main design purpose가 single resolution level에서 representative feature map을 얻는것이기 때문에 이렇게 구성했다고 한다)
- Gather step
- FPN의 feature들이 가장 높은 resolution으로 resize되어 element-wise sum 수행.
- redistribute step
- 이 representative feature가 original feature로 residual addition을 통해 redistribute된다.
Fuse at Pixel level
- temporal feature fusion을 통해 feature에 video context 정보를 추가하는게 목적
- 각 timestep t에서 target frame($I_T$)와 reference frame($I_{T-\tau}$)의 feature를 뽑아낸다.
- 이후 해당 feature에 대해 FPN을 통해 여러 scale의 feature를 생성한다.
- gather step과 redistribute step 사이에 align-and-attend pipeline을 제안한다.
- 2개의 feature가 주어졌을 때, reference frame으로부터 target frame으로 align하기 위한 flow warping을 학습한다.
- FlowNet2 를 통해 initial optical flow를 받고, 이후 이를 refine한다.
- 이렇게 alignment된 feature를 concat한 뒤, attend module은 feature를 reweight하고 time dimension을 합쳐 $g_t$를 얻기 위한 spatial-temporal attention을 학습한다.
- 이 결과는 FPN의 feature에 residual addition 되고, downstream instance and segmentation branch에 들어가게 된다.
Track at Object level
reference frame에 있는 모든 object instance들을 target frame에서 찾는것이 목적이다.
MaskTrack head
- target frame의 n개의 RoI proposal과 reference frame의 m개의 RoI proposal간의 $m * n$의 feature affinity(유사도) matrix A를 학습한다.
-
각 쌍에 대해 Siamese fully connected layer가 single vector로 만들고 그 결과에 대해 cosine similarity를 계산
- 이 MaskTrack method는 정지된 image를 위해 고안되었고, appearance feature만 사용하는 문제가 있다.(video에는 temporal information이 있기 때문에 이 점까지 활용해야함)
- 이를 위해 논문의 temporal fusion module과 tracking branch를 묶어주었다.
- 모든 RoI feature(target frame의)들은 temporal fused feature에 의해 enhance되고, 이는 여러개의 frame에 대해 진행되기 때문에 discriminative 해진다.
- 결과적으로 instance tracking의 관점에 있어 VPSNet은 pixel level과 object level을 동기화한다.
pixel level
- instance의 local feature를 alignment
object level
- similarity를 통해 target instance를 구분
training은 이전과 같지만 inference시에는 panoptic head를 사용하여 단서들을 추가해준다 (things의 IoU).