
[Paper] XVFI - eXtreme Video Frame Interpolation
Abstract
본 논문에서는 1000fps의 4k 비디오 데이터 세트(X4K1000FPS)를 제시하고, 움직임이 큰 4k비디오의 VFI를 먼저 처리하는 eXtreme VFI network(XVFI-Net)을 제안한다.
두 입력 프레임 간의 양방향 optical flow(BiOF-I) 학습과 target에서 입력 프레임으로의 양방향 optical flow(BiOF-T) 학습을 위한 두개의 계단식 모듈로 구성된 recursive multi-scale shared structure를 기반으로 한다.
optical flow는 BiOF-T모듈에서 제안된 보완적 흐름 반전(CFR)에 의해 안정적으로 근사된다.
추론하는 동안 BiOF-I모듈은 scale에 상관 없이 시작할 수 있고,BiOF-T 모듈은 매우 정확한 VFI 성능을 유지하면서 추론을 가속화할 수 있도록 원래 입력 scale에서만 작동한다.
Introduction
VFI는 주어진 두 연속 프레임 사이에서 하나 이상의 중간 프레임을 합성하여 낮은 프레임레이트 콘텐츠를 높은 프레임레이트 비디오로 변환한 다음 빠른 움직임의 비디오를 증가된 프레임레이트로 부드럽게 렌더링하여 motion judder를 감소시킨다.
하지만 VFI는 폐색, 큰 모션 및 변화와 같은 다양한 요인 때문에 힘든 task이다.
최근의 연구들도 종종 낮은 해상도의 벤치마크 데이터 세트에 최적화 되어있으며, 이는 매우 큰 모션을 가진 4k 해상도 이상의 비디오에서 낮은 성능을 보일 수 있다. 이러한 4k 비디오에는 종종 CNN의 제한된 크기의 receptive field에서 효과적으로 작동하지 않는 픽셀 변위가 매우 큰 빠른 모션의 프레임이 포함되어 있다.
본 논문에서는 이러한 딥러닝 기반 VFI방법의 문제를 해결하기 위해 4k 동영상을 직접 촬영하여 X4K1000FPS 라는 고해상도 고품질 HFR 데이터 세트를 구상했다.
또한 이 데이터세트를 효과적으로 처리하도록 설계된 XVFI-Net이라는 극단적인 VFI 모델을 제안한다.
최근 비디오 추세는 deformable convolution을 사용하여 연속적인 feature 공간을 통해 직접 극단적인 움직임을 캡처하거나 컨텍스트, 깊이, 흐름 및 엣지와 같은 추가 정보를 가진 매우 큰 크기의 pretrained network를 사용하는데, 본 논문에서는 반복적인 다중 scale 공유 구조를 기반으로 하여 간단하지만 효과적이다.
XVFI-Net에는 2가지 모듈이 있다. BiOF_I 및 BiOF_T 모듈은 다중 스케일 손실과 함께 훈련된다. 그허나 일단 훈련되면 BiOF-I 모듈은 하향 조정된 입력에서 위로 시작할 수 있는 반면, BiOF-T 모듈은 추론 시 원래 입력 스케일에서만 작동하므로 계산 면에서 효율적이며 목표 시간 인스턴스에서 중간 프레임을 생성하는데에 도움이 된다.
구조적으로 XVFI-Net은 훈련이 한번 끝나면 입력 해상도 또는 모션 크기에 따라 추론을 위한 스케일 수 측면을 조정할 수 있다.
complementary flow를 취하여 구멍을 효과적으로 채우는 complementary flow reversal이라고 불리는 새로운 optical flow estimation을 시간 t에서 입력의 시간 t까지 제안한다.
key ideas
- X4K1000FPS라는 4k 해상도의 고품질 HFR 비디오 데이터 세트를 제안
- 시간 t에서 입력 프레임까지 안정적인 optical flow estimation을 생성하여 정성적 성능과 정량적 성능을 모두 향상시킬 수 있는 CFR을 제안
- XVFI-Net은 입력 해상도 또는 움직임 크기에 따라 추론 위한 척도의 수 측면에서 조정 가능한 하향 조정된 입력에서 위쪽 방향으로 시작할 수 있다.
Method
X4K1000FPS Dataset
1000fps에서 4k 공간 해상도 4096 * 2160의 팬텀 Flex4KTM 카메라를 사용하여 촬영한 풍부한 4k 1000fps비디오 세트를 제공하며, 5초동안 촬영하여 175개의 비디오 장면을 생성한다.
데이터 샘플을 선택하기 위해 IRR-PWC를 사용하여 장면의 32 프레임마다 양방향 폐색 맵과 optical flow를 측정하였다.
X_TEST : test set
X_TRAIN : train set
XVFI-Net Framework
Design Considerations
XVFI-Net은 HR의 연속적인 두 입력 프레임 I_0와 I_1 사이의 임의의 시간 t에서 중간 프레임 I를 보간하는 것을 목표로 한다.
- Scale Adaptivity
고정된 수의 scale level을 가진 구조는 입력 비디오의 다양한 공간 해상도에 적응하기 어렵다. 각 스케일 레벨의 구조가 서로 다른 스케일 레벨에서 공유되지 않기 때문에 스케일 깊이가 증가한 새로운 구조를 다시 training 해야 하기 때문이다.
input frame의 다양한 공간 해상도의 scale에 적응성을 갖기 위해 XVFI-Net은 desired coarse scale level(원하는 거친 스케일 레벨)에서 시작하는 optical flow estimation이 가능하도록 설계되어 입력 프레임의 움직임 크기에 적응한다.
이를 위해 XVFI-Net은 다양한 스케일 레벨에서 매개 변수를 공유한다.
- Capture Large Motion
XVFI-Net의 feature extractoin block은 두 입력 프레임 사이의 큰 움직임을 효과적으로 포착하기 위해 먼저 두 입력 프레임의 공간 해상도를 strided convolution을 통해 모듈 스케일 factor M만큼 감소시켜 공간적으로 감소된 특징을 산출하고, 이후 두 개의 상황별 feature map C0_0 및 C0_1로 변환한다.
그림의 feature extraction block은 strided convolution과 2개의 residual block으로 구성된다.
그 후 각 scale level에서 XVFI-Net은 대상 프레임 I에서 2개의 입력 프레임으로 optical flow를 M만큼 감소된 공간 크기로 추정된다.
예측된 흐름은 각 scale level에서 입력 프레임을 시간 t로 warp하기 위해 upscaling(*M) 된다.
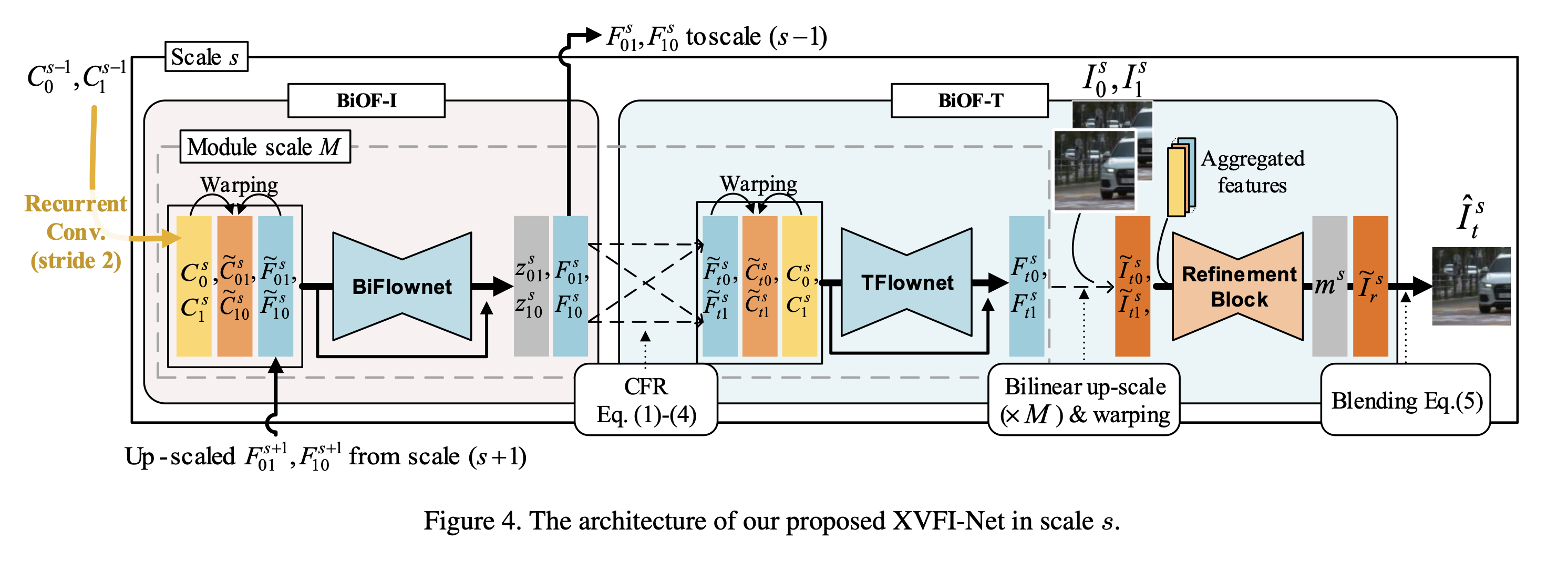
XVFI-Net Architecture
그림은 구조를 scale로 나타낸 것.
- BiOF-I module
먼저 상황별 피라미드(contextual pyramid)c = {c^s}를 stride 2 convoultion을 통해 C0_0 및 C1_0에서 다시 추출한 후 각 scale level(s = 0,1,2…)에서 XVFI-Net의 입력으로 사용한다.(이때 s = 0 은 원래 input frame의 scale을 나타낸다).
- BiOF-T module
optical flow의 flow reverse로 임의의 시간 t에서 flow를 추정할 수 있지만, 몇가지 단점이 있다.
선형 근사는 앵커 포인트가 심하게 잘못 정렬되어있기 때문에 빠르게 움직이는 물체에 대해 예측하는 것은 부정확하다.
반면 flow reverses의 성능을 안정화하기 위해 선형 근사와 flow reverse 모두의 보완적 이점을 사용한다.
따라서 시간 t에서 0 또는 1 까지의 안정적인 optical flow 추정치는 negative의 앵커 flow와 complementary flow의 정규화된 선형 조합으로 계산될 수 있으며, 이를 complementary flow reversal라고 한다.
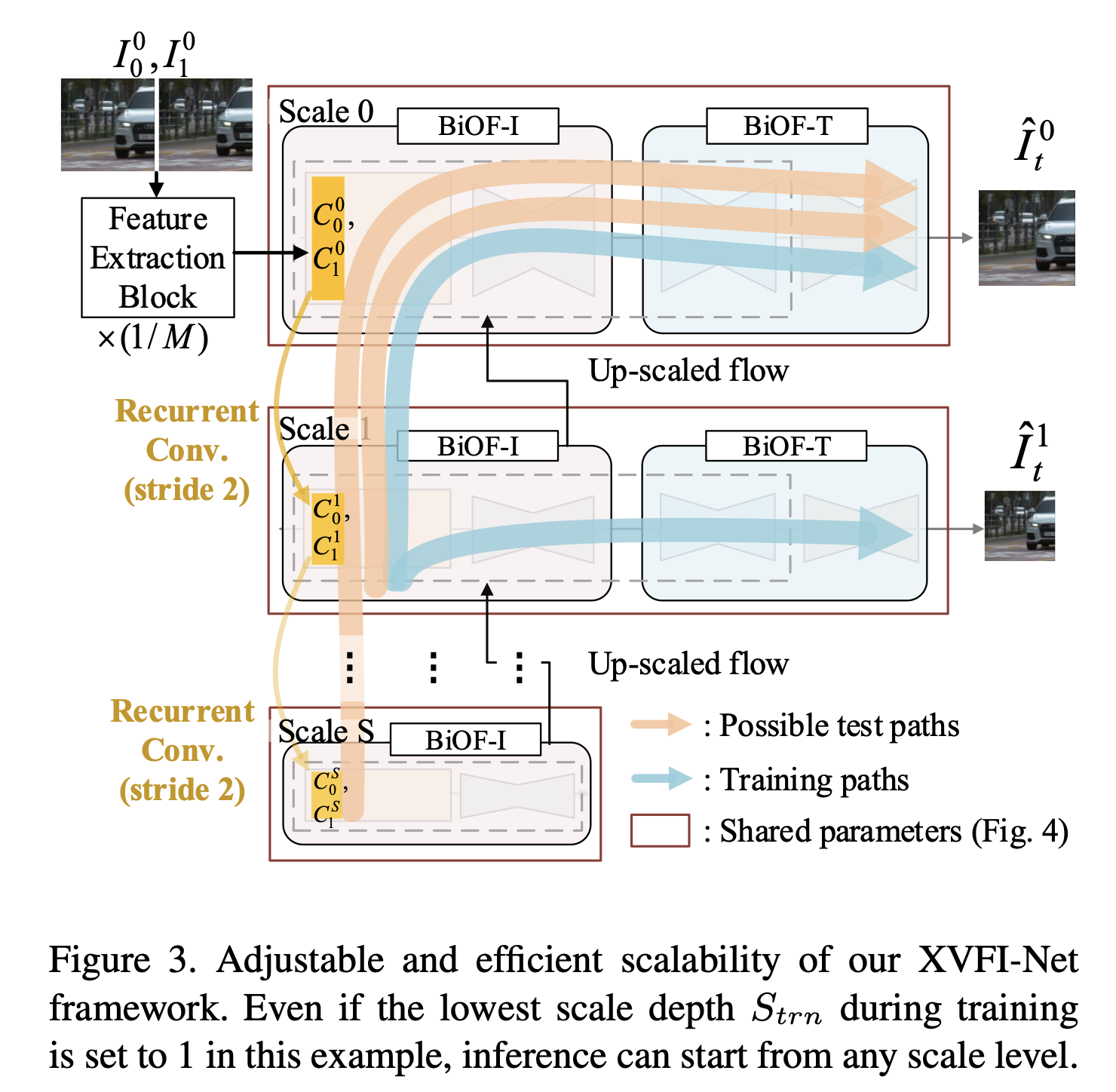
Adjustable and Efficient Scalability
- Adjustable Scalability
그림은 XVFI-Net의 VFI 프레임워크를 보여주며, 상황별 feature map을 1/(2^s) 만큼 반복 downscaling 함으로써 모든 scale level에서 시작할 수 있으며, 가장 거친(coarsest) optical flow를 예측하여 효과적으로 큰 움직임을 포착한다.
그런 다음 추정된 flow는 다음 scale s-1로 전송되고 flow는 원래 scale s = 0으로 점진적으로 업데이트 된다.
본 논문에서는 한번 훈련된 후에도 공간 해상도와 입력 프레임의 움직임 크기 정도에 적응한 추론을 위해 scale의 수를 결정할 수 있는 것을 목표로 한다.
모든 scale level에 대한 학습을 일반화하기 위해, trainingwnㅇ에 선택된 scale level s에 대한 모든 출력 I^s에 대해 multi-scale reconstruction loss를 적용한다.



Loss functions
