
[Paper] mToFNet: Object Anti-Spoofing with Mobile Time-of-Flight Data
Abstract
본 논문에서는 스푸핑 이미지로 인한 피해를 방지하기 위해 Time of Fight 센서와 함께 모바일 카메라에서 제공되는 paired rgb image와 depth map을 사용한 스푸핑 방지 방법을 제안.
두개의 임베딩 모델로 구성된 새로운 표현 모델을 구축하여 recapture된 이미지를 고려하지 않고 훈련할 수 있다.
가장 크고 다양한 객체 스푸핑 방지 데이터 세트인 mToF 데이터 세트를 도입.
Introduction
p2p거래 규모가 증가하면서 판매자가 스캠에 악의적으로 스푸핑 이미지를 사용하여 구매자는 스캠의 위험을 감수해야 할 때가 있다.
이러한 경우를 방지하기 위해 여러 온라인 서비스에서 제공한 방법들은 피할 수 있는 방법이 존재해 불완전하다.
이전의 연구에서는 사람의 얼굴에 초점을 맞추었지만 물체의 경우에는 상품의 다양성으로 인해 대상 물체의 구조적 특성을 활용할 수 없었다.
이러한 문제를 해결하기 위해 이미지와 depth map을 모두 활용하는 새로운 프레임워크 제안.
제안된 프레임 작업에는 실제 이미지의 다중 센서 표현을 학습하기 위한 이중 임베딩 모델이 포함되어 있고 이는 디스플레이 이미지 없이 훈련된다. → moire 패턴 무시 가능하기 때문에 다양한 유형의 스푸핑 매체에 걸쳐 견고성을 향상시킬 수 있다.
key ideas
- 안티 스푸핑 분야에서 mToF센서에 의해 수집된 depth 정보와 이미지를 사용한 최초의 연구
- depth map과 함께 RGB이미지를 사용하여 훈련 단계에서 보이지 않는 디스플레이 임지ㅣ까지 구별할 수 있는 일반화된 스푸핑 방지 방법
- 새로운 데이터 셋 소개
Methods
ToF-based Object Anti-spoofing
- 실제 쌍과 디스플레이 쌍 간의 ToF맵 차이를 관찰하고 ToF맵을 활용한 robust spoofing 방법을 제안.
- 실제 이미지 쌍과 ToF맵은 실제 객체를 캡쳐하여 얻고 디스플레이 쌍은 화면에 표시된 이미지를 recapturing하여 획득.
ToF Frequency Analysis

그림과 같이 moire 패턴은 디스플레이 화면마다 다르게 나타나며 그중 일부는 매우 비슷하여 사람의 눈으로 구별하기 힘들다.
이에 비교하여 ToF맵은 실제와 디스플레이의 뚜렷한 차이점을 보여준다.
이미지와 ToF맵의 특성을 비교하기 위해 주파수 레벨 분석을 수행한다.
먼저 이산 푸리에 변환(DFT)를 적용하여 2차원 이미지와 ToF맵을 크기 스펙트럼으로 변환한다.
이미지 및 ToF맵에서 2D 스펙트럼의 치수를 줄이기 위해 FFT power 스펙트럼을 얻기 위해 Azimuthal 평균을 적용하여 주파수 레벨 2D 스펙트럼을 1D power 스펙트럼으로 변환.
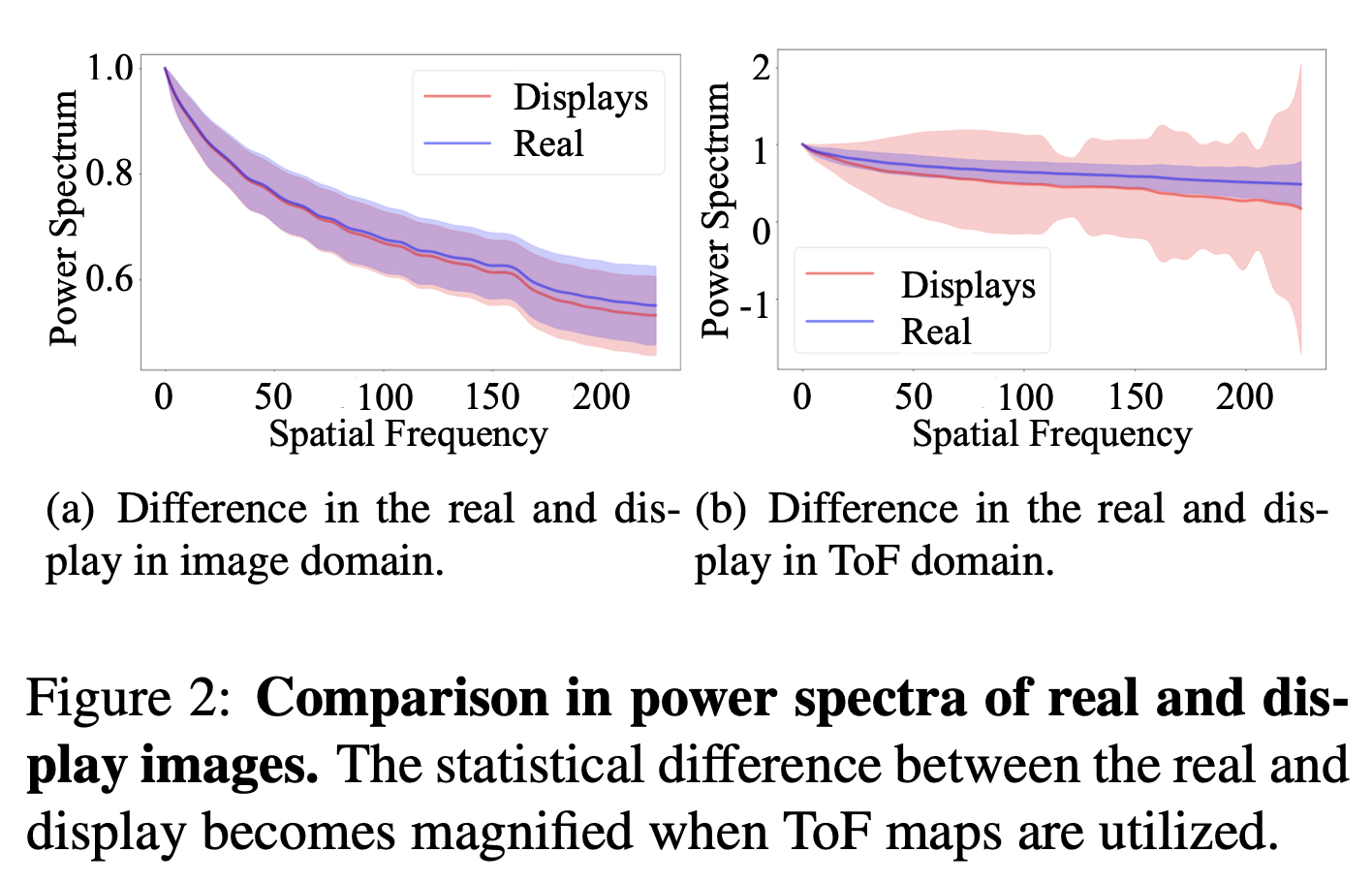
그림은 mToF데이터 세트의 훈련 세트를 사용하여 이미지의 1D power 스펙트럼과 ToF맵 간의 비교를 보여준다.
Overall Framework
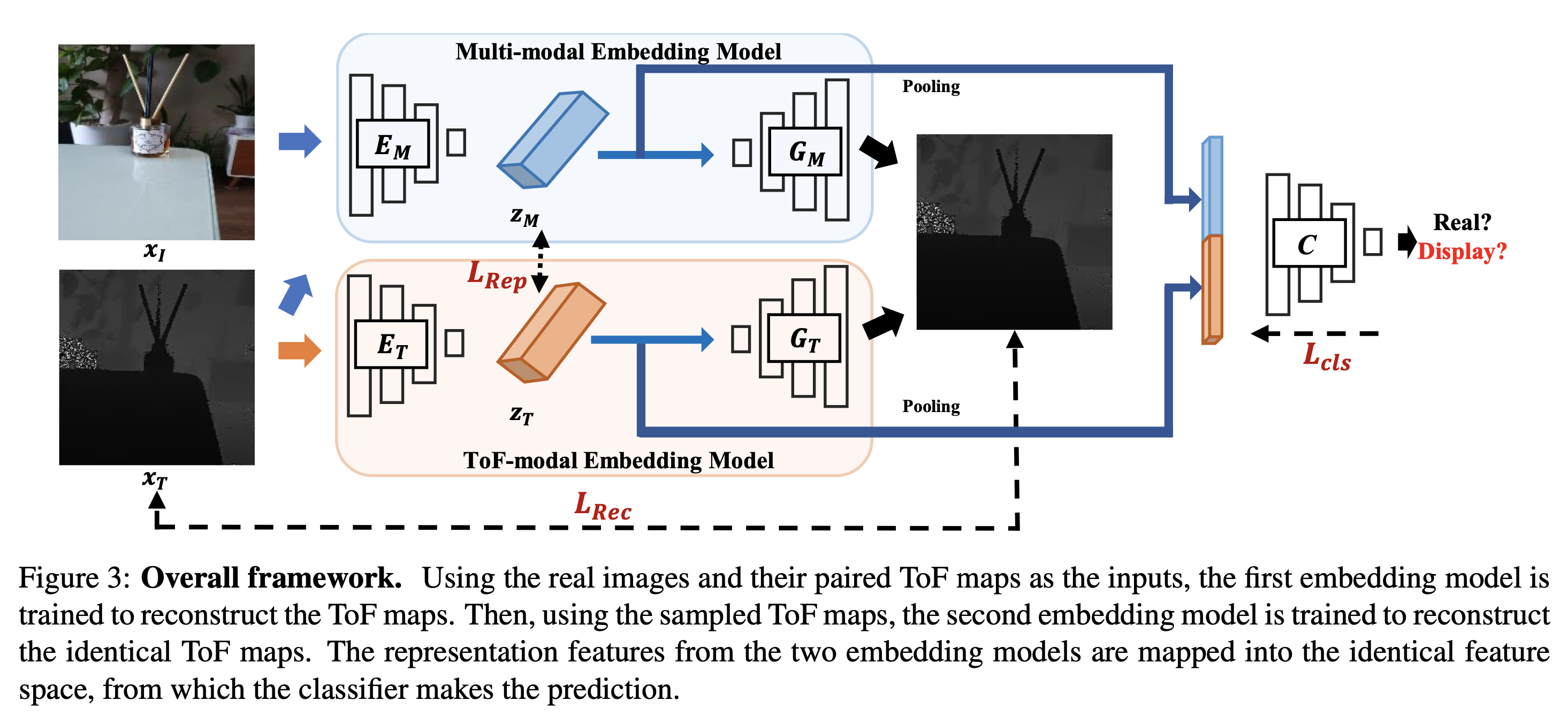
- 이미지와 ToF맵을 포함한 두가지 유형의 양식을 사용하여 moire패턴을 사용하지 않고 실제와 디스플레이 쌍을 구분하는 프레임워크를 설계
훈련 데이터의 moire패턴에 의한 overfitting문제를 극복하기 위해 디스플레이 쌍에는 ToF맵을 사용하고 실제 쌍에는 이미지와 ToF맵이 모두 사용된다.
ToF 표현 네트워크는 실제 쌍과 두 쌍의 데이터 분포를 각각 나타내도록 훈련된 두 개의 개별 임베딩 모델이 포함되어 있다.
- 실제 쌍이 있는 임베딩 모델은 이미지와 ToF맵을 모두 받아 ToF맵을 재구성하는 다중 모드 임베딩 모델이 된다.
- 두 쌍이 모두 있는 다른 임베딩 모델은 ToF-modal 임베딩 모델이 되고 ToF맵만 받는다.
실제 쌍에서 임베딩 모델의 두 표현 특징이 서로 유사하도록 하여 디스플레이 쌍에 대한 표현 특징의 비정상적인 분포를 만들어내었다. 그 다음 임베딩 모델의 두 표현 특징이 스푸핑 분류기에 삽입되도록 연결되어 두 표현 특징의 불일치를 인식하여 디스플레이 이미지를 탐지한다.
ToF Representation Network
입력:
두 임베딩 모델은 각각 인코더와 generator를 포함한다.
임베딩 모델의 인코더는 입력 데이터를 representation feature로 압축하며, 이는 다음 생성기에 의해 입력 ToF맵을 재구성하는데 사용된다.
Spoof classifier
스푸핑 분류기는 실제 및 디스플레이 쌍을 예측하기 위해 latent code간의 유사성을 기반으로 두 임베딩 모델의 표현 특징을 비교한다.
두 임베딩 모델의 출력을 concat하여 입력으로 받는다.
연결된 feature를 실제 및 디스플레이 쌍 중 하나로 분류하기 위해 여러 개의 fc layer로 구성되어 있다.
mToF Dataset
최근 여러 제조업체가 모바일 장치에 ToF센서를 장착하기 시작했다.
논문의 mToF 데이터셋은 이전 객체 안티 스푸핑 데이터 세트의 크기와 다양성의 제한을 극복하고 이 연구 분야에서 처음으로 추가적인 ToF 데이터를 제공하기 위해 수집된다.
Data Composition
object category:
또한 16종의 다양한 스푸핑 미디어를 사용하고 있다.
On-device Refinement of ToF Maps
ToF센서로 캡쳐된 raw ToF맵은 여러 카메라 기능으로 인해 영향을 받는 수많은 아티팩트와 노이즈로 인해 정제 과정이 필요하다.
ToF 맵으로 쌍을 이룬 이미지를 캠처한 후 안드로이드2에서 제공하는 API가이드에 따라 모바일 어플리케이션 내에서 데이터를 정제한다.
- 이미지 해상도 : 1280 * 720
- ToF맵 해상도 : 240 * 180
Pre-processing of Paired Images
- RGB 이미지와 깊이 맵의 비트 스케일을 동일하게 하기 위해 depth map의 비트 스케일을 0~255의 8비트로 변환한다.
- 모든 RGB 이미지와 깊이 맵의 크기를 캡처된 데이터 중 가장 작은 이미지 길이인 180 * 180으로 조정한다.
- 동일한 대상 개체와 동일한 유형의 디스플레이로 캠쳐된 샘플을 샘플 세트로 그룹화
- training set : 80%
- validation set : 10%
- test set : 10%