
[Paper] Attention is all you need
Attention is all you need
Abstract
sequence transduction model 는 복잡한 recurrent 또는 encoder,decoder 를 포함한 CNN을 기반으로 하고 있다. 최고의 성능을 가진 모델 또한 encoder decoder를 attention 매커니즘을 통해 연결시켰다.
우리는 recurrent 와 convolution을 제거한 attention 매커니즘에만 의존하는 새롭고 단순한 네트워크 구조를 제공한다. 두개의 machine translation task에 대한 실험은 이러한 모델이 병렬 가능하고 학습에 상당히 적은 시간을 들여 이전의 model을 능가하는 성능을 보여준다.
Transformer가 크고 제한된 train data 로 영어 문법 해석에 성공적으로 적용됨으로써 다른 task에도 일반화가 잘 되는것을 보여주었다.
Introduction
RNN,LSTM,GRU는 언어 모델링 및 machine translation과 같은 sequence modeling 문제에서 확고히 자리를 잡았다.
하지만 recurrent model들은 학습 시 t 번째 hidden state 를 얻기 위해서 ht−1(t번쨰 hidden state)를 사용했다.
이러한 구조는 long-term dependency에 취약하고, 병렬 처리를 할 수 없다는 문제점이 있다.
Long-term dependency
- 은닉층의 과거의 정보가 마지막까지 전달되지 못하는 현상
- 길이가 긴 문장을 만들 때, 연관 단어(정보) 사이의 거리가 멀다면 다른 단어를 사용하여 만들 수 있다.
- transformer 는 attention mechanism 만을 사용해 input 과 output의 dependency를 잡아냈다.
Parallelization
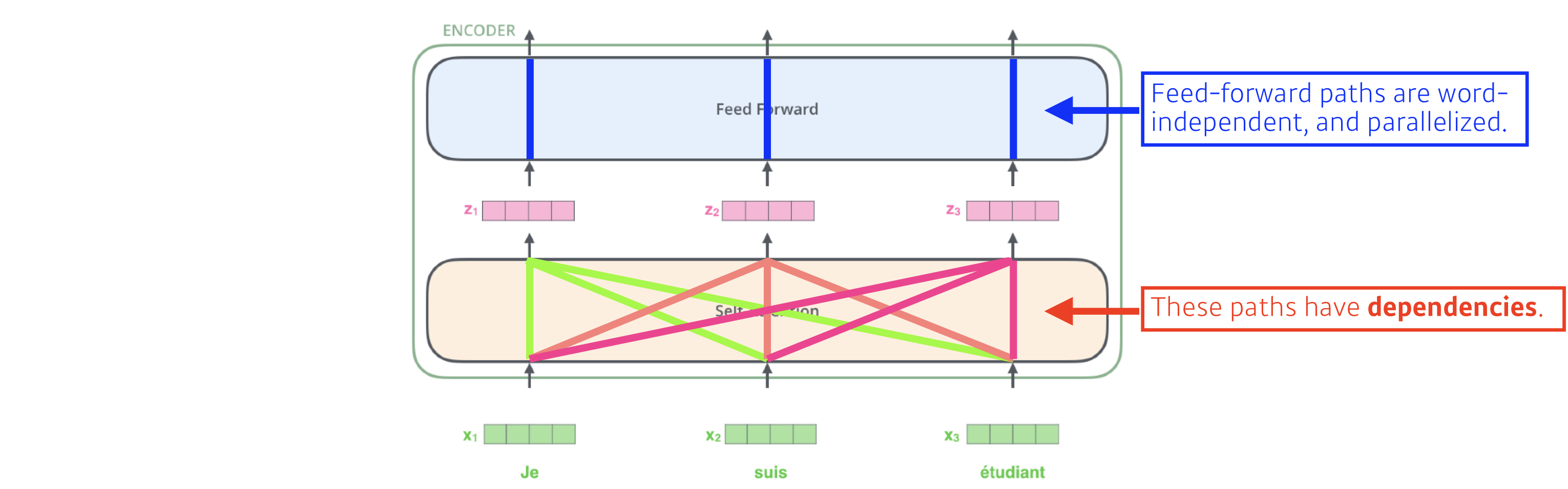
- recurrent model의 순차적인 특징 때문에 병렬 처리가 불가능하고 계산 속도가 느렸다.
- transformer에서는 학습 시 encoder에서는 각각의 단어(position) 에 attention만 해주고, decoder에서는 masking 기법을 사용하여 병렬 처리가 가능하다.
이 논문에서는 encoder-decoder 구조를 사용해 2개의 문제점을 해결하였다.
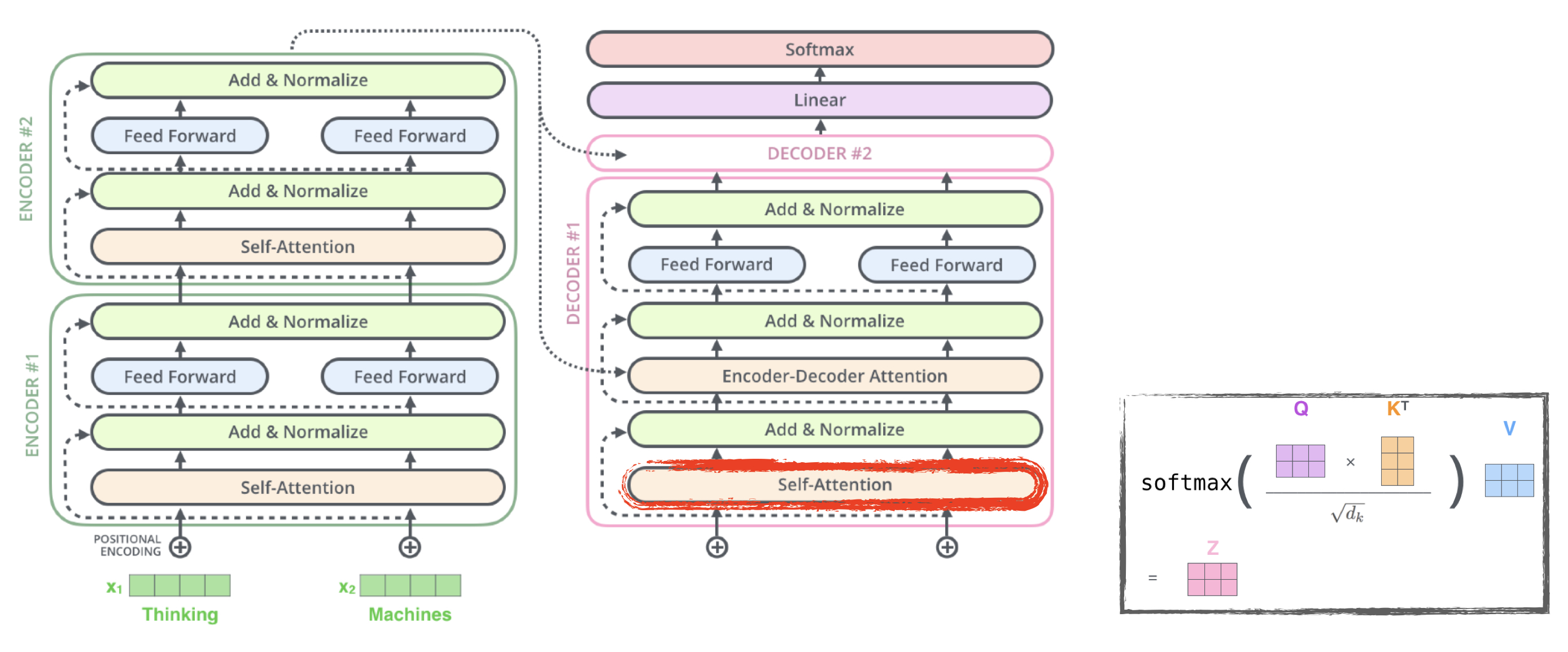
Model Architecture
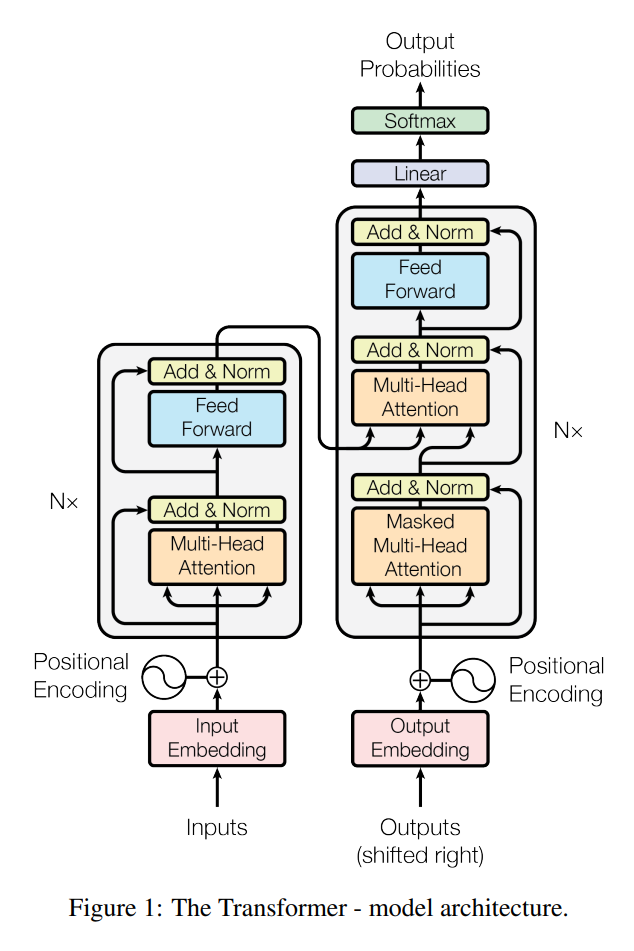
Encoder and Decoder structure
- encoder는 input sequence(x1, …, xn)를 z = (z1, …, zn)의 연속적인 representation으로 바꿔준다
- decoder는 z를 받아 output sequence of symbol(y1, …, ym)을 하나씩 만들어낸다.
- Auto-aggresive : 이전에 만들어진 symbol을 새로운 input으로 사용하여 다음 symbol 을 만들어낸다.
Encoder and Decoder stacks
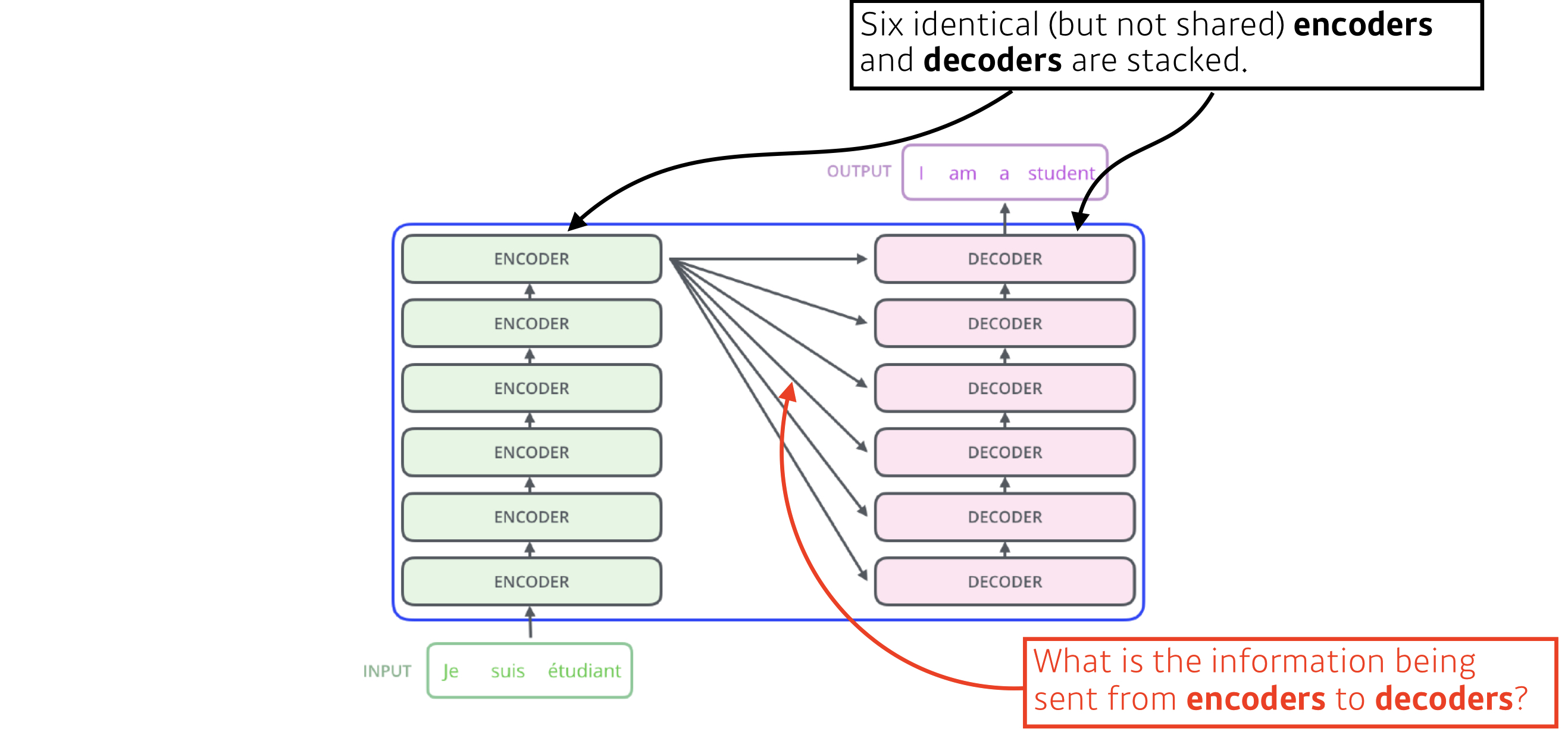
Encoder
- N(6)개의 동일한 layer로 구성되어있다.
- 각각의 layer는 2개의 sub-layer를 가지고 있다.
- multi-head self-attention
- position wise fully connected feed forward network
- 2개의 sublayer 각각에 residual connection과 layer normalization을 적용한다. residual connection은 input을 그대로 output으로 전해주는 역할인데, 이때 x + Sublayer(x)를 위해서는 sub-layer의 output dimension을 embedding dimension(512) 로 맞춰준다.
Decoder
- N(6)개의 동일한 layer로 구성되어있다.
- encoder의 구조에, encoder의 결과에 multi-head attention을 수행할 sub-layer를 추가한다.
- 각각의 sub-layer에 residual connection과 layer normalization을 적용한다.
- Masking: decoder에서는 self-attention sub-layer를 변형하여 뒤쪽 position이 관여하지 못하도록 한다

- position i 에 대한 예측은 i 보다 작은 위치의 output만 사용한다.
Attention
- 특정 정보에 조금 더 주의를 기울이는 것.
- query 와 set of key-value 를 ouput에 mapping.(이때 query, keys, values, output은 벡터)
- output은 weighted sum으로 계산되고, 각 value에 할당된 가중치는 해당 key와의 compatibility function 으로 계산된다.
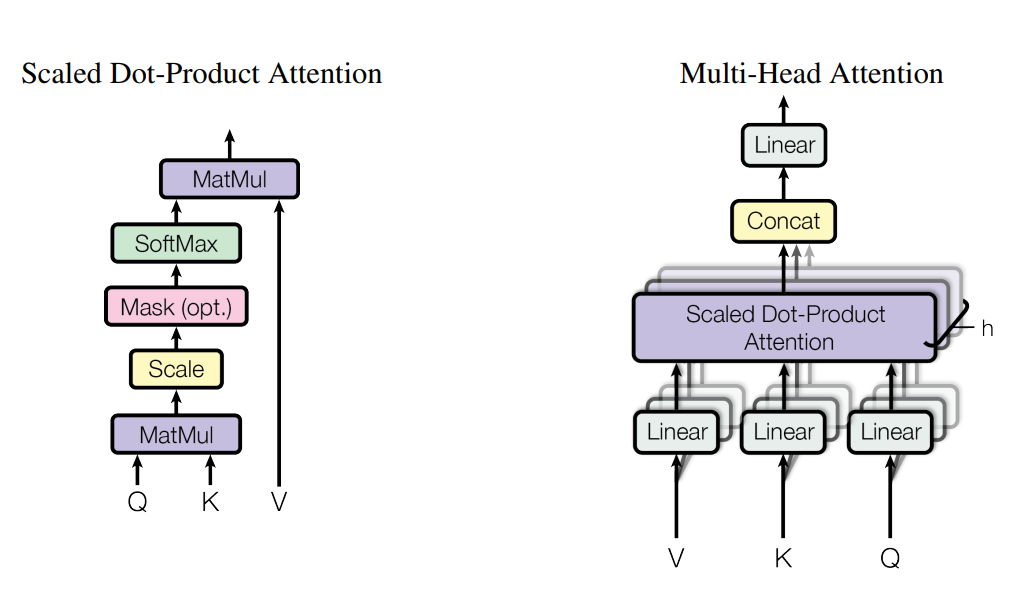
Scaled Dot-Product Attention
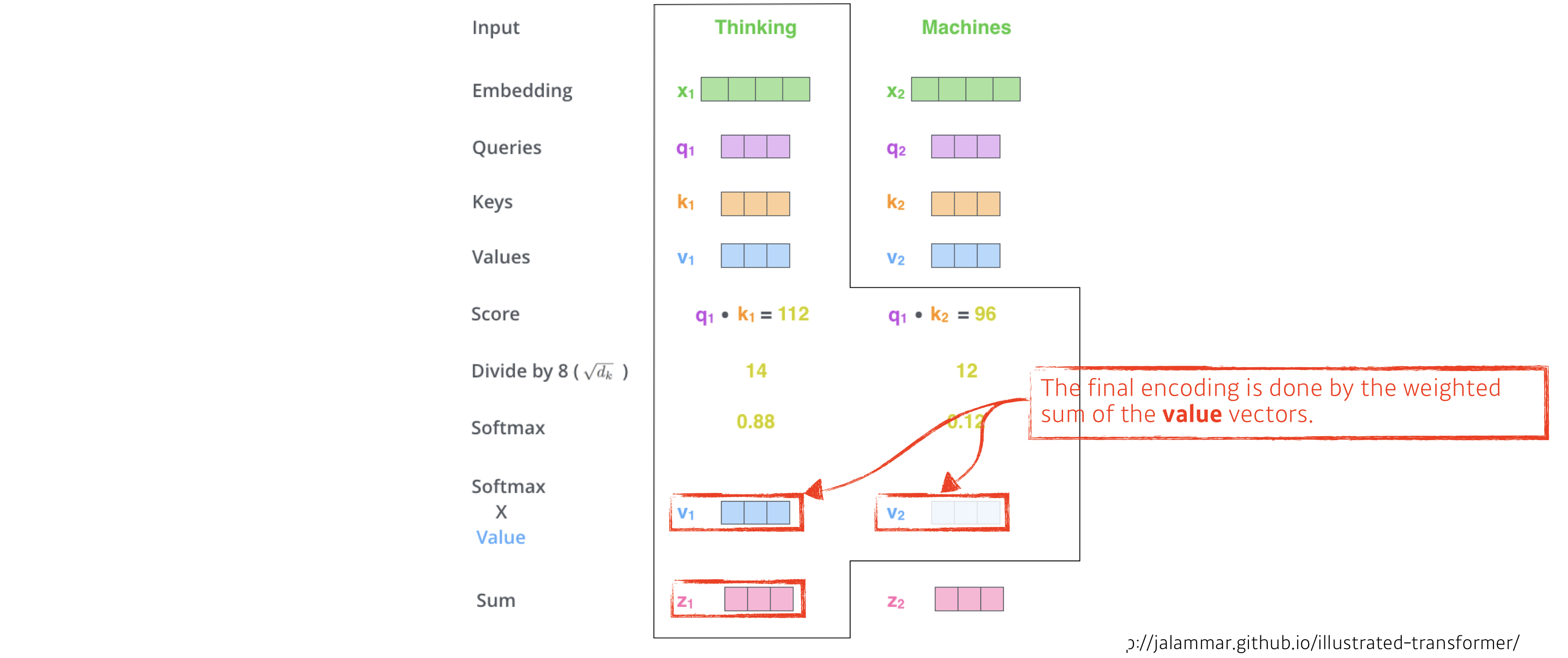
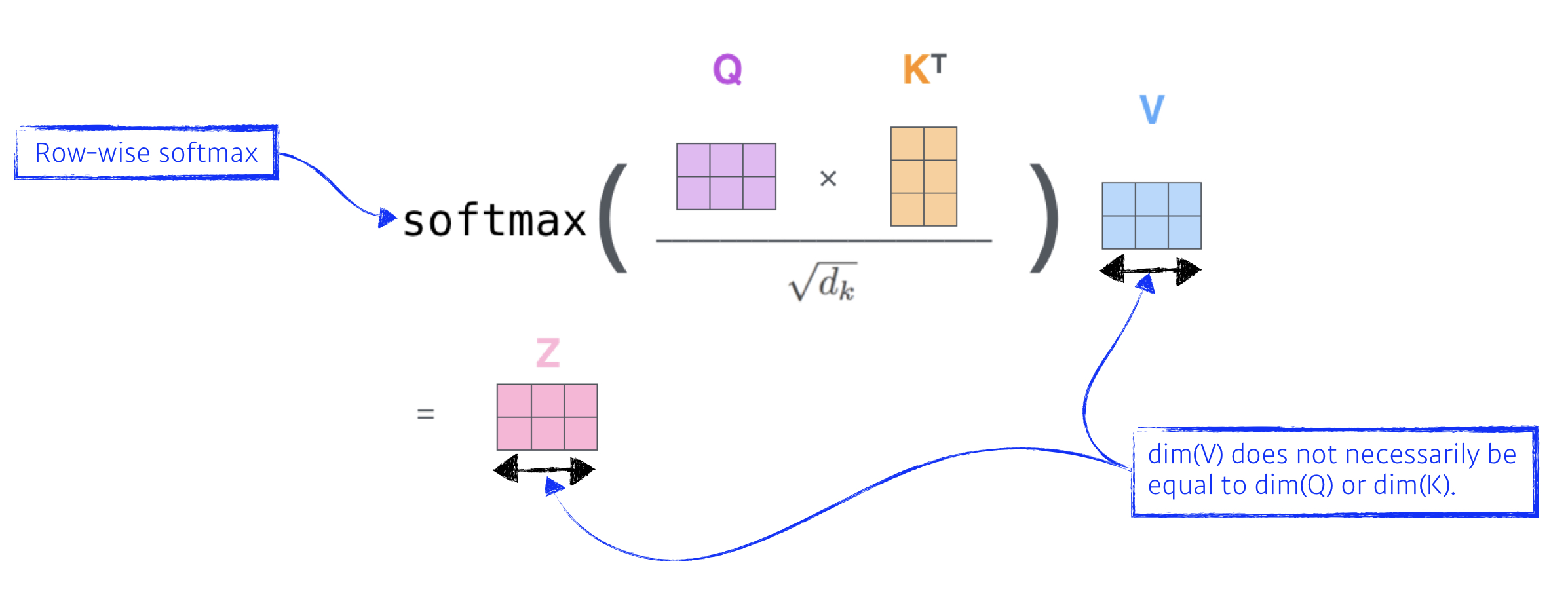
- 해당 논문의 attention.
- input은 dk dimension의 query와 key들, dv dimension의 value들로 이루어져 있다.
- 먼저 query와 key의 dot product 를 계산한다. 위의 식에서는 행렬의 곱을 나타내기 위해 k를 전치하였다. 그 후 √dk로 나누어준다.
- softmax를 적용하여 value 에 대한 weight를 얻어낸다.
- query와 key의 dot product는 각각의 query 와 key 사이의 유사도를 의미한다.
- √dk로 scaling을 해주는 이유는 dot product 의 값이 커질수록 softmax 함수에서 기울기의 변화가 거의 없는 부분으로 가기 때문이다.
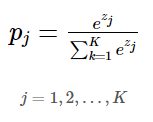
Multi-Head Attention
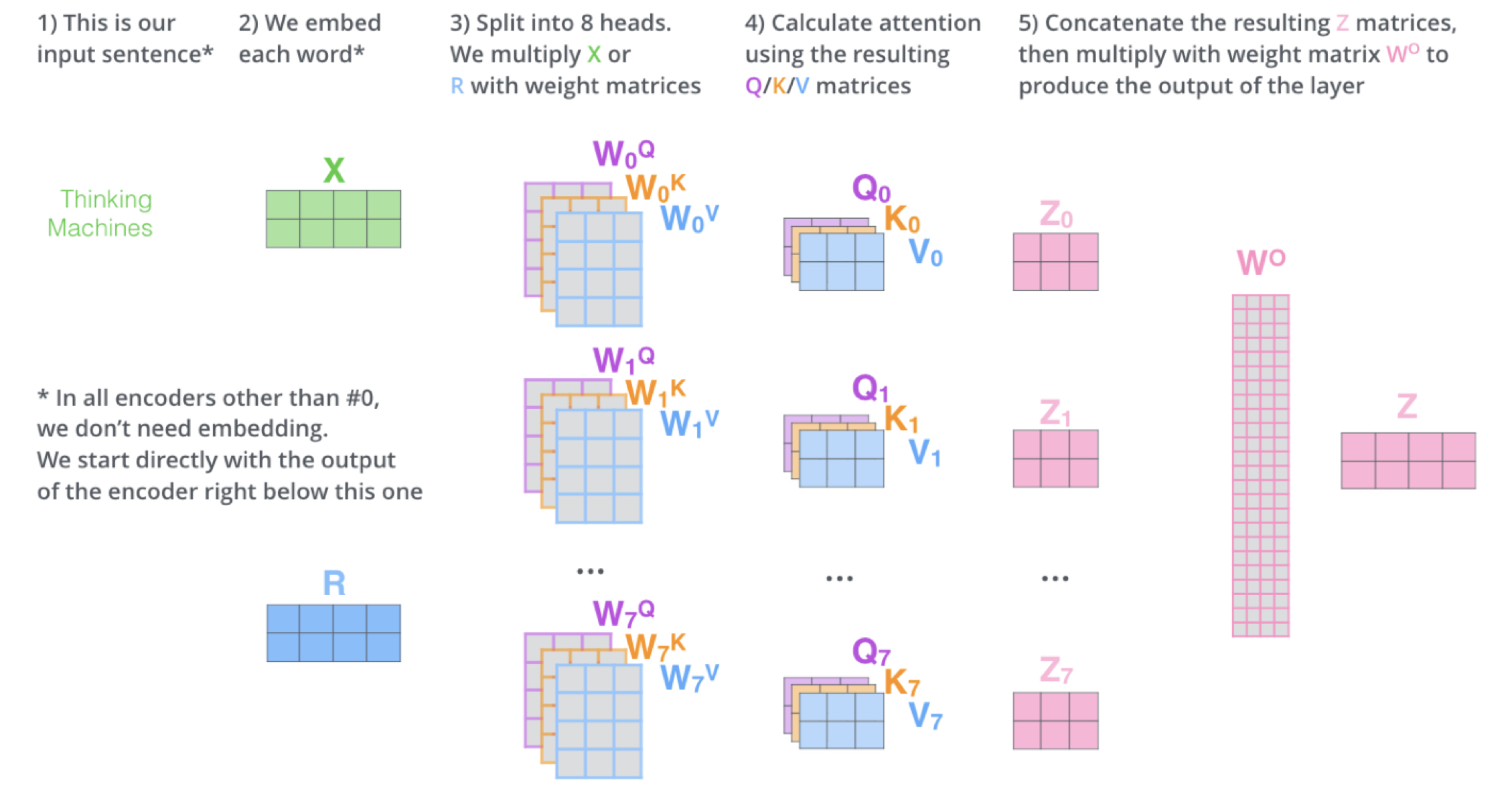
- 한번의 attention을 수행하는 대신 k,q,v 에 각각 다른 학습된 linear projection을 수행하는게 더 좋다고 한다.
- q,k,v 들은 병렬적으로 attention head 에서 attention function을 거쳐 dv dimension output으로 나오게 된다.
- 그 다음 attention 을 계산하여 concat 한 뒤 prohection을 수행한다.
Self attention
Encoder self-attention layer
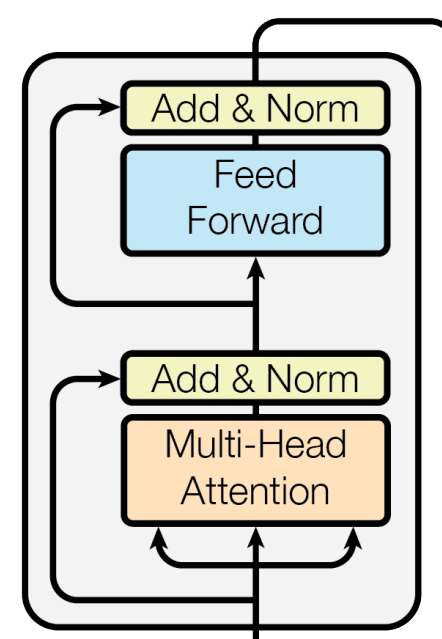
- 입력으로 들어오는 key,query,value 들은 모두 encoder 의 이전 layer 에서 가져온다. 만약 첫번째 encoder layer 라면 입력은 positional encoding이 더해진 input embedding이 된다.
Decoder self-attention layer
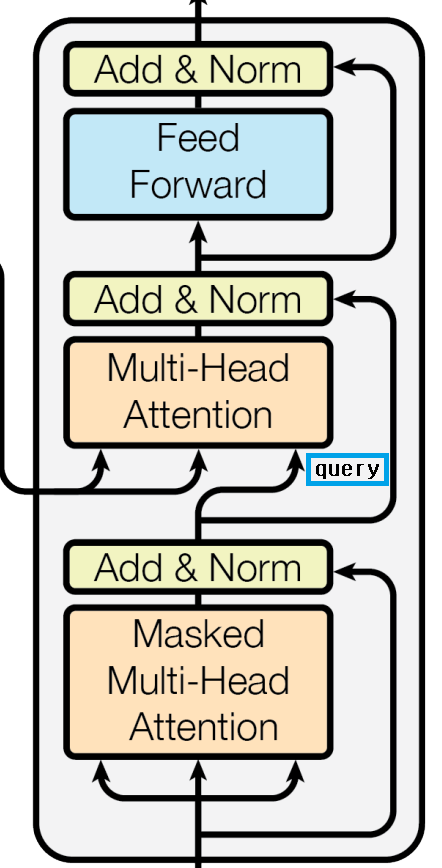
- key,value 는 encoder 의 output에서 나오게 되고 query 는 이전 decoder layer에서 나오게 된다. 이를 통해 모든 position에서 encoder output의 모든 position에 attention을 줄 수 있게 된다.
- query 는 이전 layer에서 masking out 된 상태이다. (Masked multi-head attention) 때문에 i 번째 position 까지만 attention을 얻게 된다.
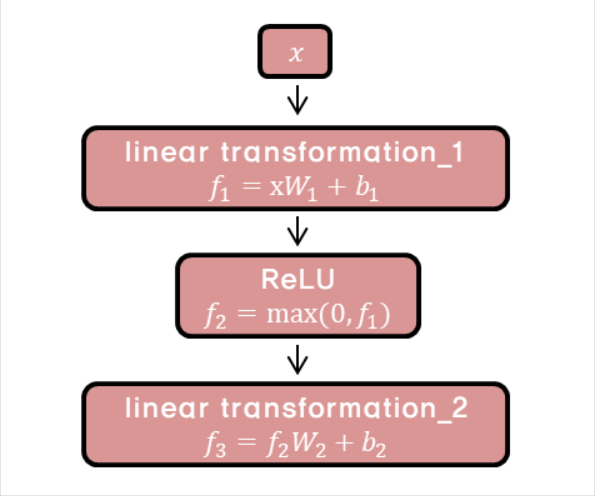
Position-wise Feed-Forward Networks
- encoder 와 decoder 에는 fully connected layer가 포함되어 있다.
- 여기서 position-wide 인 이유는 이 fc layer가 개별 단어마다 적용되기 때문이다.
- 2번의 linear transform 과 ReLU activation function으로 이루어져 있다.
Positional Encoding
- 단어를 sequential 하게 넣어도 sequential 정보는 포함되지 않는다.
- 단어의 position 에 대한 정보를 넣어주기 위해 사용.
- encoder 와 decoder의 input embedding에 positional encoding을 더해준다.
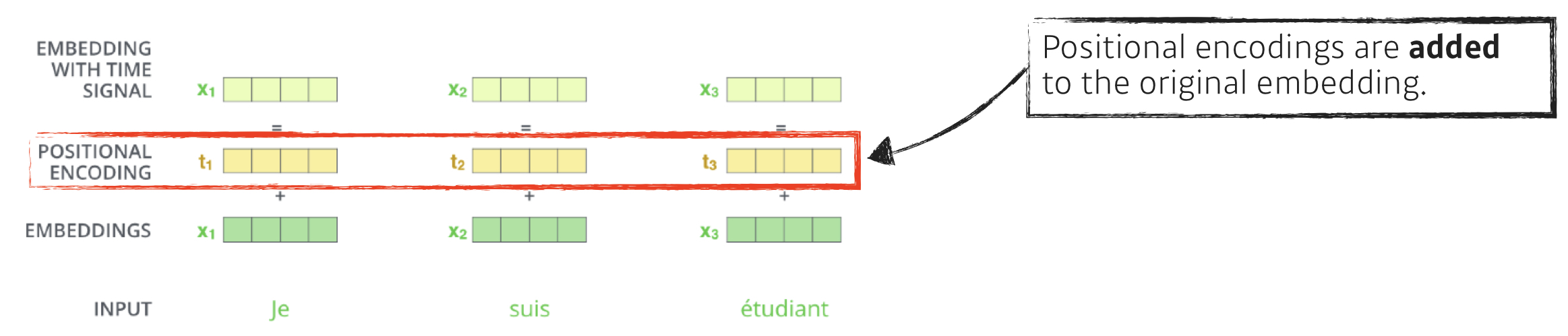
- 하지만 positional encoding은 dmodel(embedding 차원)과 같은 dimension을 가지기 때문에 input embedding 과 더할 수 없다.
- 이 논문에서는 다른 주파수를 가지는 sine 과 cosine 함수를 사용했다.
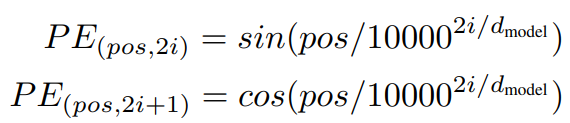
- pos : position, i : dimension
- pos는 sequence에서 단어의 위치이거 해당 단어는 i에 0부터 dmodel/2 까지를 대입해 dmodel 차원의 positional encoding vector를 구해낸다.
- k가 2i + 1 일때는 cosine, 2i 일때는 sine 함수를 사용한다.
Training
Optimizer
- Adam 을 사용하였다.
- learning rate를 다음 식에 따라 변환
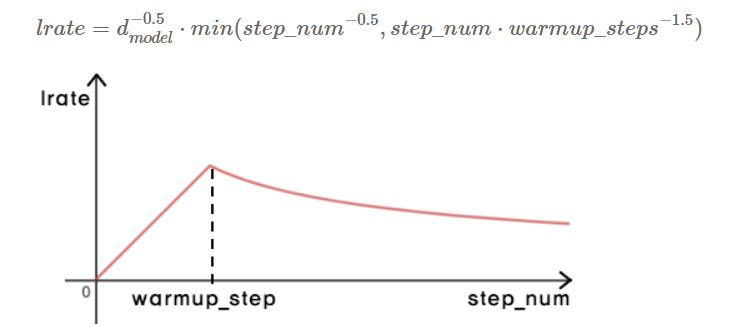
- warm_up step = 4000
Regularization
-
- Residual Connection
- Layer Normalization
- gradient 가 explode 혹은 vanishing 하는 문제 해결
- Dropout
- neural network 에서 unit을 drop 하는 방법(randomly selected)
- drop된 unit은 training에서 제외됨으로써 overfitting 문제 해결
- Label Smoothing