
[Paper] RetinaNet
Focal Loss for Dense Object Detection
모델이 예측하기 어려운 hard example 를 집중적으로 다루는 Focal Loss
Abstract
object detection task 는 크게 2가지로 구분된다
-
one-stage detector : Regional Proposal 과 classification이 동시에 이루어진다
비교적 빠르지만 정확도가 낮다
-
two-stage detector : Regional Proposal 과 classification이 순차적으로 이루어진다
비교적 느리지만 정확도가 높다
이 논문에서는 왜 one-stage 정확도가 낮은지에 대해 고찰하였다.
one-stage detector의 정확도가 낮은 이유
two-stage detector는 먼저 object가 존재할 확률이 있는 region proposal 을 생성하거나, 휴리스틱 sampling 을 사용하기 때문에 imbalance에 대해 덜 민감하지만, one-stage는 동시에 일어나기 때문에 data의 극단적인 imbalance가 이러한 낮은 정확도를 만들어낸다. (물체에 비해 배경의 수가 더 많기 때문)
이를 해결하기 위해 Cross Entropy Loss 를 reshape 한 Focal Loss 를 제시하였다.
Focal Loss
분류하기 쉬운 문제(Easy Negative Examples) 보다 어려운 문제(Hard Positive Examples)에 더 많은 가중치를 적용하여 object 검출에 더욱 집중하였다
object detection task 의 경우
- Easy Negative Examples : backgrounds
- Hard Positive Examples : object(foreground)
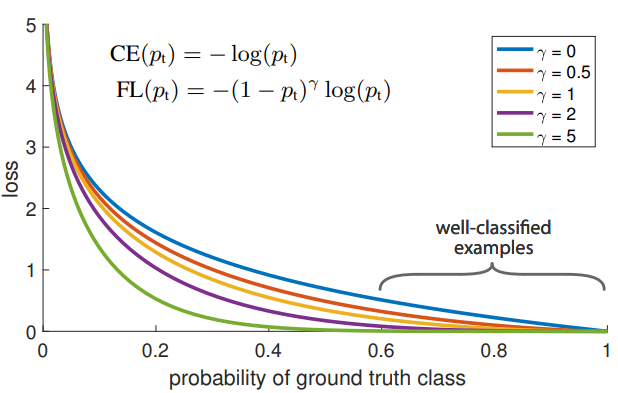
- : Focal loss
- : 기존 loss function
사진을 통해 정답일 확률이 높은 예측에는 0에 가까운 loss가 부가된다.
Retinanet
- Focal Loss 를 사용한 Dense detector
- one-stage detector
- 속도가 빠르고, state-of-the-art-two-stage detector 보다 정확도가 높다
Introduction
현재의 SOTA 모델은 two-stage 모델로, region proposal driven 메커니즘을 가지고 있다.
예를 들면 FPN,Faster R-CNN 등이 있는데 first stage에서는 region proposal 을 생성하고, second stage 에서는 region의 class를 CNN을 사용하여 예측하는 단계를 거친다.
위에서 설명했듯이 object가 존재할 확률이 높은 region을 먼저 찾아내기 때문에 one-stage detector의 foreground,background 간의 imbalance 문제점에 대해 덜 민감하다.
이 논문에서는 one-stage detector 에서 발생하는 class imbalance 를 해결하기 위해 Focal Loss 와 RetinaNet을 제시하였다.
Focal Loss
- : Focal loss
- : 기존 loss function
기존의 Cross Entropy Loss에 factor를 적용하여 감마가 0보다 커질수록 잘 검출한 물체와 아닌 물체 사이의 loss 값 차이를 크게 하였다.
이를 통해 train 시에 object 검출에 더욱 집중한다.
RetinaNet
Focal Loss 의 성능을 보여주기 위해 one-stage detector 인 RetinaNet을 제작하였다.
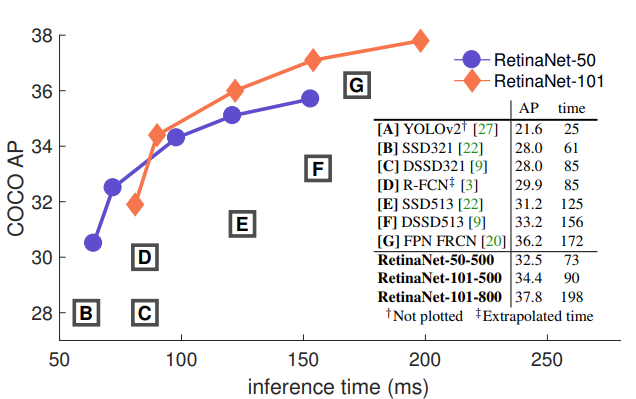
- : FPN-50 기반
- : FPN-101 기반
Focal Loss
- Focal Loss 는 class imbalance 를 해결하기 위해 design 한 loss function이다.
p_t : 해당 class 가 존재할 확률
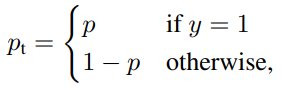
-
Cross Entropy
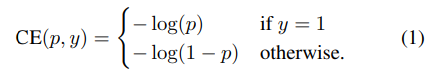
이때 CE 는
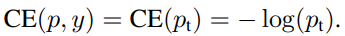
Balanced Cross Entropy
- α-balanced Cross Entropy Loss: class 불균형을 해결하기 위해 weighting factor α 를 적용한 loss function
- 검출할 class 에는 α값을 0~1 사이로 적용하고, background 에는 1-α 를 적용한다.
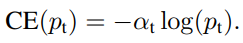
Focal Loss Definition
α-balanced Cross Entropy Loss는 positive/negative example 의 구분은 가능하지만, easy/hard example의 표현은 불가능하다.
- easy example: p_t >= 0.5
- hard example: p_t < 0.5
이에 Focal Loss는 hard negative example의 학습에 초점을 맞추도록 α-balanced Cross Entropy Loss를 수정한 loss function 이다.
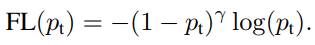
앞에 추가된 인자를 통해 loss 에 미치는 영향을 바꿔준다. (γ는 hyper parameter)
만약 example classification 이 잘못되었으면, p_t 는 낮은 값을 가져 factor가 1에 가까운 값을 갖게 되기 때문에, loss가 가중치에 영향을 받지 않는다
또한 γ값이 커질수록 modulating factor의 영향이 커진다.
Class imbalance and model initialization
기존의 classification model 은 output이 1 혹은 -1 로 고정되었다.
이 논문에서는 train 초반에 object에 대해 모델이 추정한 확률 p를 추가하여 CE 와 Focal Loss 의 학습 안정성을 향상 시켰다
Class imbalance and Two-stage detector
위에서 설명했던 one-stage detector 의 class imbalance 문제점과 Focal loss 를 사용하게된 이유를 설명하고 있다.
RetinaNet Detector
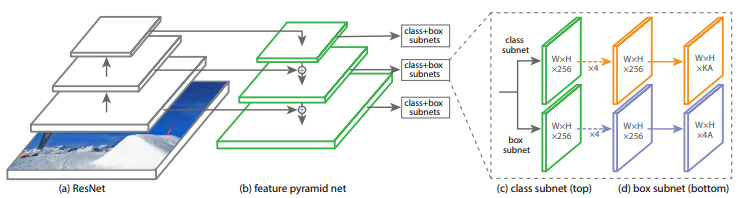
Feature Pyramid Network
RetinaNet 은 backbone model로 FPN(Feature Pyramid Network) 과 ResNet을 사용하였다.
FPN의 구조를 ResNet 위에 쌓아올린 구조를 가지고 있다.
FPN은 입력 이미지에 대해 multi scale feature pyramid 를 생성하여 각 scale에서 object detection을 실행하였다.
P3~P7의 pyramid 를 사용하고, 각 pyramid level은 256 개의 channel 을 가진다.(이때 Pn은 입력 이미지의 1/(2^n)만큼의 resolution을 가지고, n은 pyramid level 을 나타낸다)
속도를 높이기 위해 각 pyramid level에서 1000개의 top scoring prediction 을 가진 box를 사용하고, 모든 level에서 box가 병합되고 NMS를 수행하여 sub-network로 전달한다.
Anchors
이 논문에서는 각 pyramid level에 3개의 aspect ratio = [1:2,1:1,2:1]와 anchor size = [2^0 , 2^(1/3) , 2^(2/3)]를 사용하여 9개의 anchor를 할당한다.
이때 각 anchor는 IOU(앵커박스와 정답 박스의 값)임계값을 사용하여 0~0.4 사이면 background 라고 정의하였다.
0.4~0.5 사이의 IOU는 train 시 무시한다.
Classification Subnet
각 anchor box 내에 object가 있을 확률을 예측하는 network.
각 pyramid level에 작은 FCN을 붙인다(3*3 conv layers, ReLU)
Box Regression Subnet
anchor와 ground truth의 offset을 계산하는 network.
class agnostic bounding box regressor 를 사용하였다.
위의 Classification Subnet과 구조는 같지만 parameter는 공유하지 않는다.