
[Paper] Vision Transformer
Abstract
NLP 분야에서 transformer구조는 대세로 자리잡았지만, CV에 대한 적용은 아직 제한적이다.
CV task에서 attention은 cnn과 함께 적용되거나 cnn의 특정 구성 요소를 대체하는데 사용되었다.
이 논문에서는 이와같은 cnn에 대한 의존성이 필요하지 않으며 image patch sequence에 직접 적용되는 transformer가 잘 수행됨을 보인다.
많은 양의 데이터에 대해 pre-trained 되었을 때 transformer는 train에 필요한 계산 리소스를 적게 사용하면서 cnn에 비해 좋은 결과를 보여주었다.
Introduction
NLP 분야에서 Transfer 구조를 사용하여 많은 양의 데이터에 pre-trained 시킨 뒤 적은양의 특정 데이터로 fine-tunung 시키는 방법은 가장 많이 사용하는 접근방법이 되었다.
transformer의 효율성과 확장성 덕분에, 100B 이상의 parameter를 가진 model을 학습시키는것이 가능해졌고, 계속해서 많아지는 데이터셋에 대해 아직 성능 저하를 보이지 않는다.
이러한 NLP task에서의 성공 때문에 CV task에서도 많은 시도가 있었다.
하지만 large-scale image recognition에서는 여전히 class ResNet 형식의 구조가 여전히 SOTA모델이었다.
이 논문에서는 transformer를 CV task에 적용하기 위해 이미지를 patch로 분리하고 이 patch의 linear embedding sequence를 transformer에 입력으로 전달한다.
이미지 patch들은 nlp에서의 token과 같은 방식으로 처리된다.
mid-size의 데이터에서 학습시켰을 때, 비슷한 크기의 ResNet보다 조금 낮은 정확도를 보여주었다. 하지만 transformer는 inductive bias가 적기 때문에 데이터의 양이 적을때는 일반화가 잘 되지 않지만 큰 사이즈이 데이터셋에서 학습 시 좋은 성능을 보여준다.
Method
모델 디자인은, NLP Transformer의 효율적인 구조를 즉시 사용할 수 있기 때문에 본래의 Transformer를 최대한 따랐다.
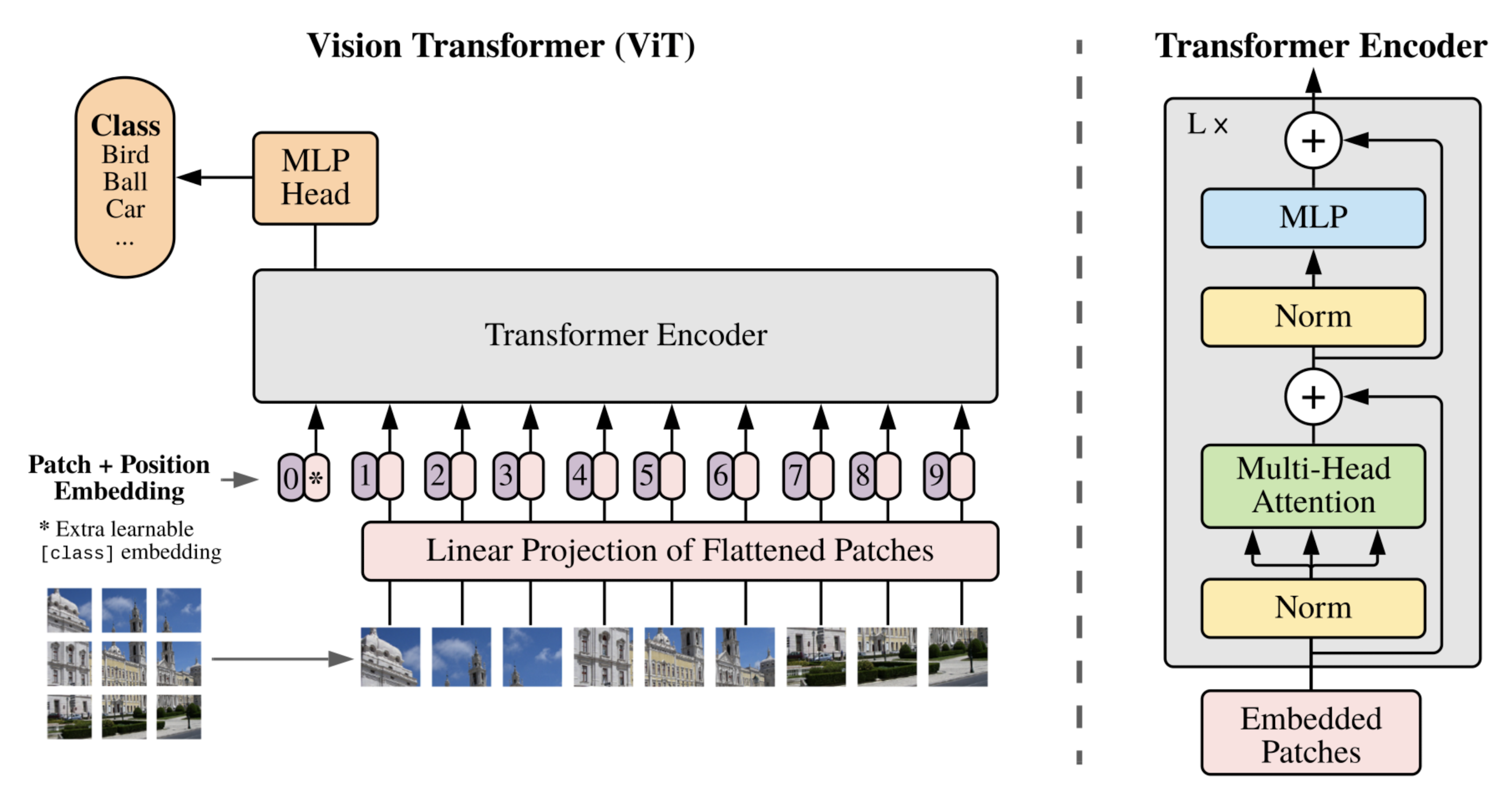
Vision Transformer
2D image 를 처리하기 위해서, 이미지의 차원을 1 차원 sequence로 flatten 해야 한다.
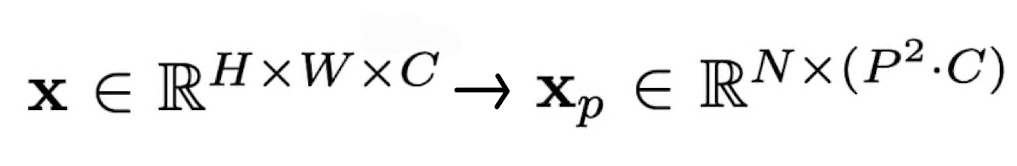
- (H,W) : original image resoluton
- C : channel 갯수
- (P,P) : resolution of each patch
- N : resulting number of patches
이 flatten한 결과를 학습 가능한 linear projection을 통해 D dimension으로 매핑한다. = patch embedding
BERT 의 class token과 비슷하게, embedding된 patch들의 맨 앞에 학습 가능한 class token embedding vector를 더한다.
이 xclass(embedding vector,z00)는 여러 encoder층을 거쳐 최종 output(z0L)으로 나왔을 때, 이미지에 대한 1차원 representation vector의 역할을 한다.(L : 마지막 dimension)
pre-training 과 fine-tuning 시에, image representation vector위에 classification head가 붙는다.
- classification head
- pre-train : 하나의 hidden layer를 가진 MLP
- fine-tuning : 단일 linear layer
이러한 과정을 거친 최종 embedding vector 가 encoder에 input으로 들어간다.
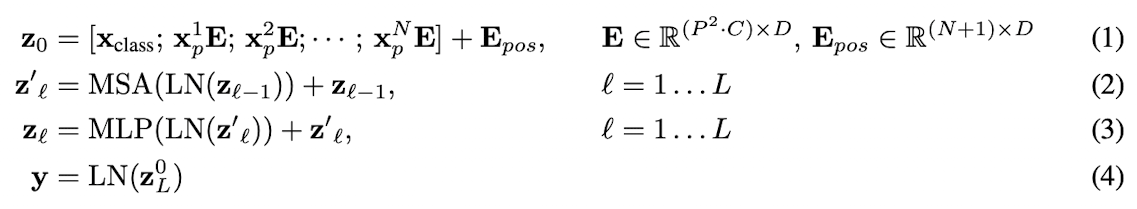
- xclass : classification token
- xNpE : patch로 나눈 각각의 image sequence
-
eq1 마지막 Epos : positional encoding
- transformer encoder
- MSA,MLP 블록으로 이루어져 있다.
- Layer Norm이 모든 블럭 전에 적용되어있고, residual connection이 모든 블럭 뒤에 적용되어있다.
- MLP는 GELU activation function을 포함한 2개의 layer로 구성되어 있다.
Inductive bias
CNN의 경우에는 convolution 시에 kernel 내에 있는 이미지를 보기 때문에, 지역적인 inductive bias가 존재하지만 ViT의 경우에는 patch들로 잘라서 보았을 때 다른 모든 patch들에서 정보를 가져와 학습하기 때문에 inductive bias가 적다.
이러한 특성 때문에 CNN과 비교해 데이터의 양이 많아질수록 성능이 계속해서 좋아진다.
Hybrid Architecture
raw image patch의 대안으로 CNN의 feature map에서 input sequence를 가져올 수 있다.
하이브리드 모델에서, patch embedding projection(eq1)은 CNN feature map에서 추출된 patch에 적용된다.
Fine-tuning and Higher Resolution
일반적으로 큰 dataset에서 ViT를 pre-train 하고, 원하는 task에 대해 fine-tuning을 진행한다.
이를 위해 pre-traine된 prediction head를 제거하고, 0으로 초기화된 D*K feedforward network를 붙인다.
(K : class 수)
더 높은 해상도에서 fine-tuning하는 것이 가끔 더 좋을 때가 있다.
ViT는 sequence length에 상관없이 처리할 수 있지만, pre-trained 된 position embedding은 의미가 없을 수 있다.
이를 위해 원래 이미지의 위치에 따라 pre-trained된 position embedding의 2D 보간을 수행한다.
resolution adjustment 와 patch extraction 부분이 2D 구조에 대한 inductive bias가 주입되는 유일한 부분이다.