
[Report] Object detection memoir
Object detection 개인 회고록
Object detection competition 소개
competition 기간 : 2022.03.21 1 2022.04.07
competition 내용 : 주어진 dataset 에서 쓰레기를 찾아내어 해당 쓰레기의 종류를 찾아내는 task
팀원: CV-12조 (노창현,김승현,최홍록,최진아,최용원)
test 환경
1
2
3
4
5
6
dataset : AI stages trash dataset(coco type)
server : AI stages server
gpu : Tesla V100-PCIE-32GB
program : VScode
library : mmdetection
test result : wandb
competition 진행 내용 정리
data EDA
저번 대회에서도 느꼈지만 data에 대한 제대로된 이해가 필요하다고 생각했다
전체적인 class 비율 파악, ground truth bbox 를 출력하여 bbox가 사진 하나에 얼마나 형성되어있는지 를 확인하였다
- class 별 분포
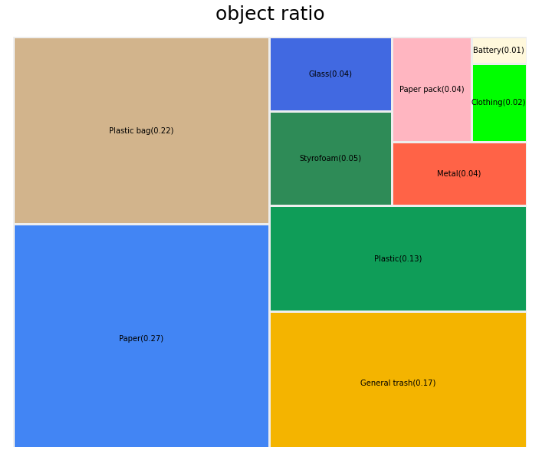
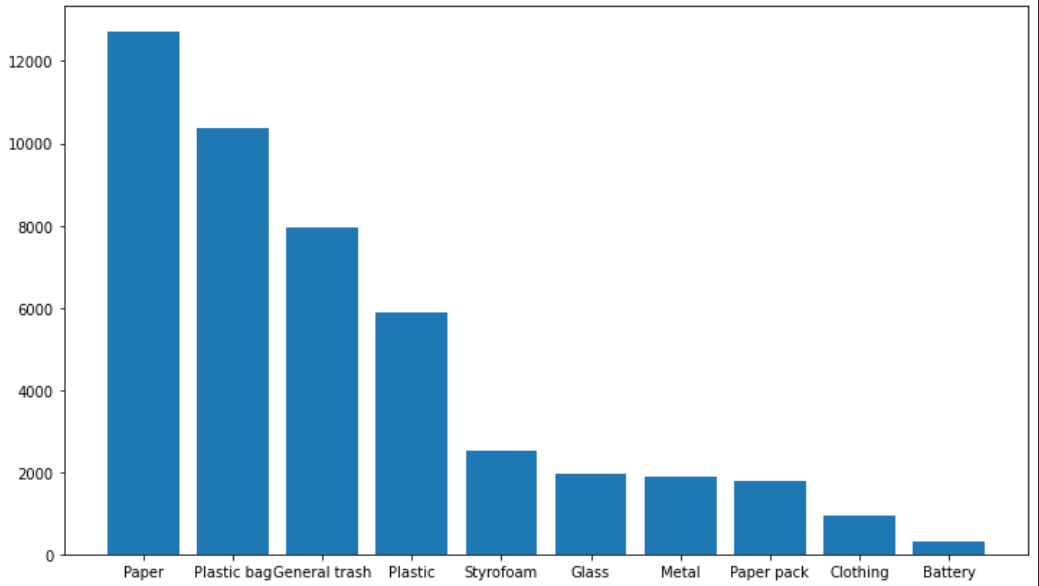
- ground truth 예시

더 확인했으면 좋았을 내용
-
bbox 크기에 따른 분류
크기가 작은 물체를 찾아내는 것이 어려웠기 때문에, bbox 의 크기별로 분류하여 data augment 시에 어떠한 것에 더 초점을 두어야 할지 알아낼 수 있었을 것이라고 생각했다
-
K-fold 의 정확한 사용법
fold 를 5개로 나누어 사용하였는데, K-fold 부분을 다시 공부해 보니 원래의 목적은 여러개의 fold 를 만들어 model을 학습시킨 뒤에 최적의 hyper parameter 를 찾아내고, 큰 dataset 에서 학습을 하는 것이 목적이라고 한다. 하지만 나는 단순히 여러 fold 에서 model 을 학습시킨 뒤 ensemble 만 하여 제대로 된 K-fold 를 사용하지 못했다고 생각했다
model test
mmdetection 적응
처음 test 한 model 은 cascade rcnn 에 resnet 50 을 적용한 모델이었다. 이떄는 cascade rcnn, resnet 50 에 초점을 두지 않고 먼저 mmdetection library 에 적응하고자 강의를 보고 따라해 보았다.
mmdetection 초기 실험을 끝내고, 결과를 공유하고자 wandb 를 통해 서로의 실험 결과를 공유하였고, 이후로 다양한 model 에 대한 실험이 수월하게 이루어졌다
backbone
-
swin transformer
transformer 기반의 backbone 모델로 많은 데이터와 시간이 필요하지만 좋은 성능을 보여주었다. 다만 실험을 하며 느낀점은 transformer 기반의 model은 data 가 많을수록 더욱 좋은 성능을 보여주는데, competition 의 data 는 많지 않아 과연 우리가 가지고 있는 data 에 맞는 model 일까 생각하였다
-
convnext
mmdetection 에 대해 찾아보다가, convnext 라는 최근에 나온 backbone model 을 알게 되었다. 이 모델은 resnet 구조에서 layer 의 층을 변형한 model로, transformer 기반의 model 보다 좋은 성능을 내어 SOTA 모델이 되었다고 하여 사용해 보았다.
Object Detection architecture
-
tood
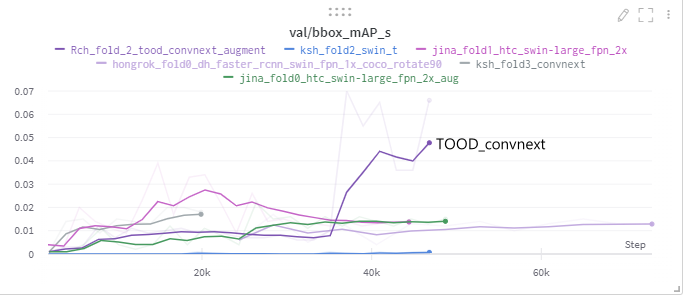
mmdetection의 가장 최근 적용된 논문으로 one-stage detection 모델이다.
resnet 을 backbone으로 사용하였고 model test 시에 좋은 성능이 나왔다. 특히 mAP_S 에서 뛰어난 성능을 보여주어, ensemble 시에 성능 향상에 큰 기여를 하였다.
data augmentation
-
GaussianBlur,MedianBlur
blur 를 적용하여 일반화 성능을 높이고자 적용
-
RandomGamma
사진 전체의 밝기를 조정하여 여러 상황에서의 data 를 인식하도록 train 하기 위해 적용
-
RandomBrightnessContrast
contrast 와 brightness 를 random 하게 주어 물체 인식 성능 향상 및 여러 다른 data에 대해 일반적으로 더 잘 추출하도록 적용하였다
-
HueSaturationValue
HSV 모델의 parameter 를 변환하여 물체 간의 대비, 색 차이를 조금 더 높여 variation 을 넓혀주고자 적용하였다
-
random rotate
trash 데이터이다 보니 여러 방향으로의 rotate 에 대해 많은 학습이 필요하다고 생각했다
ensemble
cross validation을 포함한 model을 학습시키며 performance가 잘 나온 것들을 추려내었고 그 중에서도 mAP_s, mAP_l, mAP_m 성능이 상대적으로 뛰어난 것들을 추려내어 WBF를 적용하였다. (총 30개의 csv 파일을 사용)
더 확인했으면 좋았을 내용
-
Object detection architecture 에 대한 이해
이번 대회에서 내가 사용했던 model 은 TOOD,htc,cascade rcnn 등이 있다. 하지만 각각의 논문을 읽고 사용하지 않았고, 구조를 자세히 들여다보지도 않았기 때문에 이 회고록에도 기록하지 않았는데(성능 향상에 큰 기여를 한 TOOD 제외), 관련 논문을 읽고 구조를 확실히 알고나서 사용했다면 더 의미있지 않았을까 생각했다
결과
대회 결과
Final Rank : 6/19 th place
- LB score
- public : 0.7152
- private : 0.7017
-
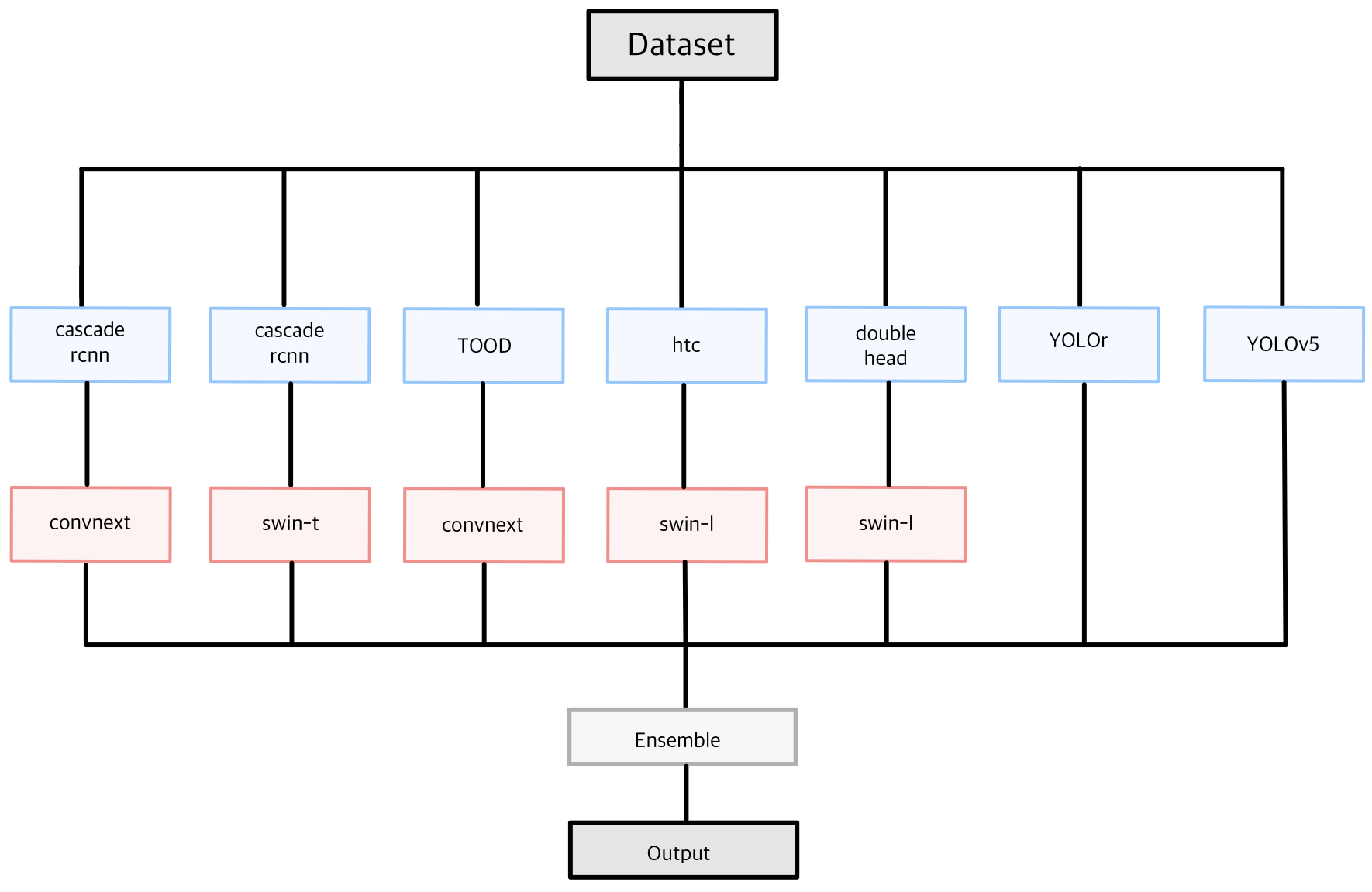
최종 모델
Detector Backbone fold cascade rcnn convnext 0 - 5 cascade rcnn swin transformer 0 , 1 , 3 TOOD convnext 0 - 5 htc swin transformer 0 - 5 double head swin transformer 0 YOLOr - 0 - 5 YOLOv5 - 4 -
모델 개요
mAP_score
mAP_50 score
tood_anchor based
| fold | Backbone | epoch | lr | mAP_50 |
|---|---|---|---|---|
| 3 | resnet50 | 24 | 0.0001 | 0.454 |
-
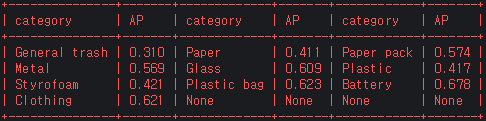
class 별 AP
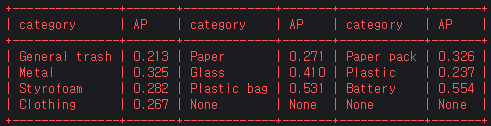
tood_x101
| fold | Backbone | epoch | lr | mAP_50 |
|---|---|---|---|---|
| 3 | resnext101 | 24 | 0.0001 | 0.469 |
-
class 별 AP
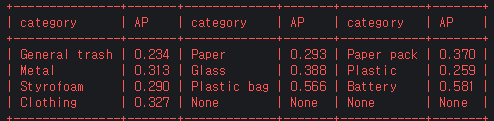
tood_convnext(data augmentation add)
| fold | Backbone | epoch | lr | mAP_50 |
|---|---|---|---|---|
| 0 | convnext | 24 | 0.0001 | 0.635 |
| 1 | convnext | 24 | 0.0001 | 0.64 |
| 2 | convnext | 24 | 0.0001 | 0.589 |
| 3 | convnext | 24 | 0.0001 | 0.64 |
| 4 | convnext | 24 | 0.0001 | 0.617 |
-
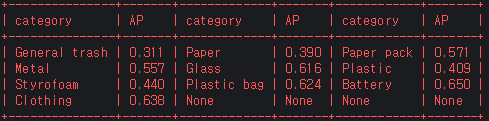
class 별 AP
-
fold_0
-
fold_1
-
fold_2
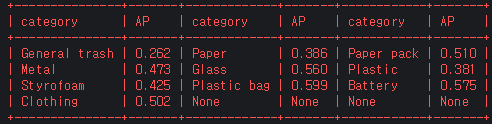
-
fold_3
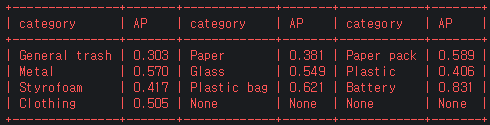
-
fold_4
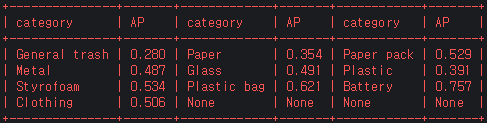
-
htc_swin_l
| fold | Backbone | epoch | lr | mAP_50 |
|---|---|---|---|---|
| 3 | resnet50 | 30 | 0.002 | 0.321 |
| 3 | Swin_L | 30 | 0.0001 | 0.32 |
htc_swin_l(data augmentation add)
| fold | Backbone | epoch | lr | mAP_50 |
|---|---|---|---|---|
| 3 | resnet50 | 24 | 0.0001 | 0.52 |
| 3 | Swin_L | 24 | 0.0001 | 0.647 |
cascade_rcnn
| fold | Backbone | epoch | lr | mAP_50 |
|---|---|---|---|---|
| 3 | convnext | 30 | 0.0001 | 0.132 |
| 3 | Swin_L | 30 | 0.0001 | 0.568 |