
[Theory] CNN Theory
📑 CNN(Convolution Neural Network)
Convolution
내가 배웠던 DSP(Digital Signal Processing) 에서의 Convolution 은 어떠한 입력과 함수가 있을 때 그 시스템의 응답을 보기 위해 사용했었다.
CNN 에서의 Convolution 은 Neural Network 는 데이터를 flattering 하여 각 픽셀에 가중치를 곱하여 전달 하기 때문에 공간적 특성이 보존이 되지 않는 문제점을 개선하고자 사용한다
쉽게말해 이미지 데이터의 공간적 특성을 유지하기 위해 NN 대신 CNN을 사용한다
Convolution 연산

연속신호의 Convolution과 이산신호의 Convolution은 시스템의 응답을 보기 위해 함수를 뒤집어 시간축을 맞춰준다
하지만 Image Convolution에서는 이미지에 픽셀을 Convolution하여 각 filter를 이미지 픽셀 위에 겹친 뒤 합을 한 픽셀로 반환하게 된다
이 과정에서 padding 이 없다면 image 크기가 작아지게 된다
Image Convolution 적용 방법

이러한 연산은 kernel 만큼의 가중치만을 사용하게 되는데 이는 Local Connectivity 라고 부르고,
모든 가중치를 사용하는 Fully Connected Layer 보다 빠른 연산속도를 가지게 된다

CNN
CNN은 Convolution layer, pooling layer, fully connected layer 등 여러 layer 로 구성 된다
이러한 CNN 의 발전은 점차 Parameter 을 줄이고, Depth를 늘리는데 집중했다
줄어든 Parameter는속도의 향상을 가져오고, 늘어난 Depth 또한 같은 연산이지만 적은 Parametr 를 사용하도록 함으로써 성능의 향상을 불러왔다
CNN 관련 용어
Stride
Kernel 을 몇 픽셀식 움직이면서 찍는가를 나타낸다
Padding
버려질 수 있는 boundary 정보를 챙기기 위해 혹은 convolution 후의 image size를 맞춰주기 위해 데이터로 image를 감싸는 것을 말한다


다음은 3x3 kernel,5x5 data의 stride = 2, padding = 1인 Convolution의 연산이다

Convolution Arithmetic

위와 같은 40x50x128 의 데이터에 3x3 kernel stride = 1,padding = 1 을 적용시켰을 때 40x50x64 의 output이 나왔다면, 이 model의 parameter 수를 구해보자
3x3 kernel 에 padding = 1이기 때문에 output은 40x50의 형태로 나올 수 있었다
Channel 이 128 -> 64로 바뀌었으므로 이 model 의 parameter 는
3x3x128x64 = 73728
이 나오게 된다
(이 때 Convolution을 하기 위해선 kernel 의 채널 수와 input data의 채널 수가 같아야 한다)
1x1 Convolution
1x1 Convolution은 데이터의 Dimension(channel)을 줄여주기 위해 사용한다
이는 model 의 depth 가 깊어질수록 늘어나는 parameter 수를 줄이기 위해 channel 을 줄이는데 사용된다
MLP(Multi-Layer Perceptron)
Linear Neural Networks
여러 데이터를 가장 잘 나타낼 수 있는 직선을 찾는 개념
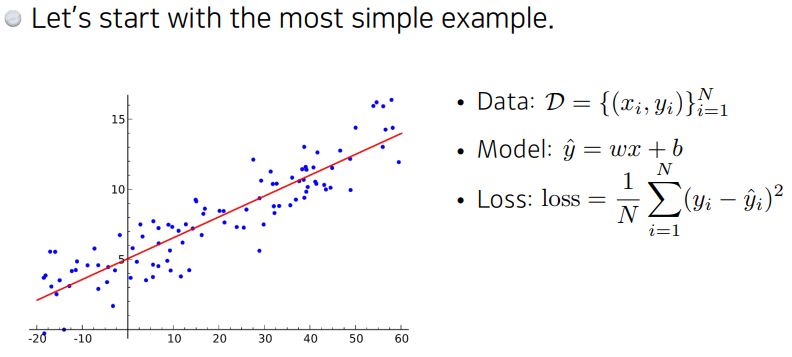
- data : 1차원 x,1차원 y의 N개의 데이터
- model: anality function을 통해 loss가 최소화 되는 w,b를 찾을 수 있다
하지만 이 anailiy function에는 많은 조건이 붙기 떄문에 backpropagation을 사용한다
backpropagation : parameter 움직일때 어디로 움직여야 Loss 줄어들지 미분을 통해 계산
- w loss 계산

- b loss 계산
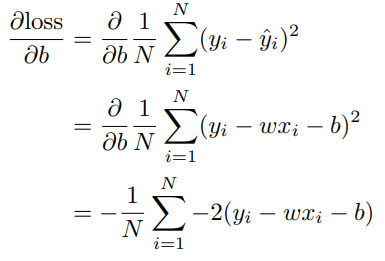
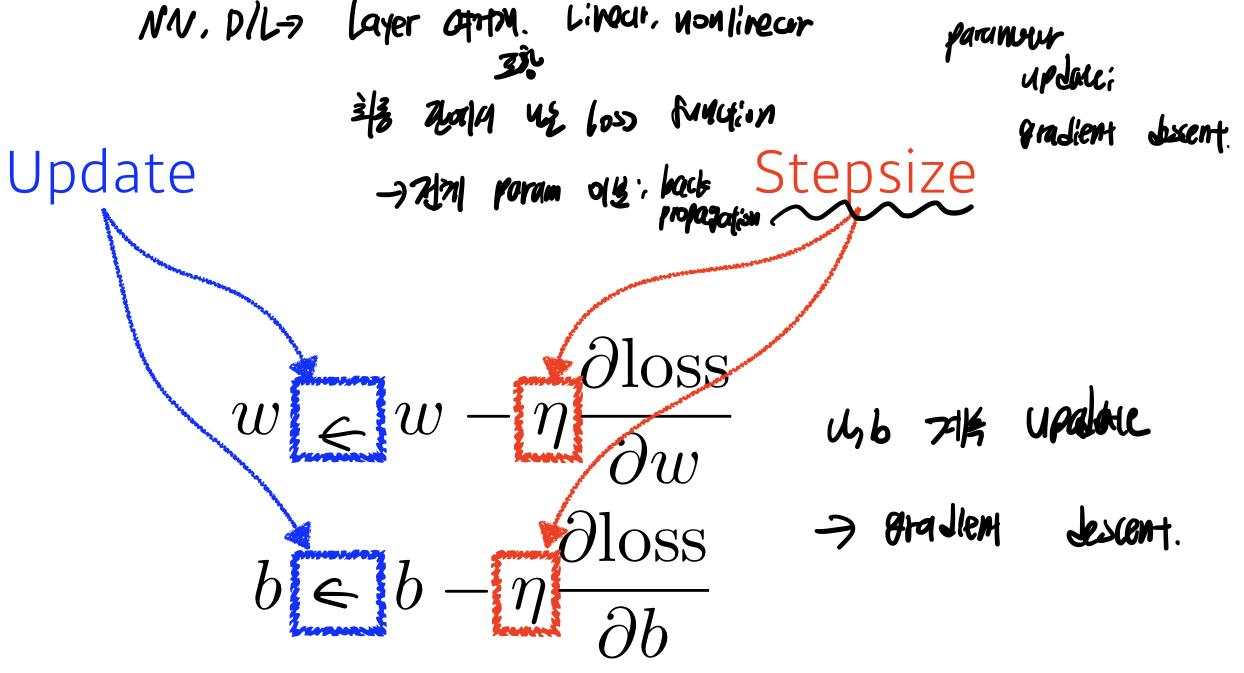
<span style=”color: #ed6663”gradient descent</span>
- 그림처럼 w,b를 계속해서 update
- 줄이고자 하는 Loss function에 대해 편미분을 구한뒤 빼주어 최소값을 구한다
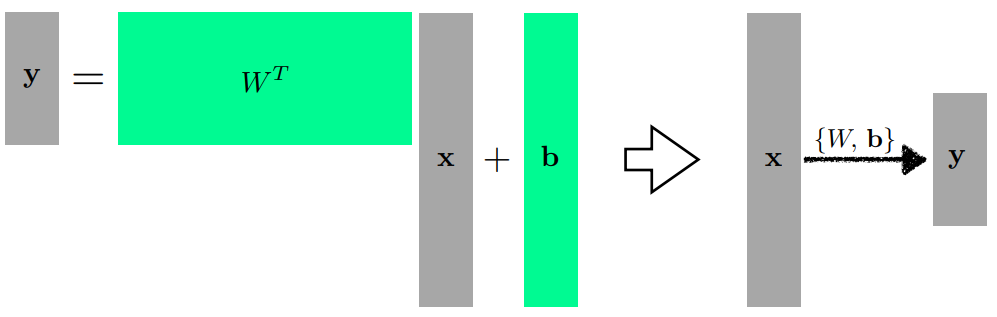
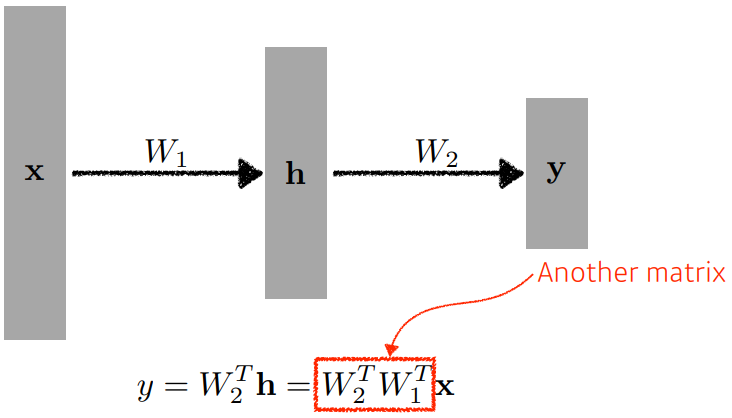
다른 차원의 결과를 얻고 싶을 때 행렬을 사용하여 원하는 형태의 행렬을 구한다
w라는 행렬과 b의 행렬을 통해 x라는 입력을 y라는 형태의 차원으로 보낼 수 있다
이러한 w,b의 행렬만을 이어붙여 여러번 연산하면, 그 연산은 여러 행렬을 곱한 하나의 연산이 되어버린다. 이때 network의 표현력을 높이기 위해 위해 비선형성을 추가해준다(Nonlinear transform)
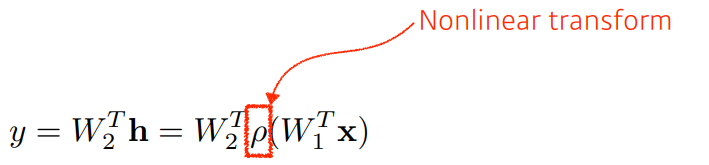
activation functions
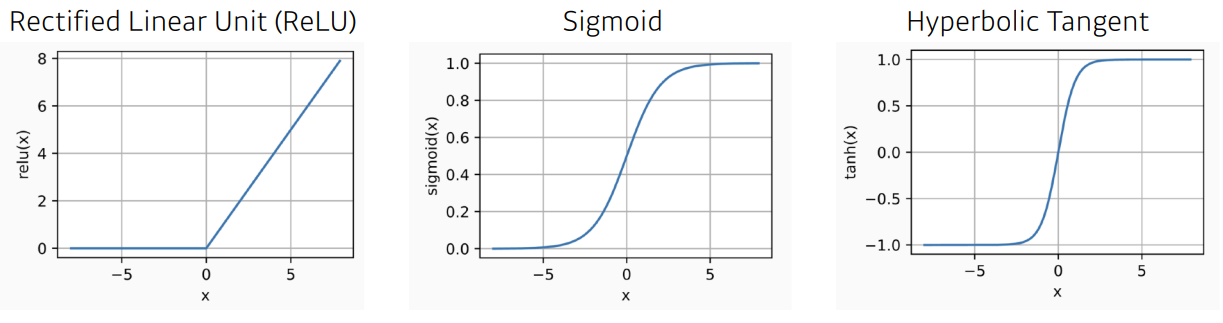
- ReLU : gradient vanishing 을 방지하기 위해 나온 activation function
- sigmoid : 출력값을 0~1 사이로 제한
- Hyperbolic Tangent : cnffurrkqtdmf -1 ~ +1로 제한
Multi Layer Perceptron
이러한 Neural Network가 여러개 합쳐진 것이 MLP 이다.
Loss function
loss function의 목적은 입력이 주어졌을 때 target data와 prediction 데이터와의 차이를 줄이는것이 목표
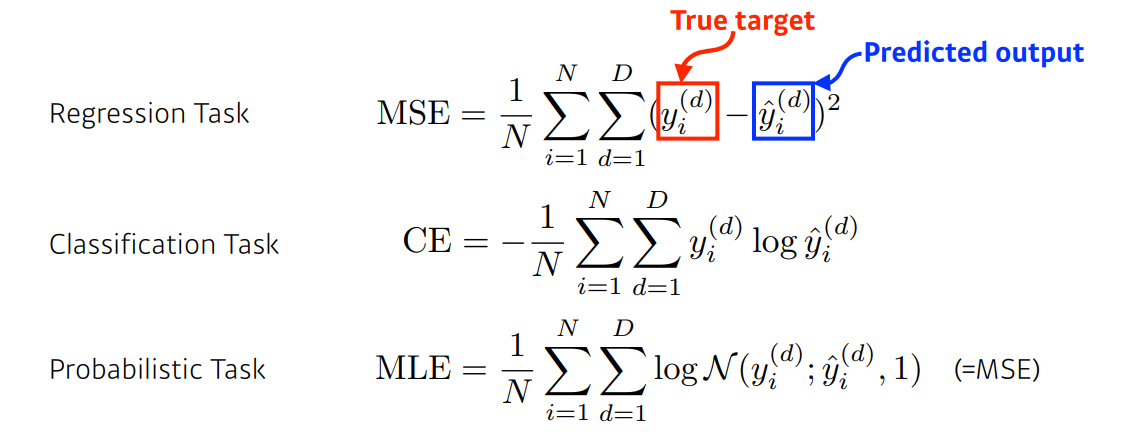
MSE Loss
- regression task 에 사용
- 항상 목적에 맞지는 않는다. 오차의 제곱으로 구하기 때문에 오류가 큰 결과가 있으면 전체 network 가 망가질 수 있다.
CE Loss
- Classification task 에 사용
- 분류 문제를 잘 푸는 이유: 분류 문제의 out vector는 보통 원-핫 벡터로 표현된다. 여기서 y hat을 logit이라고 하는데, model 의 출력값에서 해당하는 값만 높이는 loss function. 값의 크기에 상관 없이 다른 값에 대해 높기만 하면 된다.
MLE Loss
- Probabilistic task 에 사용
- output을 보고 확률적인 해석을 하고 싶을 때 사용
Modern CNN
AlexNet
AlexNet 구조

위의 입력 데이터는 224x224x3으로 나왔지만 실제 입력 데이터는 227x227x3이다
이 입력 데이터에 대해 11x11,5x5,3x3 3종류의 커널을 사용하였다
Layer 구성
5가지의 Convolution Layer
3가지의 Dense Layer
Key Ideas
ReLU activation
- Linear model 의 장점을 가진다
- gradient가 커도 그 값을 그대로 가지고 있는다
- gradient vanishing 현상을 해결했다
GPU implementation(2 GPUs)
- layer 구성을 보면 2개의 gpu를 사용하기 위해 데이터를 나누어 학습을 진행하였다
- GPU-1 : 컬러와 상관 없는 정보를 추출하기 위한 kernel
GPU-2 : 컬러와 관련된 정보 추출하기 위한 kernel
local response normalization & overlapping pooling
local response normalization :
같은 위치의 픽셀에 대해 다수의 feature map 간의 normalize 진행하였다
overlapping pooling :
중복된 영역에서 pooling 진행하였다 (일반적으로는 중복되지 않는 영역에서 pooling)
Data augmentation
256x256 크기의 이미지에서 227x227 크기의 이미지를 randomly crop
RGB channel 값 변화
Dropout
: over-fitting을 막기위해 랜덤하게 일부 뉴런을 생략하여 학습
VGGNet
VGGNET 구조

이 model 은 네트워크의 depth 가 어떤 영향을 주는지 연구하기 위함 이었다
때문에 convolution filter를 하나의 크기로 고정하여 layer를 늘려나가며 테스트를 진행하였다
Key Ideas
Increasing depth with only 3x3 Convolution filters(stride 1)
kernel 사이즈가 커지면 receptive field가 커진다. 때문에 커지면 커질수록 많은 양의 정보를 담아둘 수 있지만 parameter 수가 점점 많아지게 된다
이러한 receptive field 는 유지하되 parameter를 줄이기 위해 3x3 kernel 을 두번 사용하여 receptive field 는 동일하고, parameter 개수는 줄이는 방법을 사용했다

Dropout = 0.5
GoogLeNet
GoogLeNet 구조

Key Ideas
NIN(Network in network) 구조
network 안에 같은 모양의 network 가 반복되는 형식이다
NIN 구조와 inception block 구조를 합쳐 구현하였다
Inception blocks

- 1x1 filter: 입력 데이터의 공간적 정보를 잘 담도록 하였다 -> 각 필터마다 적용되었디
- 3x3,5x5 filter: 추상적이고 퍼져있는 정보를 잘 담게 하였다
Inception 블록을 사용한 이유
parameter 숫자를 줄이기 위해

parameter 를 계산해보면 눈에 띄게 줄어든 것을 알 수 있다
Auxiliary Classifiers
층이 깊어질수록 gradient vanishing 문제가 발생할 수 있는데, 이를 해결하기 위해 Auxiliary Classsifiers를 통해 중간 단계에서 gradient를 주입하여 하위 레이어에도 잘 전달될 수 있도록 한다.
주의할것은 학습시에만 사용되고 inference time 에서는 제거한다
ResNet
ResNet 구조

Key Ideas
Depth 가 깊은 neural network는 train 하기 힘들다
이유는 많은 parameter 때문에 overfitting 이 자주 일어나기 때문이다

그림을 보면 depth 가 클수록 training error, test error 가 증가한 모습을 볼 수 있다.
하지만 위의 ResNet 구조 를 보면 skip connection 을 통해 입력에 대한 결과에서 차이만 구하여 학습을 시켰다.
때문에 의미가 없거나 좋지 않은 결과를 주는 계층은 영향을 거의 주지 않도록 하여 depth 가 깊어져도 overfitting 이 많이 일어나지 않도록 하였다

Bottle neck

학습 시간을 줄이기 위해 1x1 convolution 을 사용한 bottle neck 구조가 적용되었다
DenseNet
DensNet 구조


Key Ideas
ResNet Connectivity
ResNet 의 출럭값은 skip connection 을 통해 구해지는데, 이때 덧셈으로 결합되기 때문에 신경망에서 정보 흐름이 지연될 수 있다고 한다
Dense Connectivity
이전 레이어를 항상 모든 다음 레이어에 직접적으로 연결한다 -> 정보 흐름이 향상된다
Dense Block
Concatenation 연산을 수행하기 위해서는 image 크기가 동일해야 한다.
하지만 pooling 연산은 convolution network 에서 필수적이기 때문에 크기가 줄어들 수 밖에 없다

Transition block
Dense block 으로 인해 채널이 커지고 파라미터의 수가 급격하게 증가하기 때문에 transition block Batch normalization -> 1x1 conv -> 2x2 AvgPooling
을 통해 차원의 수를 줄인다.