
[Theory] Important of data
데이터 제작의 중요성
Software 1.0
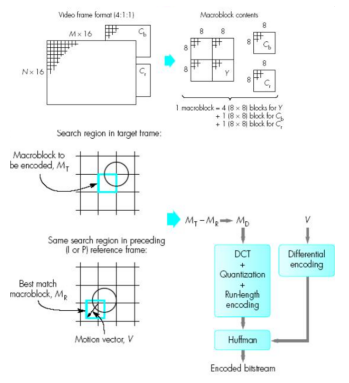
비디오 코덱 문제 정의
문제 정의
비디오를 고화질로 촬영하면 용량이 커지는데 적은 용량으로 품질 저하 없이 저장할 수 는 없을까?
-> 적은 용량의 데이터로 표현해서 저장하고, 재생할 때 원 비디오로 복원하자(비디오 코덱)
큰 문제를 작은 문제들의 집합으로 분해
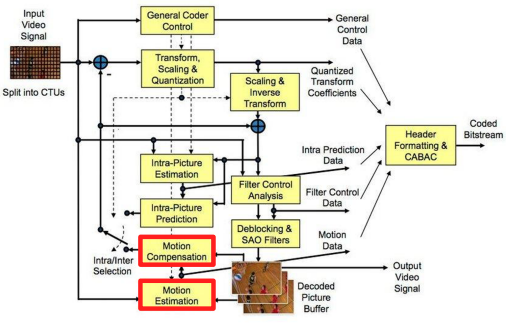
개별 문제 별로 알고리즘 설계
솔루션들을 합쳐 하나의 시스템으로
Human detection 문제 정의
문제 정의
이미지가 입력이 들어올 때 사람이 어디에 있는가?
큰 문제를 작은 문제들의 집합으로 분해
여러가지 case로 나누었다
-
전신이 다 보이는 경우
- 얼굴이 보이는 경우
- 왼 팔이 보이는 경우
- 왼 다리가 보이는 경우
등등
개별 문제 별로 알고리즘 설계
작은 문제들에 대한 여러 module 의 알고리즘을 설계
솔루션들을 합쳐 하나의 시스템으로
설계한 알고리즘을 합쳐 전체 process 완성
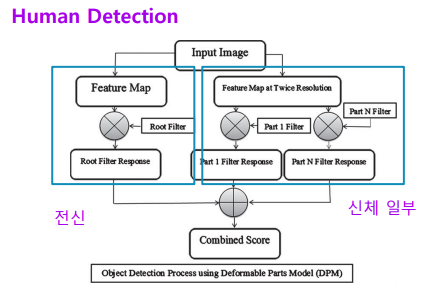
HOG : 사람들이 고민하여 만든 특정 연산들의 집합
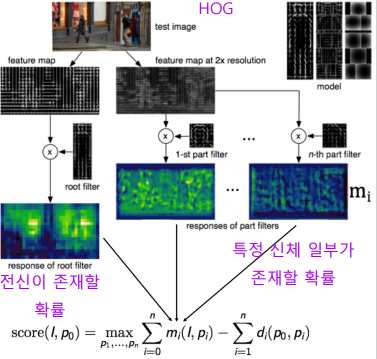
Software 1.0
Object detection
Object detection task 도 Software 1.0 을 적용하여 문제를 해결하고자 하였다
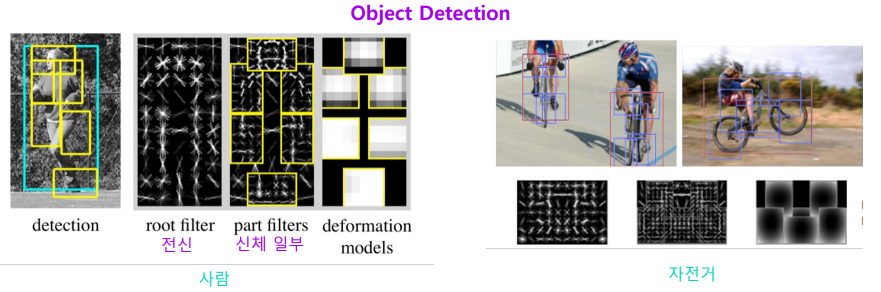
결과
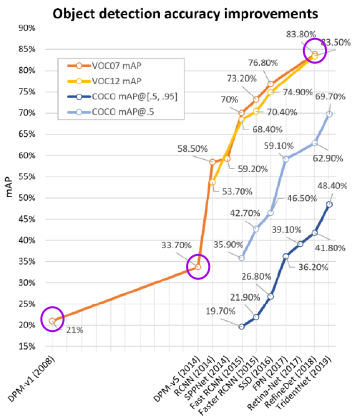
Software 1.0
- 2008 DPM-v1 : 21.0%
- 2014 DPM-v5 : 33.7%
Software 2.0
- 2020 SW2.0 : 89.3%
Software 2.0 에서 엄청난 발전을 보여주었다
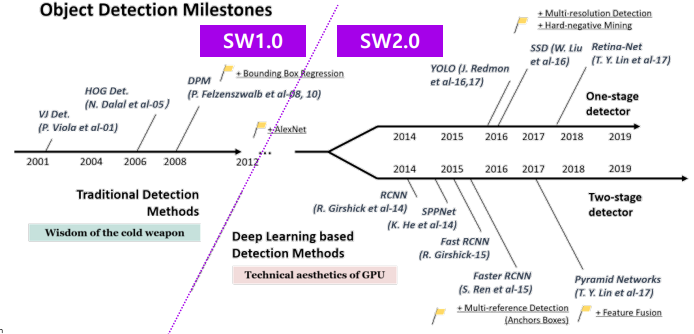
1.0 vs 2.0
Software 1.0
- 이미지에서 특징을 추출하는 연산을 사람이 고안하였다
- HOG
Software 2.0
- 이미지에서 특징을 추출하는 연산을 사람이 개입하지 않았다
- CNN 을 통한 프로그램 검색 범위 한정
- 데이터와 최적화 방법을 통해 최적의 프로그램 탐색
연산 정의 방법
- Neural Network 연산에 의해 검색 영역이 정해진다
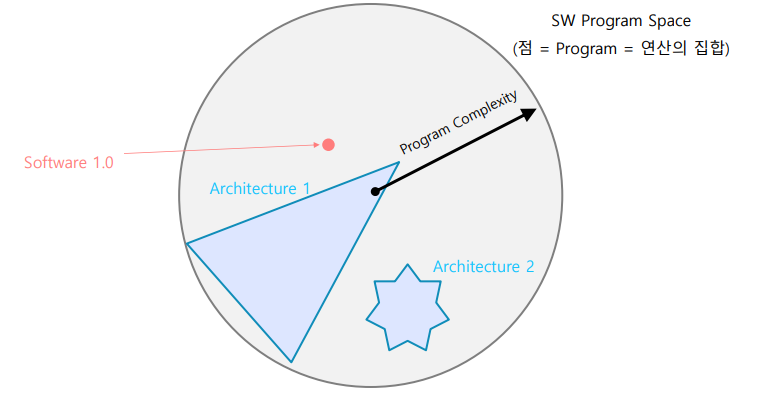
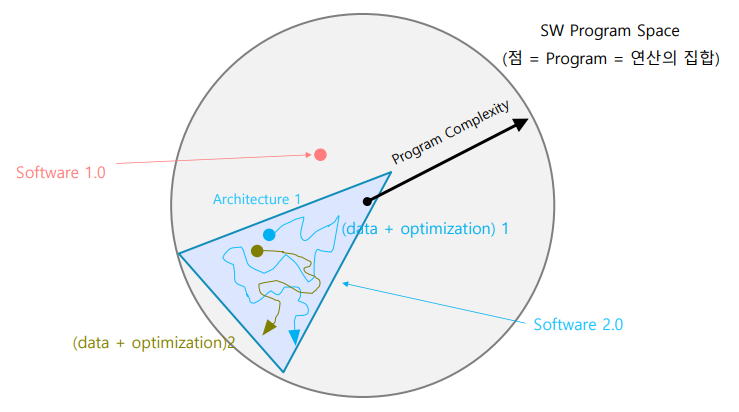
- 최적화를 통해 사람이 정한 목적에 부합하는 연산의 집합을 찾는다
- 이때 경로와 목적지는 데이터와 최적화 방법마다 다르다
Lifecycle of an AI Project
AI research VS AI Production
AI research
- 정해진 데이터셋/평가 방식에서 더 좋은 모델을 찾는다
AI Production
- 데이터셋까지 준비해야한다
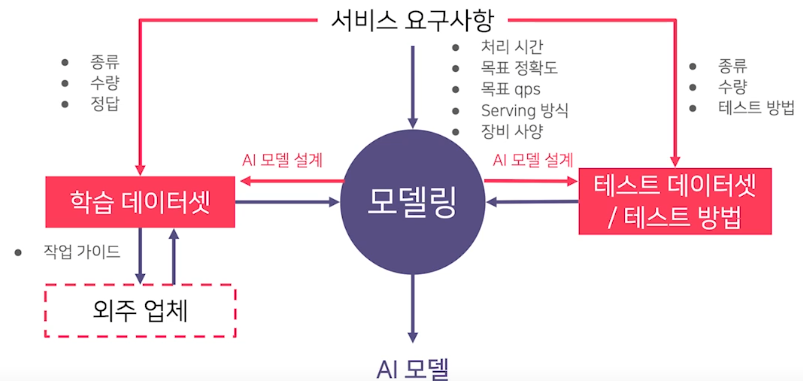
서비스향 AI 모델 개발 과정
- Project setup
- 처리 시간
- 목표 정확도
- 목표 qps(query per second)
- Serving 방식
- 장비 사양
-
Data Preparation
인식 쪽의 model은 대부분 supervised learning 으로 진행된다
- 종류
- 수량
- 정답(Label)
- Model Training
- 데이터 관련 피드백
- 요구사항 달성
- Deploying
- 성능 모니터링
- 이슈 해결
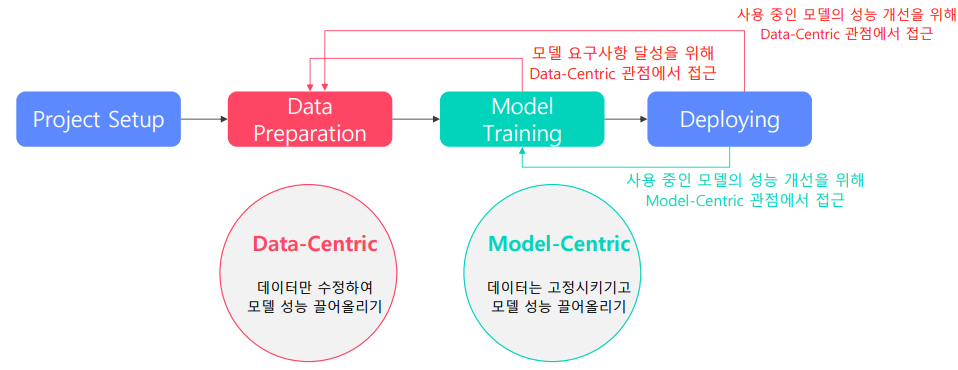
전체 목표
Product serving의 전체 목표는 요구사항을 만족시키는 모델을 지속적으로 확보하는것인데, 이를 위한 2가지의 개선방법이 있다.
Data centric
Data preparation 단계
데이터 중심으로 model 성능을 끌어 올린다
데이터를 수정하는 방향으로 model 의 성능을 향상시킨다
Model centric
Model training 단계
model 의 구조 개선을 통해 성능을 끌어 올린다
Data VS Model
처음 모델 성능 달성 시
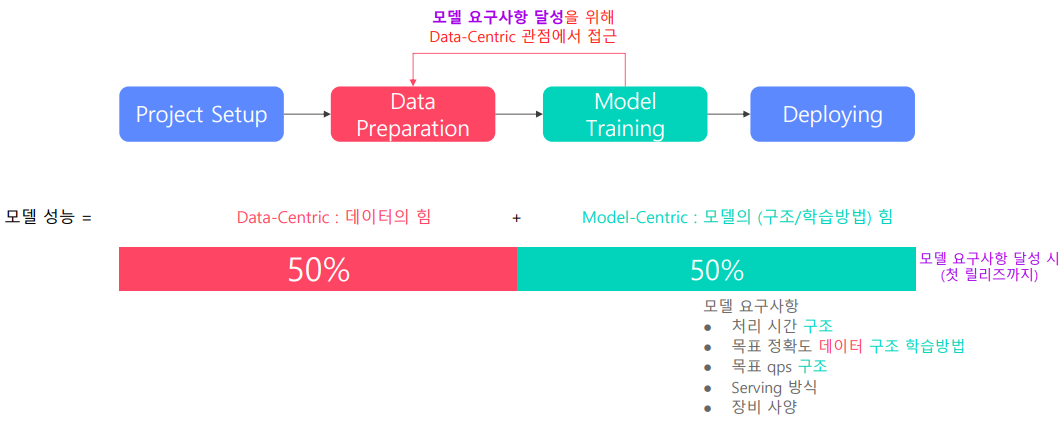
처음 product 완성 시에는 data 도 중요하지만 data 에 맞는 model 구축 및 요구사항을 맞추는 것도 중요하기 때문에 50 : 50
모델 성능 개선 시
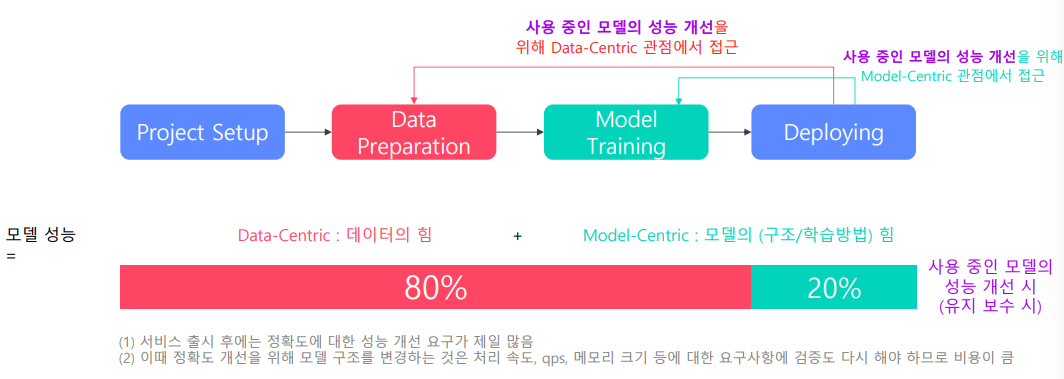
속도에 대한 개선 요구 보다는 정확도에 대한 개선 요구가 훨씬 많다
이때는 Data centric 에 의한 모델 개선이 비용이 적고 검증에 대한 시간이 적게 든다
Data-related task
- 데이터를 어떻게 하면 좋을지에 대해 알려져 있지 않다
- 좋은 데이터를 많이 모으기 힘들다
- 라벨링 비용이 크다
- 작업기간이 오래걸린다
이러한 이유 때문에 학계에서 AI 관련 연구를 할때 model 구조 관련 내용이 대부분이다
- 데이터 라벨링 작업이 많이 어렵다
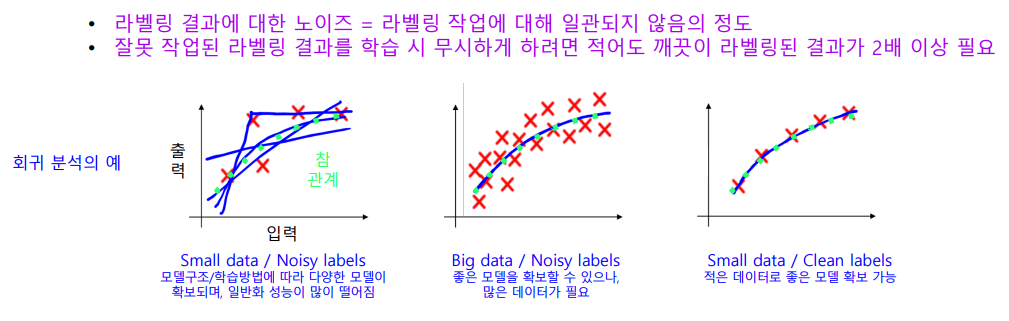
잘못 작업된 라벨링 결과를 학습 하려면 깨끗한 라벨링 결과가 2배 이상 필요하다
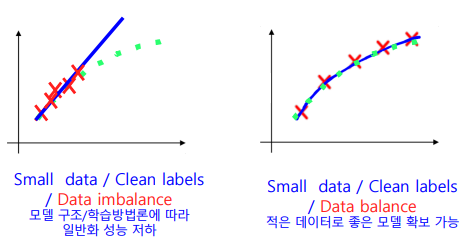
하지만 일반화를 위해 적은 class 의 데이터도 골고루 있어야 한다
라벨링 작업 시
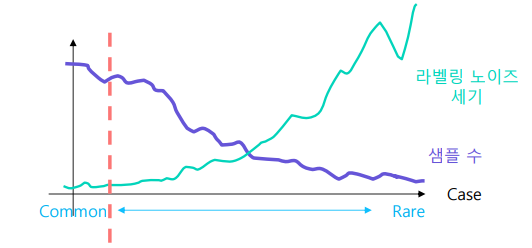
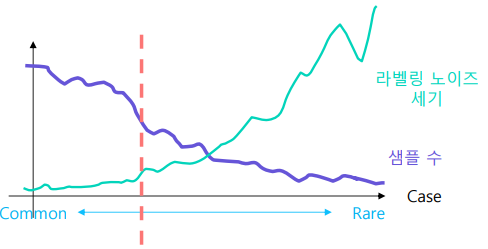
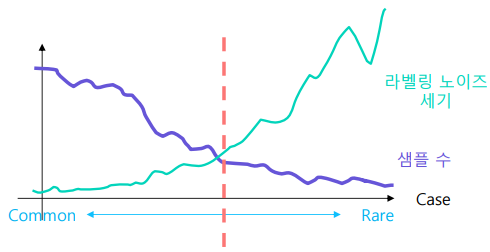
- 데이터가 흔한 경우
- 라벨링을 일관되게 할 수 있다
- 데이터가 흔하지 않은 경우
- 사람마다 다르게 볼수 있어 노이즈가 크다
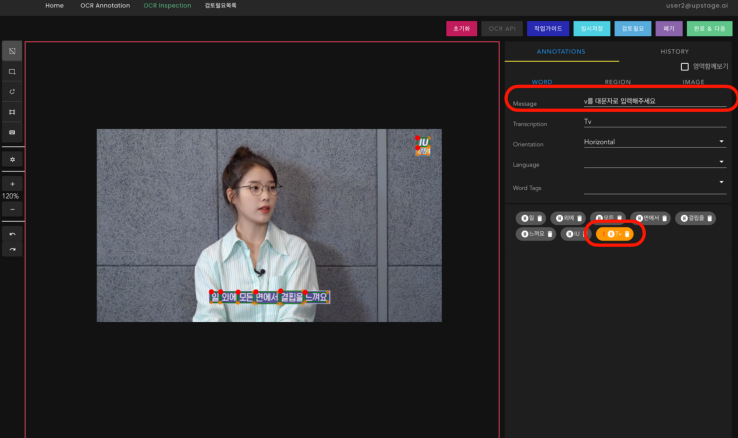
라벨링 작업 예시
라벨링 가이드 : 단어 단위로 사각형으로 표시

- 예외로 label 하는 사람이 거의 없다

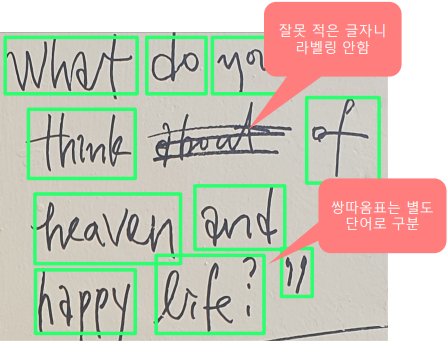
- 점점 사람마다 다르게 측정할 수 있다
- 글자 지움 / 쌍따옴표 가이드 필요하다


- 사진처럼 글자 영역이 겹칠 때의 가이드도 필요하다
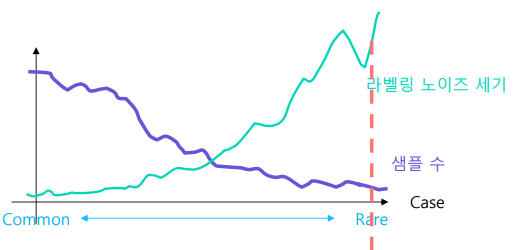

- 너무 예외의 case 인 상황이다
- 띄워쓰기 가이드, 줄바꿈 가이드로도 구분하기 힘들다
- 사람마다 다르기 때문에 많은 Noise
- 데이터 불균형을 바로 잡기가 어렵다

-
특이 경우 관련 sample을 모으고, 관련labeling guide 를 만들어야 한다
- 완벽하게 모든 경우를 알고, 데이터를 모으고, 라벨링 가이드를 만드는 것은 불가능하므로 이를 반복적이고 자동화된 작업으로 만들어 가야 한다
- iterative process
Data engine / Flywheel
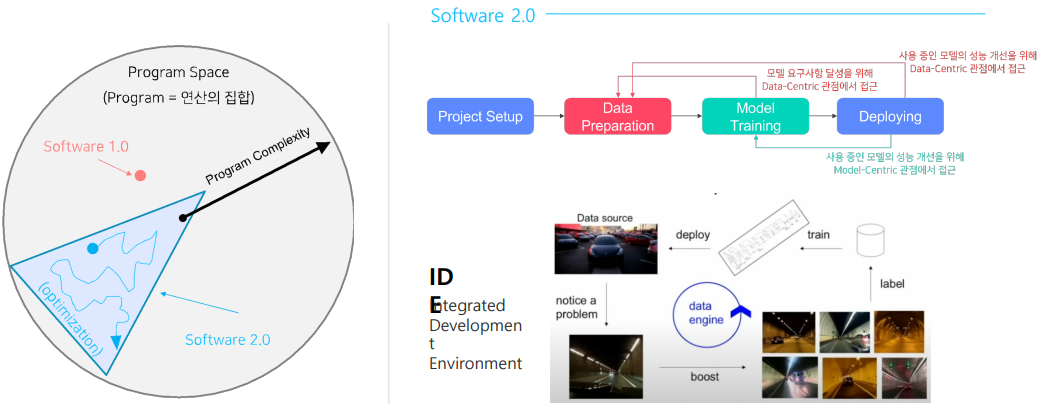
Software 2.0 IDE
필요한 기능들
- 데이터셋 시각화
- 데이터 분포
- 레이블
- 데이터 별 예측값
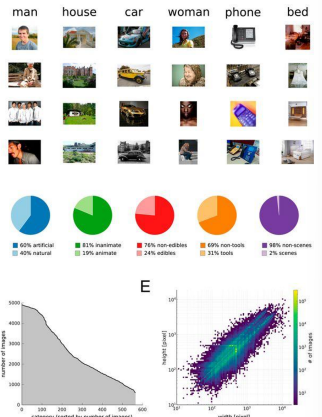
- 데이터 라벨링
- 라벨링 일관성
- 자동 라벨링
- 데이터셋 정제
- 반복 데이터 제거
- 라벨링 오류 수정
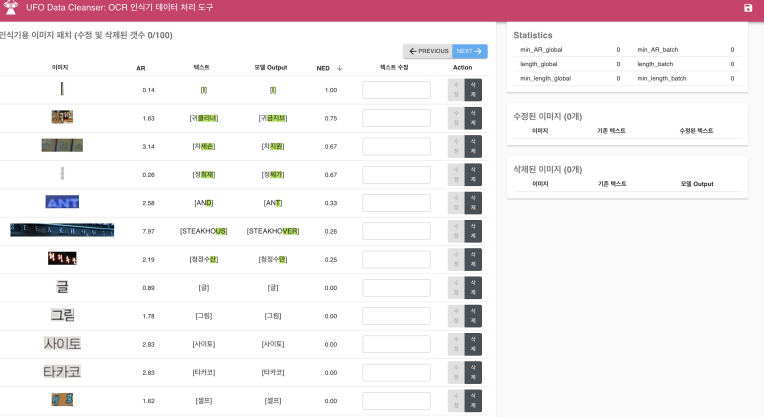
- 데이터셋 선별
- 어떤 데이터를 가져와 라벨링 할지
data 관련 module 은 Software 2.0 을 위해 상당히 중요하다