
[Theory] Autograd
Autograd
torch.nn.Module
- 딥러닝을 구성하는 Layer 의 base class
- Input, Output, Forward, Backward 정의
- 학습의 대상이 되는 parameter(tensor) 정의
Forward, Backward
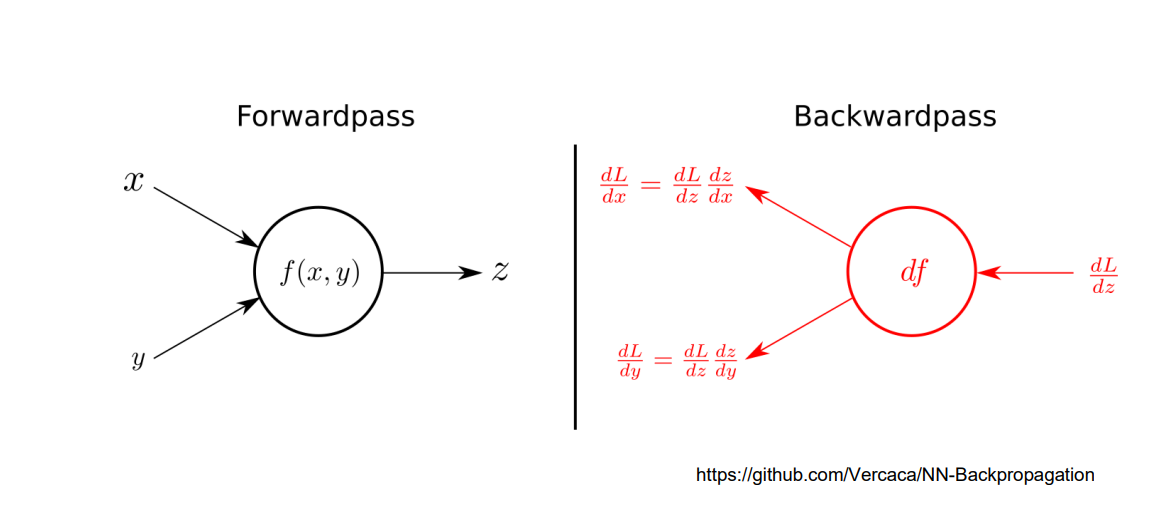
Forward propagation
- 모델의 입력층부터 출력층까지 순서대로 변수들을 계산하고 저장
Backward propagation
- 모델의 parameter 들에 대한 gradient 를 계산하는 방법
## nn.Parameter
- Tensor 객체의 상속 객체
- nn.Module 내에 attribute 가 될 때는
required_grad = True로 지정되어 학습 대상이 된다
1
2
3
4
5
6
7
8
9
10
class MyLiner(nn.Module):
def __init__(self, in_features, out_features, bias=True):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.weights = nn.Parameter(
torch.randn(in_features, out_features))
self.bias = nn.Parameter(torch.randn(out_features))
def forward(self, x : Tensor):
return x @ self.weights + self.bias
Autograd
- Pytorch -> 자동 미분 지원
- 미분대상이 되는 변수는
required_grad = True로 지정
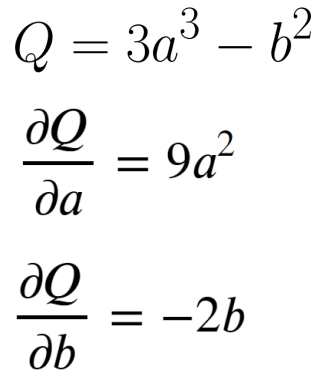
a = torch.tensor([2., 3.], requires_grad=True)
b = torch.tensor([6., 4.], requires_grad=True)
Q = 3*a**3 - b**2
external_grad = torch.tensor([1., 1.])
Q.backward(gradient=external_grad)
a.grad
# a.grad
b.grad
# tensor([-12., -8.])
Backward
- Layer 에 있는 Parameter 들의 미분을 수행
- Forward 의 결과값(model 의 output = 예측치) 과 실제값 간의 차이 (loss) 에 대해 미분을 수행
- 해당 값으로 Parameter 업데이트
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
for epoch in range(epochs):
……
# Clear gradient buffers because we don't want any gradient from previous epoch to carry forward
optimizer.zero_grad()
# get output from the model, given the inputs
outputs = model(inputs)
# get loss for the predicted output
loss = criterion(outputs, labels)
print(loss)
# get gradients w.r.t to parameters
loss.backward()
# update parameters
optimizer.step()
………