
[Theory] Dataloader and dataset
Dataset and DataLoader
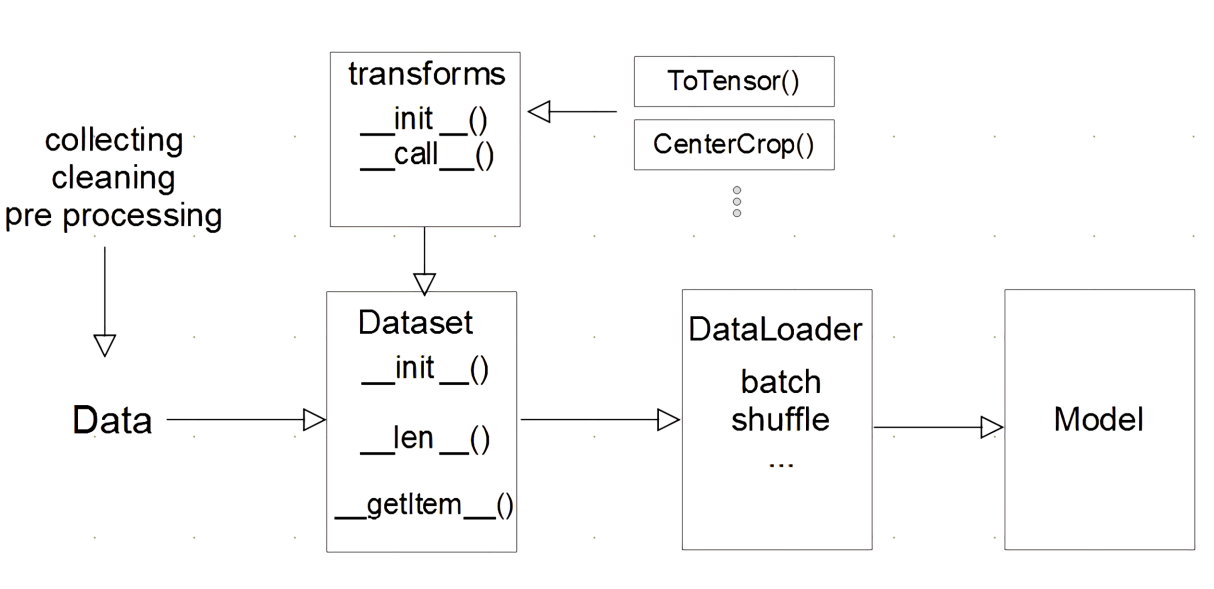
Dataset
- 데이터 입력 형태를 정의하는 class
- 데이터를 입력하는 방식의 표준화
- Image, Text, Audio 등에 따른 입력 다르게 정의
- 데이터 생성 시점에 모든것을 처리 할 필요는 없음(image의 tensor 변화는 학습 필요한 시점에 변환)
- 최근에는 HuggingFace 사용
1 2 3 4 5 6 7 8 9 10 11 12 13
import torch from torch.utils.data import Dataset class CustomDataset(Dataset): def __init__(self, text, labels): # 초기 데이터 생성 방법을 지정 self.labels = labels self.data = text def __len__(self): # 데이터의 전체 길이 return len(self.labels) def __getitem__(self, idx): # index 값을 주었을 때 반환되는 데이터의 형태(X,y) label = self.labels[idx] text = self.data[idx] sample = {"Text": text, "Class": label} return sample
DataLoader
- Data의 Batch를 생성해주는 Class
- 학습 직전 데이터의 변환을 책임(GPU feed 전)
- Tensor로 변환 + Batch 처리가 메인 업무
- 병럴적인 데이터 전처리 코드의 고민 필요
- 여러개의 데이터를 한번에 묶어 model 에 전달
DataLoader Class
1
2
3
4
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False,
drop_last=False, timeout=0, worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)
1
2
3
4
5
6
7
8
9
10
11
text = ['Happy', 'Amazing', 'Sad', 'Unhapy', 'Glum']
labels = ['Positive', 'Positive', 'Negative', 'Negative', 'Negative']
MyDataset = CustomDataset(text, labels)
MyDataLoader = DataLoader(MyDataset, batch_size=2, shuffle=True)
next(iter(MyDataLoader))
# {'Text': ['Glum', 'Sad'], 'Class': ['Negative', 'Negative']}
DataLoader Generator
MyDataLoader = DataLoader(MyDataset, batch_size=2, shuffle=True)
for dataset in MyDataLoader:
print(dataset)
# {'Text': ['Glum', 'Unhapy'], 'Class': ['Negative', 'Negative']} # {'Text': ['Sad', 'Amazing'], 'Class': ['Negative', 'Positive']} # {'Text': ['Happy'], 'Class': ['Positive']}
next(iter(MyDataLoader)) -> iterable 한 객체로 그 다음 데이터를 추출해준다(generator)
collate_fn
- map_style 데이터셋에서 sample list 를 배치 단위로 바꾸기 위해 필요한 기능
- zero-padding 이나 variable size 데이터 등 데이터 사이즈를 맞추기 위해 사용
- ex) ((피처1,라벨1)(피처2,라벨2)) -> ((피처1,피처2)(라벨1,라벨2))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
def collate_fn(batch):
print('Original:\n', batch)
print('-'*100)
data_list, label_list = [], []
for _data, _label in batch:
data_list.append(_data)
label_list.append(_label)
print('Collated:\n', [torch.Tensor(data_list), torch.LongTensor(label_list)])
print('-'*100)
return torch.Tensor(data_list), torch.LongTensor(label_list)