
[Theory] GAN
Generative Adversarial Network
GAN 의 개념
GAN : Generative Adversarial Network
GAN 의 이름 그대로의 해석은 적대적 생성 모델이다.
먼저 생성 모델의 측면에서 다른 모델의 역할인 데이터 class 에 대한 예측값, 가능도를 찾아내는 것이 아닌, 데이터의 형태를 만들기 위한 모델이다.
이미지를 예로 들어보면 우리는 픽셀들의 분포에 따라 어떤 모양인지를 유추할 수 있다.
이 관점에서 분포를 만들어 낸다는 것은, 모양을 만들어 내는것이 되고, 이는 분포를 통해 이미지를 만들기 때문에 실질적인 형태를 갖춘 데이터를 만들어 냈다고 생각할 수 있다.
GAN 은 이러한 분포,분산을 만들어내는 모델이다
적대적 생성 모델의 의미
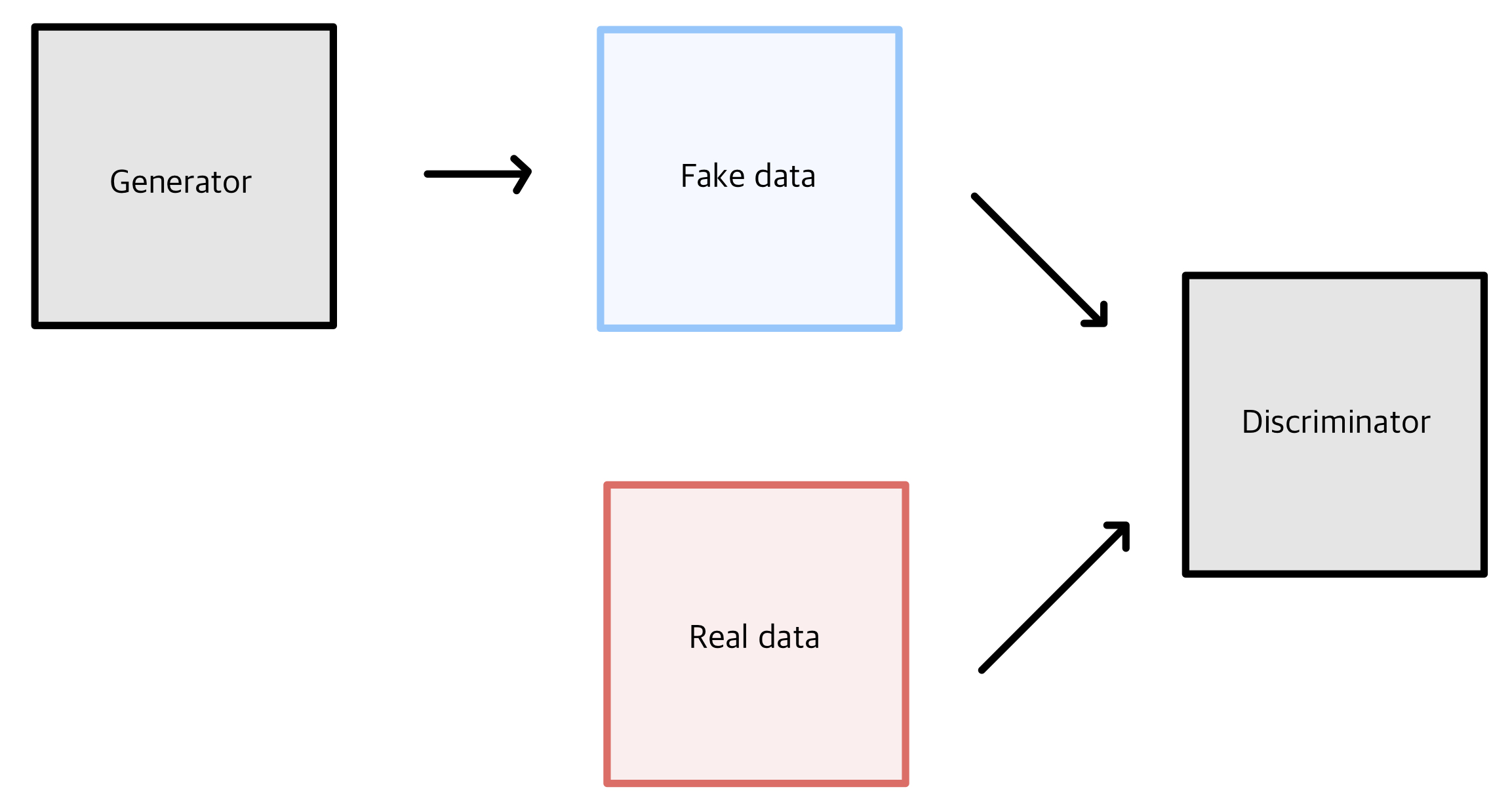
하지만 GAN 은 여기서 적대적 이라는 단어가 들어가있다. 이 단어는 GAN 의 핵심 아이디어를 나타낸다고 할 수 있다
위조지폐를 만드는 범인과 경찰로 주로 비유를 한다.
적대적인 둘의 관계는 위조 지폐범이 위조지폐를 만들면, 경찰은 그 돈이 진짜 돈인지 판별하는데, 이때 위조지폐범은 경찰을 속이기 위해 제조 기술을 발전시키고, 경찰은 위폐를 찾는 기술을 발전시킨다.
이러한 아이디어를 사용하여 이미지를 생성하는 Generator 와 이미지가 fake 인지 real 인지 구분해주는 Discriminator 를 적대적으로 학습시키기 때문에 적대적 생성 모델이라고 불린다
GAN 논문 소개
지금까지 나온 GAN 모델 정리
1. Generative Adversarial Nets
- 최초로 GAN을 제안한 논문이다.
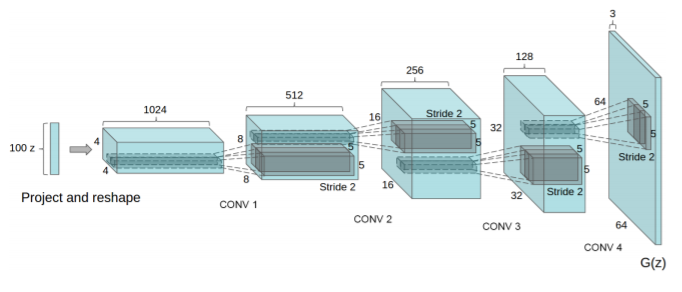
2. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
-
기존의 GAN에 CNN의 네트워크를 도입한 DCGAN 을 제안하였다(Deep Convolutional Generative Adversarial Networks).
-
CNN이 Supervised Learning 에서는 성능이 좋았지만 Unsupervised learning 에서는 많이 쓰이지 않고 있었다. 이때 GAN에 CNN을 적용하여 기존 GAN 보다 훨씬 좋은 성능을 내었고, 이후로부터 많은 발전이 있었다
3. InfoGAN : Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets
-
기존의 GAN은 생성 모델의 input이 z 하나인 것에 비해 InfoGAN은 (z,c)로 input 에 code 라는 latent variable c가 추가된다.
-
그리고 GAN objective에 애드온(add-on)을 하나 붙여서 생성 모델이 학습을 할 때, latent 공간에서 추가로 넣어준 코드 c와 생성된 샘플 사이의 Mutual Information이 높아지도록 도와준다.
-
Mutual information objective 의 lower bound 를 통해 효율적으로 최적화하였다.
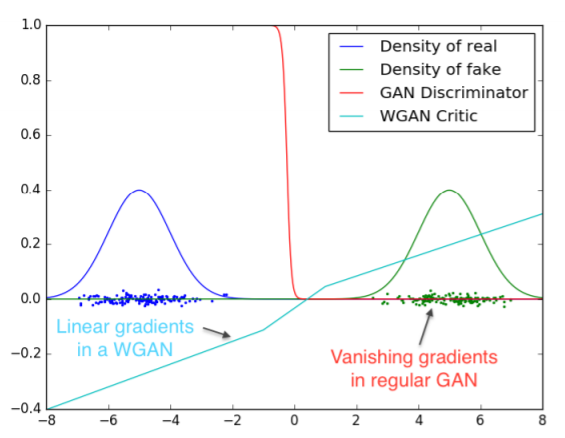
4. WassersteinGAN
-
기존 GAN은 두 분포의 확률적 비교를 위해 KL Divergence 라는 식을 사용하였다. WGAN은 wassetstein distance 를 도입하여 다른 distance와 비교하여 어떤 성질을 가지는지 이론적으로 증명하였다.
-
Discriminator의 함수가 Lipschitz constraint를 만족하게 하여, 결과적으로 gradient가 더 안정적으로 수렴하게 하였다.
5. Improved Training of Wasserstein GANs
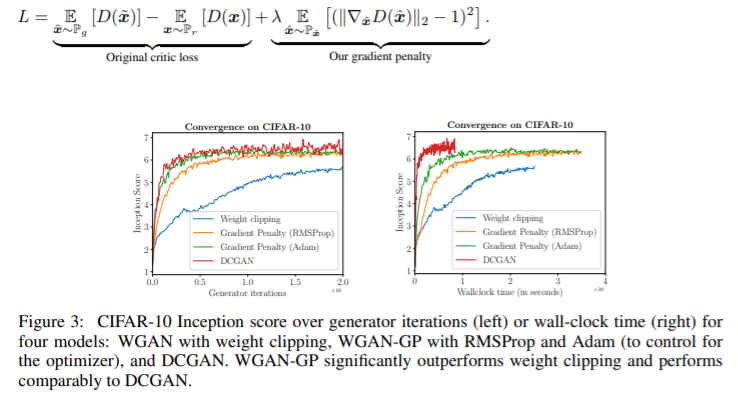
-
WGAN의 경우 안좋은 sample을 생성하거나 수렴에 실패할 경우가 있다.
-
이는 Discriminator의 함수가 Lipschitz constraint를 만족하게 하기 위해 weight clipping을 사용하기 때문인데, 이를 사용하지 않기 위해 input에 대해 critic(Discriminator) 의 gradient norm 을 부과하는 방법을 제시하였다.
6. Least Squares Generative Adversarial Networks
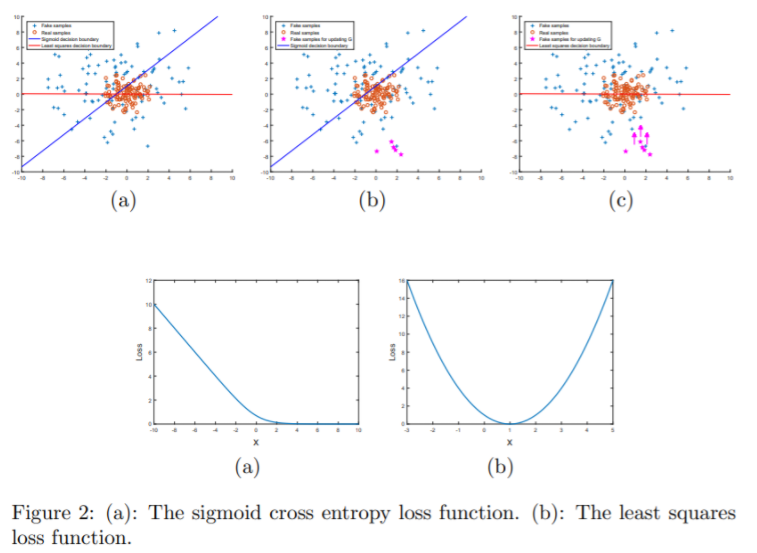
-
기존의 GAN은 sigmoid cross entropy loss function을 가진 discriminator를 classifier로써 가설을 세움 하지만, 이 loss function은 학습 과정 동안 vanishing gradient 문제로 이끌 수 있다.
-
이러한 문제를 극복하기 위해서, discriminator에 least square loss를 적용한 Least Squares Generative Adversarial Networks (LS-GANs)을 제시하였다. LSGAN의 목적함수를 최소화시키는 것은 Pearson divergence를 최소화시키도록 하였다. LSGAN은 기존 GAN 보다 성능이 좋고 안정적으로 학습이 가능하다.
7. Energy-based Generative Adversarial Network
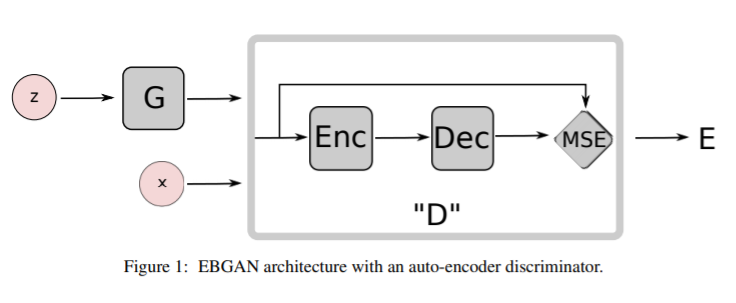
-
Discriminator를 data manifold 근처 지역에는 낮은 에너지, 다른 지역에는 높은 에너지를 부과하는 energy function으로써 보는, Energy-based Generative Adversarial Network를 제안하였다.
-
Generator는 최소한의 에너지를 사용해서 대조적인 이미지를 생성하도록 학습이 되고, discriminator는 이렇게 생성된 샘플들에 대해 높은 에너지를 부과하도록 학습되도록 한다.
-
Discriminator를 energy function으로써 보는 입장은 logistic output이 나오는 binary classifier 뿐만 아니라 다양한 아키텍쳐와 loss function을 사용할 수 있도록 해주었다.
-
Auto-Encoder 구조를 사용하였고, energy는 reconstruction error로 볼 수 있다. EBGAN은 기존 GAN보다 학습 과정에서 더 안정적이며, 더 고화질의 이미지를 생성할 수 있다.
8. BEGAN: Boundary Equilibrium Generative Adversarial Networks
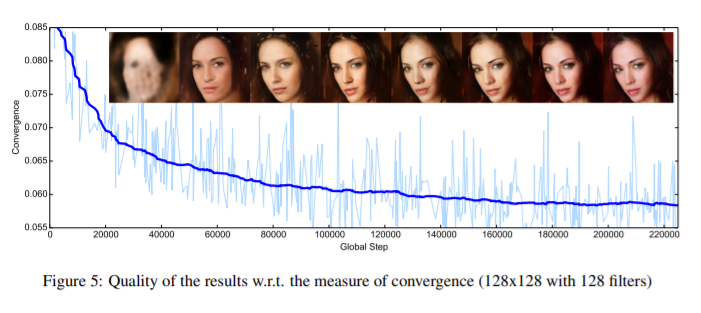
-
Generator와 discriminator를 학습 과정동안 밸런스 시키는 방법을 제안하였다.
-
이 방법은 새로운 대략적인 수렴 측정 방법, 빠르고 안정적인 학습, 더 좋은 이미지 품질을 보여준다.
-
이미지 다양성와 시각적 품질 사이의 trade-off를 조절하는 방법을 유도하였다.
9. Conditional Generative Adversarial Nets
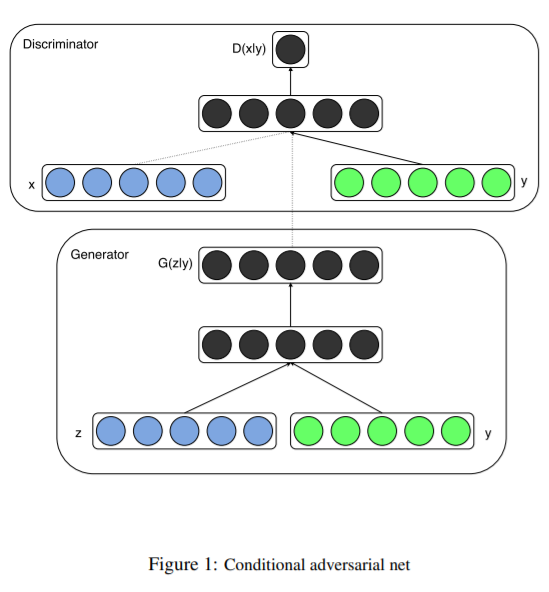
-
Generative model의 conditional 버전을 제안하였다.
-
기존의 GAN이 입력으로 x data만 주었다면, 입력 data로 y도 추가하여 넣어서 generator와 discriminator 모두에 condition을 줄 수 있다.
10. Image-to-Image Translation with Conditional Adversarial Networks (Pix2Pix)
-
입력 이미지와 출력 이미지를 맵핑하는 것을 학습할 뿐만 아니라, 이 맵핑을 train 하기 위한 loss function도 학습을 하였다.
-
CNN에서 사용하는 Euclidean distance를 사용하면 blurry한 결과가 생성되는데, 이는 Euclidean distance는 모든 그럴듯한 결과들의 평균을 최소화하기 때문이다. “실제와 구분하기 어려운 결과를 만들기”라는 high-level 목표에 특정해서 생각하면, 이러한 목표에 만족하는 적절한 loss function을 학습하면 된다.
-
최근에 GAN의 적절한 loss function을 찾기 위한 연구들이 많았고, L2 distance를 많이 사용하였다. CGAN은 L2 distance보다 blurring 이 적은 L1 distance를 사용하였다
11. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
- Image-to-Image translation 방법으로 source domain X로부터 target domain Y로 맵핑하는 함수 G: X→Y와 이에 대한 inverse mapping 함수 F: Y→X를 학습하였다.
- cycle consistency loss는 source domain X의 이미지 x가 함수 G를 거쳐 target domain으로 변형되고 이 이미지가 다시 함수 F를 거쳐서 source domain의 이미지 x로 잘 돌아오는지를 반영하였다.
- 이의 반대 과정 y의 이미지가 함수 F를 거치고 함수 G를 거치고 나서 다시 y로 잘 돌아오는지도 포함되어 있다.
- 결과적으로 CycleGAN은 X domain과 Y domain이 unpaired 되어 있더라도 mapping하는 함수를 학습함으로써 unpaired image translation을 할 수 있다.
12. Semantic Image Synthesis with Spatially-Adaptive Normalization (SPADE, GauGAN)
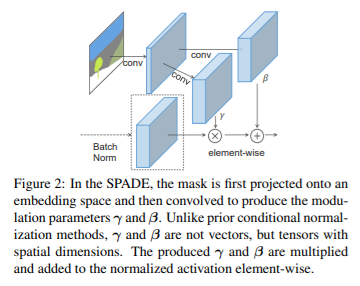
- 입력 semantic layout이 주어졌을 때 photorealistic Spatially-adaptive normalization을 제시하였다.
- 이전의 방법들은 convolution, normalization, nonlinearity layer로 구성되어 있는 네트워크에 semantic layout을 바로 넣었다. 이 경우 normalization 레이어가 시맨틱 정보를 소실시키는 경향이 있다는 것을 보이는데, 이런 문제를 해결하기 위해 spatially-adaptive와 learened trainsformationd을 통해서normalization 레이어들 안의 activation을 조정하기 위한 입력 레이아웃을 사용하였다.
- 결과적으로 SPADE는 시맨틱과 스타일을 모두 컨트롤 할 수 있다.
13. StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation [CVPR 2018]
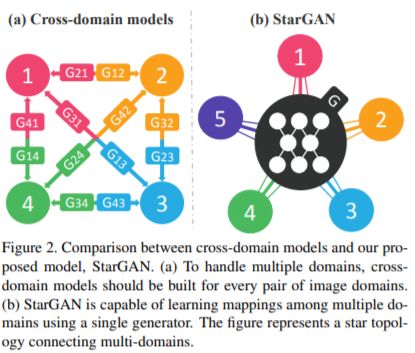
-
기존의 연구들에서 두 개의 도메인의 image-to-image translation의 성공을 보여주었지만, 기존의 접근법들은 두 개 이상의 도메인에 대해 다루기 어렵고, 모든 이미지 도메인의 짝마다 독립적으로 다른 모델들을 생성해야 했다.
-
StarGAN은 이런 한계를 극복하고, 오직 하나의 모델만 가지고 다양한 데이터셋에서 다양한 도메인을 위한 image-to-image translation을 수행할 수 있다.
14. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
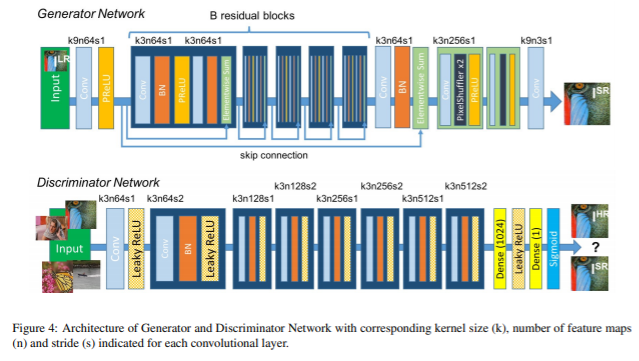
- 기존 이미지 Super-Resolution 문제에서 정확도와 스피드 측면에서 많은 발전을 이루었지만, 질감의 디테일을 어떻게 회복시킬 것인지에 대한 문제가 있었다. Loss로 MSE loss를 사용하는데 PSNR ratio는 높지만 고해상도에서 high-frequency detail이 떨어졌다.
- SRGAN은 이러한 문제를 해결하기 위한 Super Resolution 문제에 대한 GAN 네트워크를 처음 제시하였다.
- adversarial loss와 content loss로 구성되어 있는 perceptual loss를 사용하였다.
15. Spectral Normalization for Generative Adversarial Networks (SNGAN)
- GAN 학습의 불안정성은 GAN의 큰 문제 중 하나이다.
- SNGAN은 Discriminator의 학습을 안정화시키는 방법으로 spectral normalization이라는 방법을 제안하였다.
- WGAN에서는 discriminator의 함수가 Lipschitz constraint를 만족시키도록 하는데, 이를 대체아여 spectral normalization으로 바꾸어 적용하여 기존의 normalization 방법보다 계산이 효율적이며 학습을 안정화시켰다.
16. Self-Attention Generative Adversarial Networks
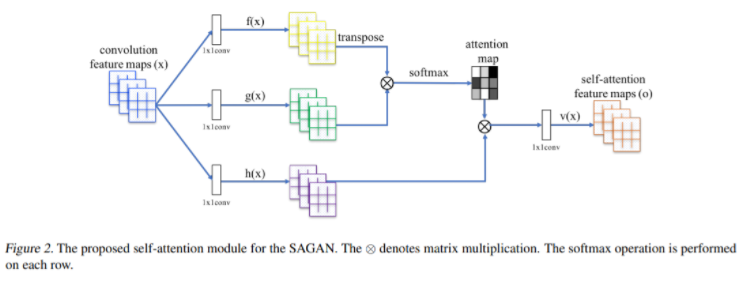
-
GAN의 Self-Attention 개념과 이전 연구에서 제안되었던 Spectral Normalization을 도입하였다.
-
기존의 convolution GAN은 오직 저해상도의 feature map안에서 지역적 정보만을 가지고 고해상도의 디테일을 생성했지만 SAGAN은 모든 feature location으로부터 단서들을 가져와서 이미지를 생성한다.
-
Discriminator는 더 디데일한 feature로 이미지 안에서 먼 지역간의 연속성을 확인할 수 있다.
-
Spectral Normalization을 도입하여 학습을 더 안정적이도록 보완하였다.
17. Large Scale GAN Training for High Fidelity Natural Image Synthesis (BigGAN)
-
GAN에서 고해상도 이미지를 생성하는 것이 성공적이었으나, ImageNet과 같이 복잡한 데이터셋에서 오는 다양한 샘플들로부터 학습하는 것은 아직 남아있는 문제였다.
-
BigGAN은 large scale에 대해서도 학습하도록 하였다.
-
Generator에 orthogonal regularization을 적용하는 것은 간단한 truncation trick을 사용할 수 있도록 하고, fidelity와 variety 간의 trade-off를 control 할 수 있도록 하였다.
-
이전 GAN의 SOTA 성능은 IS가 52.52이고 FID가 18.65였다면, BigGAN은 IS 166.5이고 FID는 7.4로 엄청난 성능 향상을 보여주었다. (IS: Inception Score는 높을 수록 좋고, FID: Fretchet Inception Distance는 낮을 수록 좋다.)
18. Progressive Growing of GANs for Improved Quality, Stability, and Variation (ProgressiveGAN)
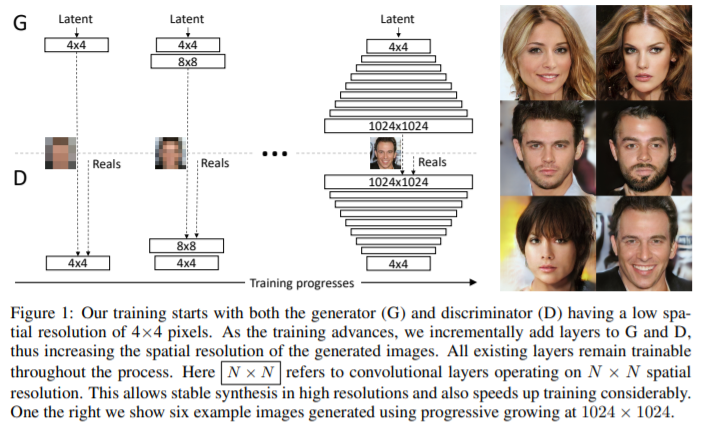
- Generator와 Discriminator를 점진적으로 학습하는 방법이다.
- 저해상도로부터 시작해서, 트레이닝 과정 동안 모델에 새로운 레이어를 추가하면서 디테일을 세밀화 하는 방법으로 학습 속도를 빠르게 하면서 안정화시킬 수 있다.
- 결과적으로 이전보터 훨씬 고해상도의 이미지를 생성할 수 있다.
19. A Style-Based Generator Architecture for Generative Adversarial Networks (StyleGAN)
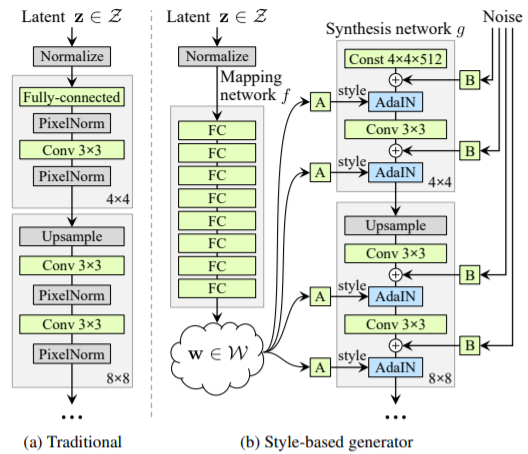
- Generator 네트워크에서 각 레이어마다 스타일 정보를 입히는 방식으로 학습하였다.
- 이미지의 스타일 (성별, 포즈. 머리색, 피부톤 등)을 변경할 수 있다.
- Latent vector z는 특정 데이터셋의 분포를 그대로 따라가는 경향이 있는데, 이를 보완하기 위해서 그대로 사용하는 것이 아니라 Mapping network를 만들어서 나온 w vector를 활용하여 스타일을 더 다양하게 바꿀 수 있도록 하였다.
20. Analyzing and Improving the Image Quality of StyleGAN [StyleGANv2]
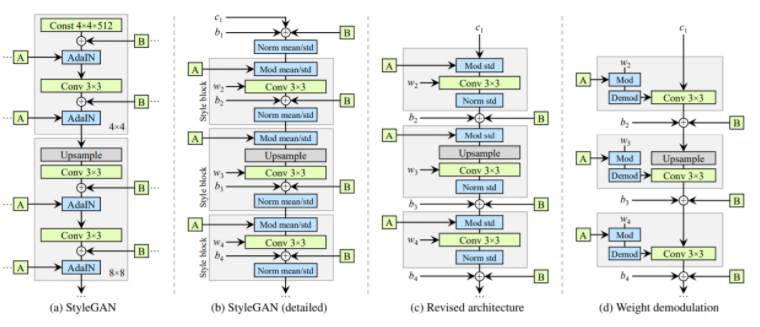
- Latent에서 이미지로 맵핑을 잘 하도록 normalization, regularization, progressivie growing 등을 포함하여 Generator를 재설계하였다.
- StyleGAN에서 이미지를 생성했을 때 원래의 이미지와 관련 없는 이상한 부분이 나오는 경우 (artifact)를 볼 수 있었다.
- 이의 원인을 latent space에서 mapping function을 통하는 AdaIN operation을 할 때 normalization이 문제가 있다고 분석하여 네트워크를 수정하였다.
| 출처 [딥러닝 GAN 튜토리얼 - 시작부터 최신 트렌드까지 GAN 논문 순서 | mocha’s machine learning](https://ysbsb.github.io/gan/2020/06/17/GAN-newbie-guide.html) |