
[Theory] Optimization and Regularization
Optimization
Generalization
우리가 사용하는 모델을 만들때의 목적은 일반화 성능을 높이는 것이 주된 목적이다.
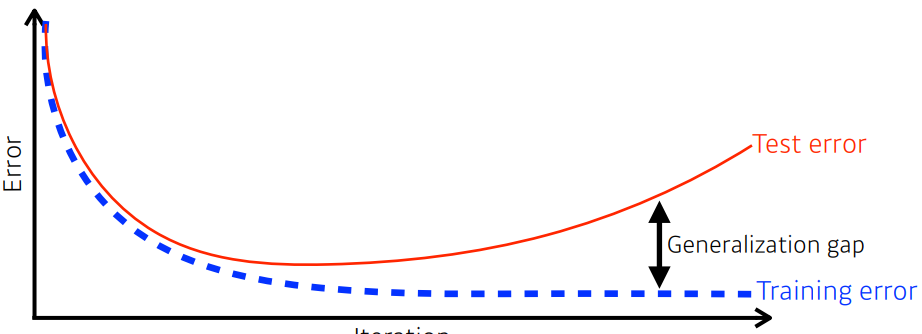
학습 시에는 iteration 증가함에 따라서 training error가 줄어들어 0에 수렴하게 된다
하지만 어느정도 시간이 지나면 내가 train을 수행한 train data에서의 training error와 다르게 test data에서의 test error 는 늘어나게 된다(overfitting 이 원인)
generalization performance : training error와 test error 사이의 차이
- generalization 성능이 좋으면 학습 데이터와 학습데이터가 아닌 데이터에서의 성능이 비슷하게 나올 것이라는 것을 의미
- 하지만 training error와 test error 둘다 낮을 수 있기 때문에 generalization 성능이 높다고 해서 model 의 성능이 높다고 할 수는 없다.
Cross validation
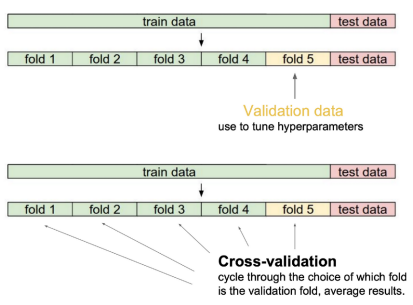
- K-fold validation 이라고도 불린다
- train dataset과 validation dataset 의 비율의 문제를 해결하고자 하였다
- 전체 데이터를 k개(fold)로 나누어 k-1 개의 fold로 학습을 시키고 나머지 1개로 validation을 해보는 방법
- 최적의 hyperparameter 을 찾기 위해 cross validation을 사용하여 찾은 후, hyperparameter 를 고정시킨 뒤 더 많은 데이터를 사용하여 학습을 진행한다
- test data는 학습에 어떠한 관여도 하면 안된다
Bias and variance
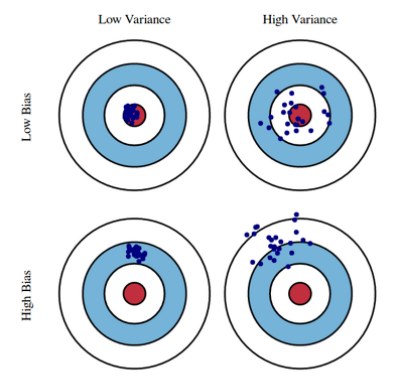
- Bias : 비슷한 입력을 넣었을 때 출력이 분산되더라도 평균적으로 ground truth 에서 얼마나 벗어났는지
- Variance : 비슷한 입력을 넣었을 때 출력이 얼마나 일관적으로 나오는지
Bias and Variance Traodeoff
내 학습 데이터에 noise가 껴 있다고 가정 했을 때, 2norm 기준으로 noise가 낀 target data를 최소화 하는 것은 3가지 part(bias,variance,noise)로 나누어진다.
minimize 하는 것은 하나의 target data지만 3가지의 conference로 이루어져 있어 각각을 minimize 하는것이 아니라 하나를 줄이면 다른것들이 커지는 tradeoff 를 설명한다
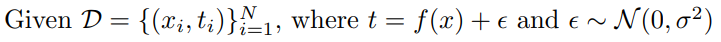
- t : target
- f hat : neural network 출력값
여기서는 t에 noise가 꼈다고 가정
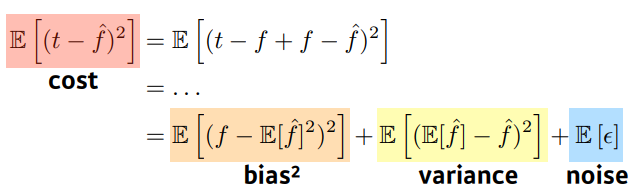
bias , variance , noise 3개를 같이 줄이기는 힘들다는 fundamental한 limitation을 나타낸다
Bootstrapping
학습 데이터가 고정되어있을 때 subsampling 을 통해 여러 model 을 만들어 관찰
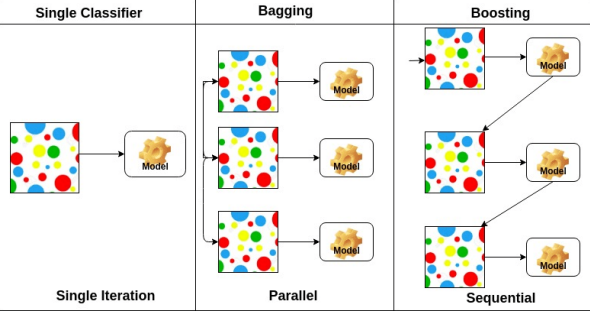
Bagging(ensemble)
Bootstrapping aggregating
학습 데이터를 여러개를 만들어 여러 model을 만들고, output을 평균을 내는 방법
Boosting
학습 데이터를 sequential 하게 바라보고 학습을 진행 한 뒤, 학습이 잘 되지 않은 data를 학습하는 2번쨰 model(weak learner)을 만드는 방법으로 반복하여, 합치는 방법
독립적인 model로 보고 n개의 결과를 뽑는게 아니라. weak learner 를 여러개를 만들어 sequential 하게 합치는 방법으로 하나의 strong learner 를 만드는 방법
Practical Gradient Descent Methods
- Stochastic gradient descent
- 여러개의 sample 이 아닌 하나의 sample 을 가지고 gradient 를 update 하는 방법
- Mini-batch gradient descent
- batch size 만큼의 data를 보고 gradient 를 update 하는 방법
- Batch gradient descent
- 한번에 data 전부 사용하여 평균을 가지고 gradient를 update 하는 방법
Batch siae matters
On large-batch Training for Deep Learning : Generalization Gap and Sharp Minima(2017)
-
큰 batch size 를 활용하면 sharp minimizer 라는 것에 도달하게 된다
-
작은 batch size 를 활용하면 flat minimizer 라는 것에 도달하게 된다
이 논문에선는 실험적 결과로 sharp minimizer 보다는 flat minimizer 라는 것이 더 좋다, 즉 작은 batch size 를 쓰는것이 더 좋다고 설명하고 있다
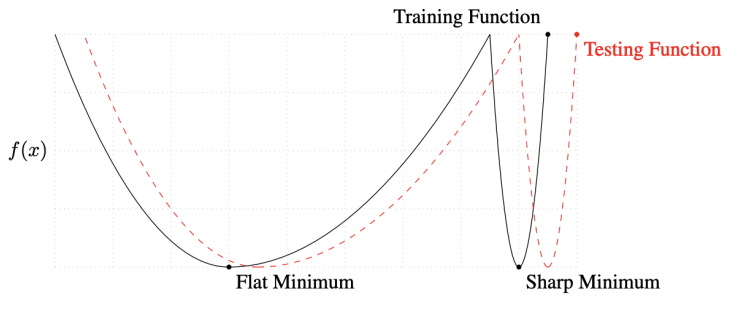
model 의 목적은 Test function 에서의 minimum 을 찾고 싶은 거지, Training function 에서의 minimun을 찾고싶은게 아니다.
Flat minimum
training function 에서 조금 멀어져도, test function 에서도 적당히 낮은값이 나온다 : Generalization performance 좋다
Sharp minimum
Training function 에서는 낮지만, Testing function 에서는 제대로 일을 하지 못한다 : Generalization performance 나쁘다
Gradient Descent Methods
Gradient descent
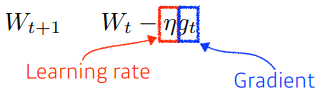
미분한 gradient 에 learning rate 를 곱하여 차이를 가중치에 update
Problems
- Learning rate를 잡는것이 어렵다
Momentum
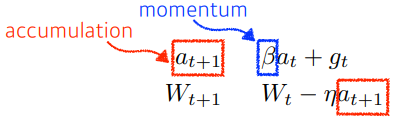
한번 gradient 흐른 방향대로 다음 gradient에서 방향 정보를 이용한 방법
problems
- local minimum 에 잘 못빠지기 떄문에 converge가 잘 안되는 경향이 있다
Nesterov Accelerate
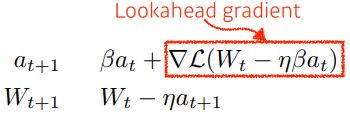
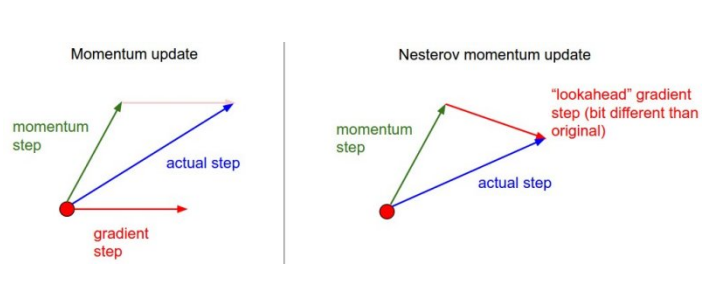
gradient 계산 시 Lookahead gradient 를 계산하게 된다
현재 주어진 parameter 에서 gradient 계산해서 다음 정보로 한번 이동하여 한번 더 gradient 계산 뒤 accumulation
momentum 처럼 gradient 계산 시 방향성을 가지고 흘러가는 것이 아니라 한번 지나간 곳에서 gradient 계산하기 때문에 빨리 converge 하는 효과가 생기게 된다
Adagrad
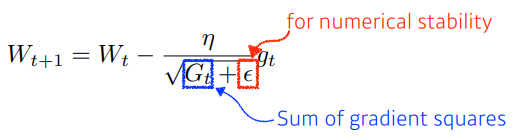
train 동안 gradient 가 얼마나 변해왔는지를 보게 된다
G : 지금까지 gradient 가 얼마나 많이 변했는지를 제곱하여 더한 값
problems
- G 가 무한대로 커지기 떄문에 학습이 진행될수록 훕나에는 학습이 잘 되지 않는다
Adadelta
Adagrad 의 문제를 해결하기 위해 window size 를 설정하여 시간축으로 얼마만큼의 gradient 를 볼지 정하고, exponential moving average 를 통해 parameter 가 많이 쌓였을때의 해결책을 제시하였다
problems
- earning rate 가 없기 때문에 많이 활용되지 않는다
RMSprop
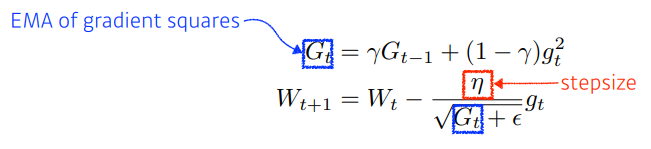
gradient squares 를 그냥 더하지 않고 EMA를 더해준다. 이를 분모에 넣고 stepsize 를 넣어주었다
Adam
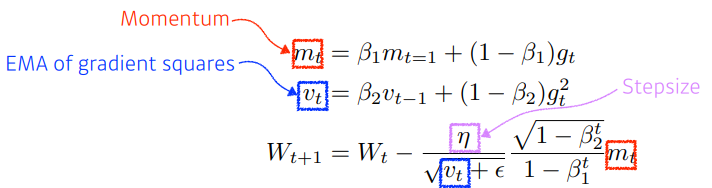
가장 무난하게 사용
gradient square 에 exponential moving average 를 가져감과 동시에, momentum 을 같이 활용하는 방법
division by zero 를 막아주는 epsilon parameter 를 잘 설정해주는것이 중요하다
Regularization Methods
Early stopping
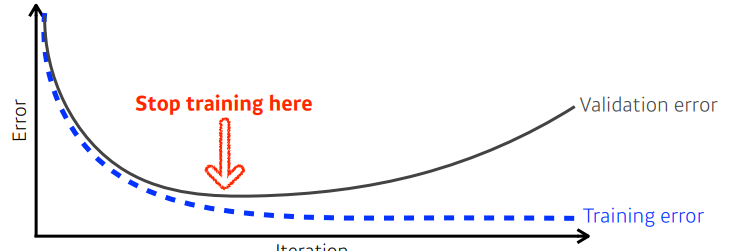
generalization 이 잘되었을 때 학습을 일찍 종료
Parameter Norm Penalty(weight decay)

Neural Network parameter 가 너무 커지지 않게 하는 방법
parameter 를 전부 더한 값을 같이 줄인다
function space 에서 함수를 최대한 부드럽게 해준다(특정 값만 크게 하지 않음)
Data Augmentation
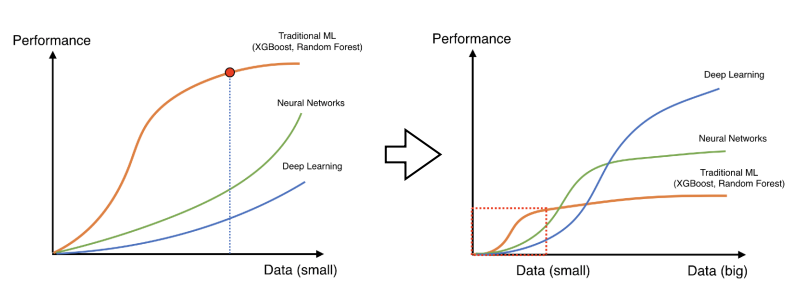
data 적을 떄는 random forest, SVM 같은 방식이 더 잘 되었었다
data가 많아지면 ML에서 활용하는 방법들이 많은 수의 data를 표현할만한 표현력이 부족해진다
하지만 data 가 한정적이므로 data를 변환하여 늘려준다
Noise Robustness

입력 data와 weight에 noise 를 추가하는 방법
Label Smoothing
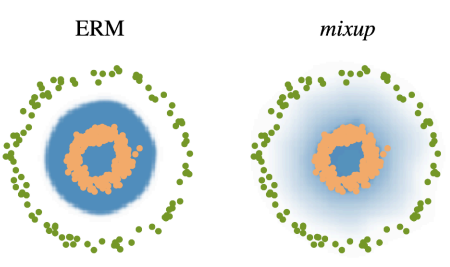

data 2개를 뽑아 섞어준다
classification 는 이미지 공간에서 decision boundary 를 찾는 task인데 이 decision boundary를 부드럽게 해준다
data, label을 함께 섞어준다
Dropout
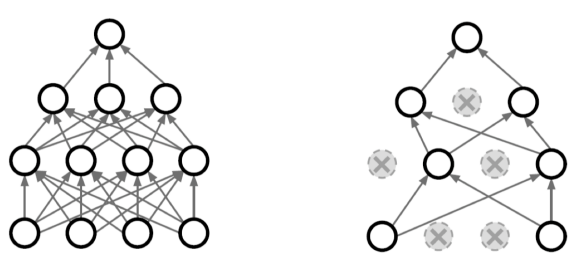
몇개의 Neural network 의 weight을 확률적(p)으로 0으로 만드는 방법
Batch Normalization
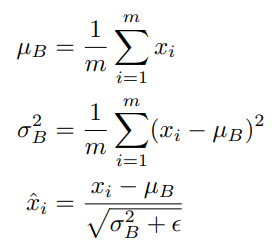
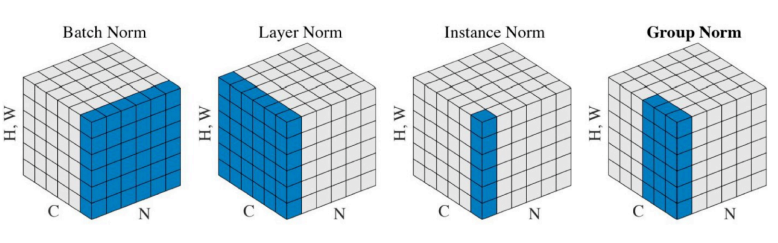
layer 의 statistics 를 평균을 빼고 표준편차로 나누어 정규화 시키는 방법
BN vs Dropout
보통 model 을 만드 때 batch_size 가 32 이하이면 BN 대신 Dropout 을 쓰는 것이 효과적이라고 한다.
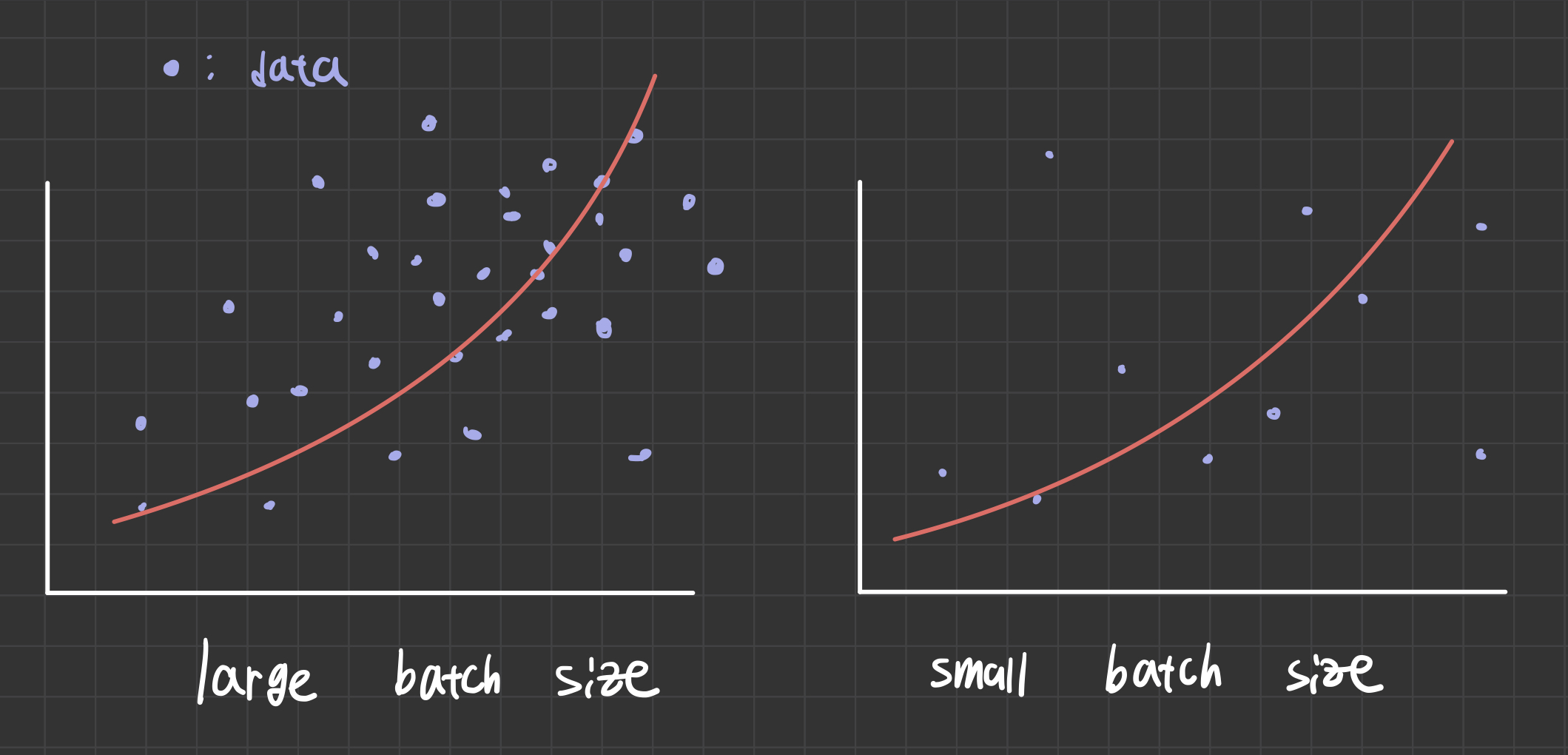
small batch-size 의 경우 보는 데이터가 적기 때문에, layer 의 weight 를 정규화 하는 방법 보다는 아예 layer 를 없애는 방법이 더욱 효과적이다
large batch-size 의 경우에는 보는 데이터가 많기 때문에, dropout 의 효과 보다는 batch normalization 의 효과가 더 크기 때문에 batch-size 가 작으면 Dropout 이 더욱 효과적이다